Аккуратное размыкание соединений
Теперь, когда вы познакомились с вызовом shutdown, посмотрите, как его можно использовать для аккуратного размыкания соединения. Цель этой операции гарантировать, что обе стороны получат все предназначенные им данные до того, соединение будет разорвано.
Примечание: Термин «аккуратное размыкание» (orderly release) имеет некоторое отношение к команде t_sndrel из APIXTI (совет 5), которую также часто называют аккуратным размыканием в отличие от команды грубого размыкания (abortive release) t_snddis. Но путать их не стоит. Команда t_sndrel выполняет те же действия, что и shutdown. Обе команды используются для аккуратного размыкания соединения.
Просто закрыть соединение в некоторых случаях недостаточно, поскольку могут быть потеряны еще не принятые данные. Помните, что, когда приложение закрывает соединение, недоставленные данные отбрасываются.
Чтобы поэкспериментировать с аккуратным размыканием, запрограммируйте клиент, который посылает серверу данные, а затем читает и печатает ответ сервера. Текст программы приведен в листинге 3.1. Клиент читает из стандартного входа данные для отправки серверу. Как только f gets вернет NULL, индицирующий конец файла, клиент начинает процедуру разрыва соединения. Параметр –с в командной строке управляет этим процессом. Если -с не задан, то программа shutdownc вызывает shutdown для закрытия передающего конца соединения. Если же параметр задан, то shutdownc вызывает CLOSE, затем пять секунд «спит» и завершает сеанс.
Листинг 3.1. Клиент для экспериментов с аккуратным размыканием
shutdownc.c
1 #include "etcp.h"
2 int main( int argc, char **argv )
3 {
4 SOCKET s;
5 fd_set readmask;
6 fd_set allreads;
7 int re;
8 int len;
9 int c;
10 int closeit = FALSE;
11 int err = FALSE;
12 char lin[ 1024 ];
13 char lout[ 1024 ];
14 INIT();
15 opterr = FALSE;
16 while ( ( с = getopt( argc, argv, "c" ) ) != EOF )
17 {
18 switch( с )
19 {
20 case 'c' :
21 closeit = TRUE;
22 break;
23 case '?' :
24 err = TRUE;
25 }
26 }
27 if ( err argc - optind != 2 )
28 error( 1, 0, "Порядок вызова: %s [-с] хост порт\n",
29 program_name );
30 s = tcp_client( argv[ optind ], argv[ optind + 1 ] );
31 FD_ZERO( &allreads );
32 FD_SET( 0, &allreads ) ;
33 FD_SET( s, &allreads ) ;
34 for ( ; ; )
35 {
36 readmask = allreads;
37 re = select) s + 1, &readmask, NULL, NULL, NULL );
38 if ( re <= 0 )
39 error( 1, errno, "ошибка: select вернул (%d)", re );
40 if ( FD_ISSET( s, &readmask ) )
41 {
42 re = recv( s, lin, sizeof( lin ) - 1, 0 );
43 if ( re < 0 )
44 error( 1, errno, "ошибка вызова recv" );
45 if ( re == 0 )
46 error( 1, 0, "сервер отсоединился\п" ) ;
47 lin[ re ] = '\0';
48 if ( fputs( lin, stdout ) == EOF )
49 error( 1, errno, "ошибка вызова fputs" );
50 }
51 if ( FD_ISSET( 0, &readmask ) )
52 {
53 if ( fgets( lout, sizeof( lout ), stdin ) == NULL )
54 {
55 FD_CLR( 0, &allreads ) ;
56 if ( closeit )
57 {
58 CLOSE( s );
59 sleep( 5 ) ;
60 EXIT( 0 ) ;
61 }
62 else if ( shutdown( s, 1 ) )
63 error( 1, errno, "ошибка вызова shutdown" );
64 }
65 else
66 {
67 len = strlent lout );
68 re = send( s, lout, len, 0 );
69 if ( re < 0 )
70 error( 1, errno, "ошибка вызова send" );
71 }
72 }
73 }
74 }
Инициализация.
14- 30 Выполняем обычную инициализацию клиента и проверяем, есть ли в командной строке флаг -с.
Обработка данных.
40-50 Если в ТСР-сокете есть данные для чтения, программа пытается прочитать, сколько можно, но не более, чем помещается в буфер. При получении признака конца файла или ошибки завершаем сеанс, в противном случае выводим все прочитанное на stdout.
Примечание: Обратите внимание на конструкцию sizeof ( lin ) -1 в вызове recv на строке 42. Вопреки всем призывам избегать переполнения буфера, высказанным в совете 11, в первоначальной версии этой программы было написано sizeof ( lin ), что приведет к записи за границей буфера в операторе
lin[ re ] = '\0';
в строке 47.
53-64 Прочитав из стандартного входа EOF, вызываем либо shutdown, либо CLOSE в зависимости от наличия флага -с.
65- 71 В противном случае передаем прочитанные данные серверу.
Можно было бы вместе с этим клиентом использовать стандартный системным сервис эхо-контроля, но, чтобы увидеть возможные ошибки и ввести некоторую задержку, напишите собственную версию эхо-сервера. Ничего особенного в программе tcpecho.с нет. Она только распознает дополнительный аргумент в командной строке, при наличии которого программа «спит» указанное число секунд между чтением и записью каждого блока данных (листинг 3.2).
Сначала запустим клиент shutdownc с флагом -с, чтобы он закрывал сокет после считывания EOF из стандартного ввода. Поставим в сервере tcpecho задержку на 4 с перед отправкой назад только прочитанных данных:
bsd: $ tcpecho 9000 4 &
[1] 3836
bsd: $ shutdownc –c localhost 9000
data1 Эти три строки были введены подряд максимально быстро
data2
^D
tcpecho: ошибка вызова send: Broken pipe (32) Спустя 4 с после отправки “data1”.
Листинг3.2. Эхо-сервер на базе TCP
tcpecho.c
1 #include "etcp.h"
2 int main( int argc, char **argv)
3 {
4 SOCKET s;
5 SOCKET s1;
6 char buf[ 1024 ];
7 int re;
8 int nap = 0;
9 INIT();
10 if ( argc == 3 )
11 nap = atoi( argv[ 2 ] ) ;
12 s = tcp_server( NULL, argv[ 1 ] );
13 s1 = accept( s, NULL, NULL );
14 if ( !isvalidsock( s1 ) )
15 error( 1, errno, "ошибка вызова accept" );
16 signal( SIGPIPE, SIG_IGN ); /* Игнорировать сигнал SIGPIPE.*/
17 for ( ; ; )
18 {
19 re = recv( s1, buf, sizeof( buf ), 0 );
20 if ( re == 0 )
21 error( 1, 0, "клиент отсоединился\n" );
22 if ( re < 0 )
23 error( 1, errno, "ошибка вызова recv" );
24 if ( nap )
25 sleep( nap ) ;
26 re = send( s1, buf, re, 0 );
27 if ( re < 0 )
28 error( 1, errno, "ошибка вызова send" );
29 }
30 }
Затем нужно напечатать две строки datal и data2 и сразу вслед за ними нажать комбинацию клавиш Ctrl+D, чтобы послать программе shutdownc конец файла и вынудить ее закрыть сокет. Заметьте, что сервер не вернул ни одной строки. В напечатанном сообщении tcpecho об ошибке говорится, что произошло. Когда сервер вернулся из вызова sleep и попытался отослать назад строку datal, он получил RST, поскольку клиент уже закрыл соединение.
Примечание: Как объяснялось в совете 9, ошибка возвращается при записи второй строки (data2). Заметьте, что это один из немногих случаев, когда ошибку возвращает операция записи, а не чтения. Подробнее об этом рассказано в совете 15.
В чем суть проблемы? Хотя клиент сообщил серверу о том, что больше не будет посылать данные, но соединение разорвал до того, как сервер успел завершить обработку, в результате информация была потеряна. В левой половине рис. 3.2 показано, как происходил обмен сегментами.
Теперь повторим эксперимент, но на этот раз запустим shutdownc без флага -с.
bsd: $ tcpecho 9000 4 &
[1] 3845
bsd: $ shutdownc localhost 9000
datal
data2
^D
datal Спустя 4 с после отправки "datal".
data2 Спустя 4 с после получения "datal".
tcpecho: клиент отсоединился
shutdownc: сервер отсоединился
На этот раз все сработало правильно. Прочитав из стандартного входа признак конца файла, shutdownc вызывает shutdown, сообщая серверу, что он больше не будет ничего посылать, но продолжает читать данные из соединения. Когда сервер tcpecho обнаруживает EOF, посланный клиентом, он закрывает соединение, в результате чего TCP посылает все оставшиеся в очереди данные, а вместе с ними FIN. Клиент, получив EOF, определяет, что сервер отправил все, что у него было, и завершает сеанс.
Заметьте, что у сервера нет информации, какую операцию (shutdown или close) выполнит клиент, пока не попытается писать в сокет и не получит код ошибки или EOF. Как видно из рис. 3.1, оба конца обмениваются теми же сегментами, что и раньше, до того, как TCP клиента ответил на сегмент, содержащий строку datal.
Стоит отметить еще один момент. В примерах вы несколько раз видели, что, когда TCP получает от хоста на другом конце сегмент FIN, он сообщает об этом приложению, возвращая нуль из операции чтения. Примеры приводятся в строке 45 листинга 3.1 и в строке 20 листинга 3.2, где путем сравнения кода возврата recv с нулем проверяется, получен ли EOF. Часто возникает путаница, когда в ситуации, подобной той, что показана в листинге 3.1, используется системный вызов select. Когда приложение на другом конце закрывает отправляющую сторону соединения, вызывая close или shutdown либо просто завершая работу, select возвращает управление, сообщая, что в сокете есть данные для чтения. Если приложение при этом не проверяет EOF, то оно может попытаться обработать сегмент нулевой длины или зациклиться, переключаясь между вызовами read и select.
В сетевых конференциях часто отмечают, что «select свидетельствует о наличии информации для чтения, но в действительности ничего не оказывается». В действительности хост на другом конце просто закрыл, как минимум, отправляющую сторону соединения, и данные, о присутствии которых говорит select, -это всего лишь признак конца файла.
Активные сокеты
Во-первых, можно получить сведения об активных сокетах. Хотя netstat дает информацию о разных типах сокетов, интерес представляют только сокеты из адресных доменов inet (AF_INET) и UNIX (AF_LOCAL или AF_UNIX). Можно потребовать вывести все типы сокетов или выбрать один тип, указав адресное семейство с помощью опции -f.
По умолчанию серверы, сокеты которых привязаны к адресу INADDR_ANY, не выводятся, но этот режим можно отключить с помощью опции -а. Например, если нужны TCP/UDP-сокеты, то можно вызвать netstat так:
bsd: $ netstat -f inet
Active Internet connections
Proto Recv-Q Send-Q Local Address Foreign Address (state)
tcp 0 0 localhost.domain *.* LISTEN
tcp 0 0 bsd.domain *.* LISTEN
udp 0 0 localhost.domain *.*
udp 0 0 bsd.domain *.*
bsd: $
Здесь показан только сервер доменных имен (named), работающий на машине bsd. Если же нужно вывести все серверы, то программа запускается таким образом:
bsd: $ netstat -af inet
Active Internet connections
Proto Recv-Q Send-Q Local Address Foreign Address (state)
tcp 0 0 *.6000 *.* LISTEN
tcp 0 0 *.smtp *.* LISTEN
tcp 0 0 *.printer *.* LISTEN
tcp 0 0 *.rlnum *.* LISTEN
tcp 0 0 *.tcpmux *.* LISTEN
tcp 0 0 *.chargen *.* LISTEN
tcp 0 0 *.discard *.* LISTEN
tcp 0 0 *.echo *.* LISTEN
tcp 0 0 *.time *.* LISTEN
tcp 0 0 *.daytime *.* LISTEN
tcp 0 0 *.finger *.* LISTEN
tcp 0 0 *.login *.* LISTEN
tcp 0 0 *.cmd *.* LISTEN
tcp 0 0 *.telnet *.* LISTEN
tcp 0 0 *.ftp *.* LISTEN
tcp 0 0 *.1022 *.* LISTEN
tcpяяяя 0яяя 0яяяяя *.2049яяяяяяяяяяя *.*яяяяяя LISTEN
tcpяяяя 0яяя 0яяяяя *.1023яяяяяяяяяяя *.*яяяяяя LISTEN
tcpяяяя 0яяя 0яяяяя localhost.domainя *.*яяяяяя LISTEN
tcpяяяя 0яяя 0яяяяя bsd.domainяяяяяяя *.*яяяяяя LISTEN
udpяяяя 0яяя 0яяяяя *.udpechoяяяяяяяя *.*
udpяяяя 0яяя 0яяяяя *.chargenяяяяяяяя *.*
udpяяяя 0яяя 0яяяяя *.discardяяяяяяяя *.*
udpяяяя 0яяя 0яяяяя *.echoяяяяяяяяяяя *.*
udpяяяя 0яяя 0яяяяя *.timeяяяяяяяяяяя *.*
udpяяяя 0яяя 0яяяяя *.ntalkяяяяяяяяяя *.*
udpяяяя 0яяя 0яяяяя *.biffяяяяяяяяяяя *.*
udpяяяя 0яяя 0яяяяя *.1011яяяяяяяяяяя *.*
udpяяяя 0яяя 0яяяяя *.nfsdяяяяяяяяяяя *.*
udpяяяя 0яяя 0яяяяя *.1023яяяяяяяяяяя *.*
udpяяяя 0яяя 0яяяяя *. sunrpcяяяяяяяя *.*
udpяяяя 0яяя 0яяяяя *.1024яяяяяяяяяяя *.*
udpяяяя 0яяя 0яяяяя localhost. Domain *.*
udpяяяя 0яяя 0яяяяя bsd. domainяяяяяя *.*
udpяяяя 0яяя 0яяяяя *.syslogяяяяяяяяя *.*
bsd:яяя $
…б«Ё Ўл ўл § ЇгбвЁ«Ё Їа®Ја ¬¬г lsof (б®ўҐв 37), в® ®Ў аг¦Ё«Ё, зв® Ў®«м-йЁбвў® нвЁе <бҐаўҐа®ў> - ў ¤Ґ©б⢨⥫м®бвЁ inetd (б®ўҐв 17), ®¦Ё¤ ойЁ© ЏаЁе®¤ ᮥ¤ЁҐЁ© Ё«Ё ¤ в Ја ¬¬ ў Ї®авл бв ¤ авле бҐаўЁб®ў. ‘«®ў®
…б«Ё ®Ўа вЁвмбп Є бҐаўҐаг не®-Є®ва®«п б Ї®¬®ймо telnet:
bbd: $ telnet bsd echo
в® Ї®пўЁвбп ᮥ¤ЁҐЁҐ ў б®бв®пЁЁ ESTABLISHED:
Proto Recv-Q Send-Q Local Address Foreign Address (state)
tcpяяяяяяяяяя 0яяяяя 0яяя bsd.echoяяяяя bsd.1035яяяя ESTABLISHED
tcpяяяяяяяяяя 0яяяяя 0яяя bsd.1035яяяяя bsd.echoяяяя ESTABLISHED
tTcpяяяяяяя 0яяяяя 0яяя *.echoяяяяяяя *.*яяяяяяяяя LISTEN
‡¤Ґбм ®ЇгйҐл бва®ЄЁ, Ґ ®в®бпйЁҐбп Є бҐаўҐаг не®-Є®ва®«п. ЋЎа вЁвҐ ўЁ¬ ЁҐ, зв®, Ї®бЄ®«мЄг ўл ᮥ¤ЁЁ«Ёбм б «®Є «м®© ¬ иЁ®©, ў ўл¤ зҐ netstat ᮥ¤ЁҐЁҐ ЇаЁбгвбвўгҐв ¤ў ¦¤л: ®¤Ё а § ¤«п Є«ЁҐв , ¤агЈ®© - ¤«п бҐаўҐа . ‡ ¬Ґвм⥠⠪¦Ґ, зв® inetd Їа®¤®«¦ Ґв Їа®б«гиЁў вм Ї®ав ў ®¦Ё¤ ЁЁ ¤ «мҐ©иЁе ᮥ¤ЁҐЁ©.
ЏаЁ¬Ґз ЁҐ: Џ®б«Ґ¤ҐҐ § ¬Ґз ЁҐ вॡгҐв ҐйҐ ҐбЄ®«мЄЁе Ї®пᥨ©. •®вп telnet-Є«ЁҐв Ї®¤б®Ґ¤ЁЁ«бп Є Ї®авг 7 (Ї®ав не®) Ё д ЄвЁзҐбЄЁ ЁбЇ®«м§гҐв ҐЈ® ў Є зҐб⢥ Ї®ав § 票п, е®б⠯த®«¦ Ґв Їа®б«гиЁў вм нв®в Ї®ав. ќв® ®а¬ «м®, в Є Є Є б в®зЄЁ §аҐЁп TCP ᮥ¤ЁҐЁҐ - нв® зҐвўҐаЄ , б®бв®пй п Ё§ «®Є «мле IP- ¤аҐб Ё Ї®ав Ё г¤ «Ґле IP- ¤аҐб Ё Ї®ав (б®ўҐв 23). Љ Є ўЁ¤ЁвҐ, inetd Їа®б«гиЁў Ґв Ї®ав гЁўҐаб «м®¬ <ЇбҐў¤® ¤аҐбҐ> INADDR_ANY, зв® Ї®Є § ® §ўҐ§¤®зЄ®© ў Є®«®ЄҐ LocalAddress, в®Ј¤ Є Є IP- ¤аҐб ¤«п гбв ®ў«Ґ®Ј® ᮥ¤ЁҐЁп а ўҐ bsd. …б«Ё Ўл, ўл ᮧ¤ «Ё ®¤® ¤®Ї®«ЁвҐ«м®Ґ ᮥ¤ЁҐЁҐ б Ї®¬®ймо telnet, в® Ї®«гзЁ«Ё Ўл ҐйҐ ¤ўҐ бва®ЄЁ, «®ЈЁз륯Ґаўл¬ ¤ўг¬, в®«мЄ® Ї®ав Є«ЁҐв Ўл« Ўл ®в«ЁзҐ ®в 1035.
‡ ўҐаиЁвҐ а Ў®вг Є«ЁҐв Ё б®ў § ЇгбвЁвҐ netstat. ‚®в зв® ўл Ї®«гзЁвҐ:
Proto Recv-Q Send-Q Local Address Foreign Address (state)
tcpяяя 0яяяяя 0яяя bsd.1035яяяяя bsd.echoяяяяя TIME_WAIT
Љ Є ўЁ¤®, Є«ЁҐвбЄ п бв®а® ᮥ¤ЁҐЁп 室Ёвбп ў б®бв®пЁЁ TIME-WAIT (б®ўҐв 22). ‚ Є®«®ЄҐ state ¬®Јгв Ї®пў«пвмбп Ё ¤агЈЁҐ б®бв®пЁп, Ї®¤а®ЎҐҐ 0 Ёе а ббЄ §лў Ґвбп ў RFC 793 [Postel 1981b].
Архитектура клиент-сервер
Хотя постоянно говорится о клиентах и серверах, не всегда очевидно, какую роль играет конкретная программа. Иногда программы являются равноправными участниками обмена информацией, нельзя однозначно утверждать, что одна программа обслуживает другую. Однако в случае с TCP/IP различие более четкое. А Сервер прослушивает порт, чтобы обнаружить входящие TCP-соединения или UDP-датаграммы от одного или нескольких клиентов. С другой стороны, можно сказать, что клиент - это тот, кто начинает диалог первым.
В книге рассмотрены три типичных случая архитектуры клиент-сервер, показанные на рис. 1.1. В первом случае клиент и сервер работают на одной машине (рис 1.la). Это самая простая конфигурация, поскольку нет физической сети. Посылаемые данные, передаются стеку TCP/IP, но не помещаются в выходную очередь сетевого устройства, а закольцовываются системой и возвращаются обратно стек, но уже в качестве принятых данных.

Рис. 1.1. Типичные примеры архитектуры клиент - сервер
На этапе разработки такое размещение клиента и сервера дает определенные преимущества, даже если в реальности они будут работать на разных машинах. Во - первых, проще оценить производительность обеих программ, так как сетевые задержки исключаются. Во-вторых, этот метод создает идеальную лабораторную среду, в которой пакеты не пропадают, не задерживаются и всегда приходят в правильном порядке.
Примечание: По крайней мере, почти всегда. Как вы увидите в совете 7, даже в этой среде можно создать такую нагрузку, что UDP-датаграммы будут пропадать.
И, наконец, разработку вести проще и удобнее, когда можно все отлаживать на одной машине.
Разумеется, даже в условиях промышленной эксплуатации вполне возможно, клиент и сервер будут работать на одном компьютере. В совете 26 описана такая ситуация.
Во втором примере конфигурации (рис. 1.1б) клиент и сервер работают на разных машинах, но в пределах одной локальной сети. Здесь имеет место реальная сеть, но условия все же близки к идеальным. Пакеты редко теряются и практически всегда приходят в правильном порядке. Такая ситуация очень часто встречается на практике. Причем некоторые приложения предназначены для работы только в такой среде.
Типичный пример - сервер печати. В небольшой локальной сети может быть только один такой сервер, обслуживающий несколько машин. Одна машина (или сетевое программное обеспечение на базе TCP/IP, встроенное в принтер) выступает в роли сервера, который принимает запросы на печать от клиентов на других машинах и ставит их в очередь к принтеру.
В третьем примере (рис. 1.1в) клиент и сервер работают на разных компьютерах, связанных глобальной сетью. Этой сетью может быть Internet или корпоративная Intranet, но главное - приложения уже не находятся внутри одной локальной сети, так что на пути IP-датаграмм есть, по крайней мере, один маршрутизатор.
Такое окружение может быть более «враждебным», чем в первых двух случаях. По мере роста трафика в глобальной сети начинают переполняться очереди, в которых маршрутизатор временно хранит поступающие пакеты, пока не отправит их адресату. А когда в очереди больше нет места, маршрутизатор отбрасывает пакеты. В результате клиент должен передавать пакеты повторно, что приводит к появлению дубликатов и доставке пакетов в неправильном порядке. Эти проблемы возникают довольно часто, как вы увидите в совете 38.
О различиях между локальными и глобальными сетями будет рассказано в совете 12.
Архитектура с двумя соединениями
Процессы xin и xout на рис. 3.4 делят между собой единственное соединение с внешней системой, но возникают трудности при организации разделения информации о состоянии этого соединения. Кроме того, с точки зрения каждого из процессов xin и xout, это соединение симплексное, то есть данные передаются по Нему только в одном направлении. Если бы это было не так, то xout «похищал» бы входные данные у xin, a xin мог бы исказить данные, посылаемые xout.
Решение состоит в том, чтобы завести два соединения с внешней системой -по одному для xin и xout. Полученная после такого изменения архитектура изображена на рис. 3.5.

Рис.3.5. Приложение, обменивающееся сообщениями по двум TCP-соединениям
Если система не требует отправки подтверждений на прикладном уровне, то при такой архитектуре выигрывает процесс xout, который теперь имеет возможность самостоятельно узнавать об ошибках и признаке конца файла, посланных партнером. С другой стороны, xout становится немного сложнее, поскольку для получения уведомления об этих событиях он должен выполнять операцию чтения. К счастью, это легко можно обойти с помощью вызова select.
Чтобы это проверить, запрограммируем простой процесс xout, который читает данные из стандартного ввода и записывает их в TCP-соединение. Программа, показанная в листинге 3.12, с помощью вызова select ожидает поступления данных из соединения, хотя реально может прийти только EOF или извещение об ошибке.
Листинг 3.12. Программа, готовая к чтению признака конца файла или ошибки
1 #include "etcp.h"
2 int main( int argc, char **argv )
3 {
4 fd_set allreads;
5 fd_set readmask;
6 SOCKET s;
7 int rc;
8 char buf [ 128 ] ;
9 INIT () ;
10 s = tcp_client( argv [ 1 ], argv[ 2 ] );
11 FD_ZERO( kallreads );
12 FD_SET( s, &allreads );
13 FD_SET( 0, &allreads );
14 for ( ; ; )
15 {
16 readmask = allreads;
17 rc = select(s + 1, &readmask, NULL, NULL, NULL );
18 if ( re <= 0)
19 error( 1, rc ? errno : 0, "select вернул %d", rc );
20 if ( FD_ISSET( 0, &readmask ) }
21 {
22 rc = read( 0, buf, sizeof( buf ) - 1 );
23 if ( rc < 0 )
24 error( 1, errno, "ошибка вызова read" };
25 if ( send( s, buf, rc, 0 ) < 0 )
26 error( 1, errno, "ошибка вызова send" );
27 }
28 if ( FD_ISSET( s, &readmask ) )
29 {
30 rc = recv( s, buf, sizeof( buf ) - 1, 0 );
31 if ( rc == 0 )
32 error( 1, 0, "сервер отсоединился\n" );
33 else if ( rc < 0 )
34 error( 1, errno, "ошибка вызова recv" );
35 else
36 {
37 buf[ rc ] = '\0';
38 error( 1, 0, "неожиданный вход [%s]\n", buf );
39 }
40 }
41 }
42 }
Инициализация
9- 13 Выполняем обычную инициализацию, вызываем функцию tcp_client для установки соединения и готовим select для извещения о наличии входных данных в стандартном вводе или в только что установленном TCP-соединении.
Обработка событий stdin
20-27 Если данные пришли из стандартного ввода, посылаем их удаленному хосту через TCP-соединение.
Обработка событий сокета
28-40 Если пришло извещение о наличии доступных для чтения данных в сокете, то проверяем, это EOF или ошибка. Никаких данных по этому соединению не должно быть получено, поэтому если пришло что-то иное, то печатаем диагностическое сообщение и завершаем работу.
Продемонстрировать работу xout1 можно, воспользовавшись программой keep (листинг 2.30) в качестве внешней системы и простым сценарием на языке интерпретатора команд shell для обработки сообщений (mр на рис. 3.5). Этот сценарий Каждую секунду выводит на stdout слово message и счетчик.
MSGNO=1
while true
do
echo message $MSGNO
sleep 1
MSGNO="expr $MSGNO + 1"
done
Обратите внимание, что в этом случае xoutl использует конвейер в качестве механизма IPC. Поэтому в таком виде программа xoutl не переносится на платформу Windows, поскольку вызов select работает под Windows только для сокетов. Можно было бы реализовать взаимодействие между процессами с помощью TCP или UDP, но тогда потребовался бы более сложный обработчик сообщений.
Для тестирования xoutl запустим сначала «внешнюю систему» в одном окне, а обработчик сообщений и xoutl - в другом.
|
bsd: $ keep 9000 message 1 message 2 message 3 message 4 ^C"Внешняя система" завершила работу bsd: $ |
bsd: $ mp I xoutl localhost 9000 xoutl: сервер отсоединился Broken pipe bsd: $ |
Более интересна ситуация, когда между внешней системой и приложением, обрабатывающим сообщения, необходим обмен подтверждениями. В этом случае придется изменить и xin, и xout (предполагая, что подтверждения нужны в обоих направлениях; если нужно только подтверждать внешней системе прием сообщений, то изменения надо внести лишь в xin). Разработаем пример только процесса-писателя (xout). Изменения в xin аналогичны.
Новый процесс-писатель обязан решать те же проблемы, с которыми вы столкнулись при обсуждении пульсаций в совете 10. После отправки сообщения удаленный хост должен прислать нам подтверждение до того, как сработает таймер. Если истекает тайм-аут, необходима какая-то процедура восстановления после ошибки. В примере работа просто завершается.
При разработке нового «писателя» xout2 вы не будете принимать сообщений из стандартного ввода, пока не получите подтверждения от внешней системы о том, что ей доставлено последнее ваше сообщение. Возможен и более изощренный подход с использованием механизма тайм-аутов, описанного в совете 20. Далее он будет рассмотрен, но для многих систем вполне достаточно той простой схемы, которую будет применена. Текст xout2 приведен в листинге 3.13.
Листинг 3.13. Программа, обрабатывающая подтверждения
1 #include "etcp.h"
2 #define АСК 0х6 /*Символ подтверждения АСК. */
3 int main( int argc, char **argv)
4 {
5 fd_set allreads;
6 fd_set readmask;
7 fd_set sockonly;
8 struct timeval tv;
9 struct timeval *tvp = NULL;
10 SOCKET s;
11 int rc;
12 char buf[ 128 ];
13 const static struct timeval TO = { 2, 0 } ;
14 INIT();
15 s = tcp_client( argv[ 1 ], argv[ 2 ] );
16 FD_ZERO( &allreads );
17 FD_SET( s, &allreads ) ;
18 sockonly = allreads;
19 FD_SET( 0, &allreads );
20 readmask = allreads;
21 for ( ;; )
22 {
23 rc = select( s + 1, &readmask, NULL, NULL, tvp );
24 if ( rc < 0 )
25 error( 1, errno, "ошибка вызова select" );
26 if ( rc == 0 )
27 error( 1, 0, "тайм-аут при приеме сообщения\n" );
28 if ( FD_ISSET( s, &readmask ) )
29 {
30 rc = recv( s, buf, sizeof( buf }, 0 );
31 if ( rc == 0 )
32 error( 1, 0, "сервер отсоединился\n" );
33 else if ( rc < 0 )
34 error( 1, errno, "ошибка вызова recv");
35 else if (rc != 1 buf[ 0 ] != ACK)
36 error( 1, 0, "неожиданный вход [%c]\n", buf[ 0 ] ) ;
37 tvp = NULL; /* Отключить таймер */
38 readmask = allreads; /* и продолжить чтение из stdin. */
39 }
40 if ( FD_ISSET( 0, &readmask ) }
41 {
42 rc = read( 0, buf, sizeof( buf ) ) ;
43 if ( rc < 0 )
44 error( 1, errno, "ошибка вызова read" );
45 if ( send( s, buf, rc, 0 ) < 0 )
46 error( 1, errno, "ошибка вызова send" );
47 tv = T0; /* Переустановить таймер. */
48 tvp = &tv; /* Взвести таймер */
49 readmask = sockonly; /* и прекратить чтение из stdin. */
50 }
51 }
52 }
Инициализация
14-15 Стандартная инициализация TCP-клиента.
16-20 Готовим две маски для select: одну для приема событий из stdin и ТСР-сокета, другую для приема только событий из сокета. Вторая маска sockonly применяется после отправки данных, чтобы не читать новые данные из stdin, пока не придет подтверждение.
Обработка событий таймера
26- 27 Если при вызове select произошел тайм-аут (не получено вовремя подтверждение), то печатаем диагностическое сообщение и завершаем сеанс,
Обработка событий сокета
28-39 Если пришло извещение о наличии доступных для чтения данных в сокете, проверяем, это EOF или ошибка. Если да, то завершаем работу так же, как в листинге 3.12. Если получены данные, убеждаемся, что это всего один символ АСК. Тогда последнее сообщение подтверждено, поэтому сбрасываем таймер, устанавливая переменную tvp в NULL, и разрешаем чтение из стандартного ввода, устанавливая маску readmask так, чтобы проверялись и сокет, и stdin.
Обработка событий в stdin
40-66 Получив событие stdin, проверяем, не признак ли это конца файла. Если чтение завершилось успешно, записываем данные в TCP-соединение.
47-50 Поскольку данные только что переданы внешней системе, ожидается подтверждение. Взводим таймер, устанавливая поля структуры tv и направляя на нее указатель tvp. В конце запрещаем события stdin,записывая в переменную readmask маску sockonly.
Для тестирования программы xout2 следует добавить две строки
if ( send( si, "\006", 1, 0 ) < 0 ) /* \006 = АСК */
error( 1, errno, "ошибка вызова send");
перед записью на строке 24 в исходном тексте keep. с (листинг 2.30). Если выполнить те же действия, как и для программы xoutl, то получим тот же результат с тем отличием, что xout2 завершает сеанс, не получив подтверждения от удаленного хоста
Архитектура с одним соединением
Следует заметить, что ничего не изменится, если на рис. 3.3 вместо TTY-coединения будет написано TCP-соединение. Поэтому та же техника может применяться (и часто применяется) для работы с сетевыми соединениями. Кроме того, использование потоков вместо процессов почти не сказывается на ситуации, изображенной на рисунке, поэтому этот метод пригоден и для многопоточной среды.
Правда, есть одна трудность. Если речь идет о TTY-соединении, то ошибки при операции записи возвращаются самим вызовом write, тогда как в случае TCP ошибка, скорее всего, будет возвращена последующей операцией чтения (совет 15). В много процессной архитектуре процессу-читателю трудно уведомить процесс-писатель об ошибке. В частности, если приложение на другом конце завершается, то об этом узнает читатель, который должен как-то известить писателя.
Немного изменим точку зрения и представим себе приложение, которое принимает сообщения от внешней системы и посылает их назад по TCP-соединению. Сообщения передаются и принимаются асинхронно, то есть не для каждого входного сообщения генерируется ответ, и не каждое выходное сообщение посылается в ответ на входное. Допустим также, что сообщения нужно переформатировать на

Рис. 3.4. Приложение, обменивающиеся сообщениями по TCP-соединению
входе или выходе из приложения. Тогда представленная на рис. 3.4 архитектура многопроцессного приложения оказывается вполне разумной.
На этом рисунке процесс xin читает данные от внешней системы, накапливает их в очереди сообщений, переформатирует и передает главному процессу обработки сообщений. Аналогично процесс xout приводит выходное сообщение к формату, требуемому внешней системой, и записывает данные в TCP-соединение. Главный процесс mp обрабатывает отформатированные входные сообщения и генерирует выходные сообщения. Оставляем неспецифицированным механизм межпроцессного взаимодействия (IPC) между тремя процессами. Это может быть конвейер, разделяемая память, очереди сообщений или еще что-то. Подробнее все возможности рассмотрены в книге [Stevens 1999]. В качестве реального примера такого рода приложения можно было бы привести шлюз, через который передаются сообщения между системами. Причем одна из систем работает по протоколу TCP, а другая - по какому-либо иному протоколу.
Если обобщить этот пример, учитывая дополнительные внешние системы с иными требованиями к формату сообщений, то становится ясно, насколько гибкие возможности предоставляет описанный метод. Для каждого внешнего хоста имеется свой набор коммуникационных процессов, работающих только с его сообщениями. Такая система концептуально проста, позволяет вносить изменения, относящиеся к одному из внешних хостов, не затрагивая других, и легко конфигурируется для заданного набора внешних хостов - достаточно лишь запустить свои коммуникационные процессы для каждого хоста.
Однако при этом остается нерешенной вышеупомянутая проблема: процесс-писатель не может получить сообщение об ошибке после операции записи. А иногда у приложения должна быть точная информация о том, что внешняя система действительно получила сообщение, и необходимо организовать протокол подтверждений по типу того, что обсуждался в совете 9. Это означает, что нужно либо создать отдельный коммуникационный канал между процессами xin и xout, либо xin должен посылать информацию об успешном получении и об ошибках процессу mp, который, в свою очередь, переправляет их процессу xout. To и другое усложняет взаимодействие процессов.
Можно, конечно, отказаться от многопроцессной архитектуры и оставить всего один процесс, добавив select для мультиплексирования сообщений. Однако при этом приходится жертвовать гибкостью и концептуальной простотой.
Далее в этом разделе рассмотрим альтернативную архитектуру, при которой сохраняется гибкость, свойственная схеме на рис. 3.4, но каждый процесс самостоятельно следит за своим TCP-соединением.
Бесклассовая междоменная маршрутизация- CIDR
Теперь вам известно, как организация подсетей решает одну из проблем, связанных с классами адресов: переполнение маршрутных таблиц. Хотя и в меньшей степени, подсети все же позволяют справиться и с проблемой истощения IP - адресов за счет лучшего использования пула идентификаторов хостов в пределах одной сети.
Еще одна серьезная проблема - это недостаток сетей класса В. Как показано на рис. 2.5, существует менее 17000 таких сетей. Поскольку большинство средних и крупных организаций нуждается в количестве IP-адресов, превышающем возможности сети класса С, им выделяется идентификатор сети класса В.
В условиях дефицита сетей класса В организациям приходилось выделять блоки адресов сетей класса С, но при этом вновь возникает проблема, которую пытались решить с помощью подсетей, - растут маршрутные таблицы.
Бесклассовая междоменная маршрутизация (CIDR) решает эту проблему, вывернув принцип организации подсетей «наизнанку». Вместо увеличения CIDR уменьшает длину идентификатора сети в IP-адресе.
Предположим, некоторой организации нужно 1000 IP-адресов. Ей выделяют четыре соседних идентификатора сетей класса С с общим префиксом от 200.10.4.0 до 200.10.7.0. Первые 22 бита этих идентификаторов одинаковы и представляют номер агрегированной сети, в данном случае 200.10.4.0. Как и для подсетей, для идентификации сетевой части IP-адреса используется маска сети. В приведенном здесь примере она равна 255.255.252.0 (0xfffffc00).
Но в отличие от подсетей эта маска сети не расширяет сетевую часть адреса, а укорачивает ее. Поэтому CIDR называют также суперсетями. Кроме того, маска сети в отличие от маски подсети экспортируется во внешний мир. Она становится частью любой записи маршрутной таблицы, ссылающейся на данную сеть.
Допустим, внешнему маршрутизатору R надо переправить датаграмму по адресу 200.10.5.33, который принадлежит одному из хостов в агрегированной сети. Он просматривает записи в своей маршрутной таблице, в каждой из которых хранятся маска сети, и сравнивает замаскированную часть адреса 200.10.5.33 с хранящимся в записи значением. Если в таблице есть запись для сети, то в ней будет храниться адрес 200.10.4.0 и маска сети 255.255.252.0. Когда выполняется операция побитового AND между адресом 200.10.5.33 и этой маской, получается значение 200.10.4.0. Это значение совпадает с хранящимся в записи номером подсети, так что маршрутизатору известно, что именно по этому адресу следует переправить датаграмму.
Если возникает неоднозначность, то берется самое длинное соответствие. Например, в маршрутной таблице может быть также запись с адресом 200.10.0.0 и маской сети 255.255.0.0. Эта запись также соответствует адресу 200.10.5.33, но, поскольку для нее совпадают только 16 бит, а не 22, как в первом случае, то предпочтение отдается первой записи.
Примечание: Может случиться так, что Internet сервис - провайдер (ISP) «владеет» всеми IP-адресами с префиксом 200.10. В соответствии со второй из рассмотренных выше записей маршрутизатор отправил бы этому провайдеру все датаграммы, адрес назначения которых начинается с 200.10. Тогда провайдер смог бы указать более точный маршрут, чтобы избежать лишних звеньев в маршруте или по какой-то иной причине.
В действительности механизм CIDR более общий. Он называется «бесклассовым», так как понятие «класса» в нем полностью отсутствует. Таким образом, каждая запись в маршрутной таблице содержит маску сети, определяющую сетевую часть IP-адреса. Если принять, что адрес принадлежит некоторому классу, то эта маска может укоротить или удлинить сетевую часть адреса. Но поскольку в CIDR понятия «класса» нет, то можно считать, что сетевая маска выделяет сетевую часть адреса без изменения ее длины.
В действительности, маска - это всего лишь число, называемое префиксом, которое определяет число бит в сетевой части адреса. Например, для выше упомянутой агрегированной сети префикс равен 22, и адрес этой сети следовало бы записать как 200.10.4.0/22, где /22 обозначает префикс. С этой точки зрения адресацию на основе классов можно считать частным случаем CIDR, когда имеется всего четыре (или пять) возможных префиксов, закодированных в старших битах адреса.
Гибкость, с которой CIDR позволяет задавать размер адреса сети, позволяет эффективно распределять IP-адреса блоками, размер которых оптимально соответствует потребностям сети. Вы уже видели, как можно использовать CIDR для агрегирования нескольких сетей класса С в одну большую сеть. А для организации маленькой сети из нескольких хостов можно выделить лишь часть адресов сети класса С. Например, сервис - провайдер выделяет небольшой компании с единственной ЛВС адрес сети 200.50.17.128/26. В такой сети может существовать до 62 хостов (2^6-2).
В RFC 1518 [Rekhter и Li 1993] при обсуждении вопроса об агрегировании адресов и его влиянии на размер маршрутных таблиц рекомендуется выделять префиксы IP-адресов (то есть сетевые части адреса) иерархически.
Примечание: Иерархическое агрегирование адресов можно сравнить с иерархической файловой системой вроде тех, что используют в UNIX и Windows. Так же, как каталог верхнего уровня содержит информацию о своих подкаталогах, но не имеет сведений о находящихся в них файлах, доменам маршрутизации верхнего уровня известно лишь о промежуточных доменах, а не о конкретных сетях внутри них. Предположим, что региональный провайдер обеспечивает весь трафик для префикса 200/8, а к нему подключены три локальных провайдера с префиксами 200.1/16,200.2/16 и 200.3/16. У каждого провайдера есть несколько клиентов, которым выделены части располагаемого адресного пространства (200.1.5/24 и т.д.). Маршрутизаторы, внешние по отношению к региональному провайдеру, должны хранить в своих таблицах только одну запись - 200/8. Этого достаточно для достижения любого хоста в данном диапазоне адресов. Решения о выборе маршрута можно принимать, даже не зная о разбиении адресного пространства 200/8. Маршрутизатор регионального провайдера должен хранить в своей таблице только три записи: по одной для каждого локального провайдера. На самом нижнем уровне локальный провайдер хранит записи для каждого своего клиента. Этот простой пример позволяет видеть суть агрегирования.
Почитать RFC 1518 очень полезно, поскольку в этом документе демонстрируются преимущества использования CIDR. В RFC 1519 [Fuller et al. 1993] описаны CIDR и ее логическое обоснование, а также приведены подробный анализ затрат, связанных с CIDR, и некоторые изменения, которые придется внести в протоколы междоменной маршрутизации.
Буферы в разделяемой памяти
Обойтись почти без копирования, даже между разными процессами, можно, воспользовавшись разделяемой памятью. Разделяемая память - это область памяти, доступная сразу нескольким процессам. Каждый процесс отображает блок виртуальной памяти на адрес в собственном адресном пространстве (в разных процессах эти адреса могут быть различны), а затем обращается к нему, как к собственной памяти.
Идея состоит в том, чтобы создать массив буферов в разделяемой памяти, построить сообщение в одном из них, а затем передать индекс буфера следующему процессу, применяя механизм IPC. При этом «перемещается» только одно целое число, представляющее индекс буфера в массиве. Например, на рис. 3.15 в качестве механизма IPC используется TCP для передачи числа 3 от процесса 1 процессу 2. Когда процесс 2 получает это число, он определяет, что приготовлены данные в буфере smbarray [ 3 ].

Рис. 3.15. Передача сообщений через буфер в разделяемой памяти
На рис. 3.15 два пунктирных прямоугольника представляют адресные пространства процессов 1 и 2, а их пересечение - общий сегмент разделяемой памяти, который каждый из процессов отобразил на собственное адресное пространство. Массив буферов находится в разделяемом сегменте и доступен обоим процессам. Процесс 1 использует отдельный канал IPC (в данном случае - TCP) для информирования процесса 2 о том, что для него готовы данные, а также место, где их искать.
Хотя здесь показано только два процесса, этот прием прекрасно работает для любого их количества. Кроме того, процесс 2, в свою очередь, может передать сообщение процессу 1, получив буфер в разделяемой памяти, построив в нем сообщение и послав процессу 1 индекс буфера в массиве.
Единственное, что пока отсутствует, - это синхронизация доступа к буферам, то есть предотвращение ситуации, когда два процесса одновременно получат один и тот же буфер. Это легко делается с помощью мьютекса, что и будет продемонстрировано ниже.
Чтение ICMP-сообщений
Начнем с включаемых в программу файлов и функции main (листинг 4.3).
Листинг 4.3. Функция main программы icmp
icmp.с
1 #include <sys/types.h>
2 #include <netinet/in_systm.h>
3 #include <netinet/in.h>
4 #include <netinet/ip.h>
5 #include <netinet/ip_icmp.h>
6 #include <netinet/udp.h>
7 #include <etcp.h>
8 int main (int args, char **argv)
9 {
10 SOCKET s;
11 struct protoent *pp;
12 int rc;
13 char icmpdg [1024];
14 INIT ();
15 pp = getprotobyname (“icmp“);
16 if (pp == NULL)
17 error ( 1, errno, “ошибка вызова getprotobyname” );
18 s = socket (AF_INET, SOCK_RAW, pp->p_proto);
19 if (!isvalidsock (s))
20 error ( 1, errno, “ошибка вызова socket” );
21 for ( ; ; )
22 {
23 rc = recvform (s, icmpdg, sizeof (icmpdg)), 0,
24 NULL, NULL);
25 if ( rc < 0 )
26 error ( 1, errno, “ошибка вызова recvfrom” );
27 print_dg (icmpdg, rc);
28 }
29 }
Открытие простого сокета
15-20 Поскольку использован простой сокет, надо указать нужный протокол. Вызов фуекции getprotobyname возвращает структуру, содержащую номер протокола ICMP. Обратите внимание, что в качестве типа указана константа SOCK_RAW, а не SOCK_STREAM или SOCK_DGRAM, как раньше.
Цикл обработки событий
21-28 Читаем каждую IP-диаграмму, используя recvform, как и в случае UDP-датаграмм. Для печати поступающих ICMP-сообщений вызываем функцию print_dg.
Что это такое
Состояние TIME-WAIT наступает в ходе разрыва соединения. Помните (совет 7), что для разрыва TCP-соединения нужно обычно обменяться четырьмя сегментами, как показано на рис. 3.8.
На рис. 3.8 показано соединение между двумя приложениями, работающими на хостах 1 и 2. Приложение на хосте 1 закрывает свою сторону соединения, при этом TCP посылает сегмент FIN хосту 2. Хост 2 подтверждает FIN сегментом АСК и доставляет FIN приложению в виде признака конца файла EOF (предполагается, что у приложения есть незавершенная операция чтения, - совет 16). Позже приложение на хосте 2 закрывает свою сторону соединения, посылая FIN хосту 1, который отвечает сегментом АСК.

Рис. 3.8. Разрыв соединения
В этот момент хост 2 окончательно закрывает соединение и освобождает ресурсы. С точки зрения хоста 2, соединения больше не существует. Однако хост 1 закрывает соединение, а переходит в состояние TIME-WAIT и остается в нем в течение двух максимальных продолжительностей существования сегмента (2MSL maximum segment lifetime).
Примечание: Максимальное время существования сегмента (MSL) - это максимальное время, в течение которого сегмент может оставаться в сети, прежде чем будет уничтожен. В каждой IР-датаграммеесть поле TTL (time-to-live - время жизни). Это поле уменьшается нa единицу каждым маршрутизатором, через который проходит датаграмма. Когда TTL становится равным нулю, датаграмма уничтожается. Хотя официально TTL измеряется в секундах, в действительности это поле почти всегда интерпретируется маршрутизаторами как счетчик промежуточных узлов. В RFC 1812 [Baker 1995] этот вопрос обсуждается подробнее.
Прождав время 2MSL, хост 1 также закрывает соединение и освобождает ресурсы.
Относительно состояния TIME-WAIT следует помнить следующее:
обычно в состояние TIME-WAIT переходит только одна сторона - та, что выполняет активное закрытие;
Примечание: Под активным закрытием понимается отправка первого FIN. Считается, что вторая сторона при этом выполняет пассивное закрытие. Возможно также одновременное закрытие, когда обе стороны закрывают соединение примерно в одно время, поэтому посланные ими FIN одновременно находятся в сети. В этом случае активное закрытие выполняют обе стороны, так что обе переходят в состояние TIME- WAIT.
в RFC 793 [Postel 1981b] MSL определено равным 2 мин. При этом соединение должно оставаться в состоянии TIME-WAIT в течение 4 мин. На практике это обычно не так. Например, в системах, производных от BSD, MSL равно 30 с, так что состояние TIME-WAIT длится всего 1 мин. Можно встретить и другие значения в диапазоне от 30 с до 2 мин;
если в то время, когда соединение находится в состоянии TIME-WAIT, прибывает новый сегмент, то таймер на 2MSL перезапускается. Это будет рассматриваться ниже.
Что такое надежность
Прежде чем приступать к рассмотрению ошибок, с которыми можно столкнутся при работе с TCP, обсудим, что понимается под надежностью TCP. Если TCP нe гарантирует доставку всех данных, то что же он гарантирует? Первый вопрос: кому дается гарантия? На рис. 2.18 показан поток данных от приложения А вниз к стеку TCP/IP на хосте А, через несколько промежуточных маршрутизаторов, вверх к стеку TCP/IP на хосте В и, наконец, к приложению В. Когда ТСР- сегмент покидает уровень TCP на хосте А, он «обертывается» в IP-датаграмму для передачи хосту на другой стороне. По пути он может пройти через несколько маршрутизаторов, но, как видно из рис. 2.18, маршрутизаторы не имеют уровня TCP,они лишь переправляют IР - датаграммы.

Рис. 2.18. Сеть с промежуточными маршрутизаторами
Примечание: Некоторые маршрутизаторы в действительности могут представлять собой компьютеры общего назначения, у которых есть полный стек TCP/IP, но и в этом случае при выполнении функций маршрутизации не задействуются ни уровень TCP, ни прикладной уровень.
Поскольку известно, что протокол IP ненадежен, то первое место в тракте прохождения данных, в связи с которым имеет смысл говорить о гарантиях, - это уровень TCP хоста В. Когда сегмент оказывается на этом уровне, единственной, что можно сказать наверняка, - сегмент действительно прибыл. Он может быть запорчен, оказаться дубликатом, прийти не по порядку или оказаться неприемлемым еще по каким-то причинам. Обратите внимание, что отправляющий TCP не может дать никаких гарантий по поводу сегментов, доставленных принимающему TCP.
Однако принимающий TCP уже готов кое-что гарантировать отправляющему TCP, а именно - любые данные, которые он подтвердил с помощью сегмента АСК, а также все предшествующие данные, корректно дошли до уровня TCP. Поэтому отправляющий TCP может отбросить их копии, которые у него хранятся. Это не означает, что информация уже доставлена приложению или будет доставлена в будущем. Например, принимающий хост может аварийно остановиться сразу после посылки АСК, еще до того, как данные прочитаны приложением. Это стоит подчеркнуть особо: единственное подтверждение приема данных, которое находите в ведении TCP, - это вышеупомянутый сегмент АСК. Отправляющее приложение не может, полагаясь только на TCP, утверждать, что данные были благополучно прочитаны получателем. Как будет сказано далее, это одна из возможных ошибок при работе с TCP, о которых разработчик должен знать.
Второе место, в связи с которым имеет смысл говорить о гарантиях, - это само приложение В. Вы поняли, нет гарантий, что все данные, отправленные приложением A, дойдут до приложения В. Единственное, что TCP гарантирует приложению B, -доставленные данные пришли в правильном порядке и не испорчены.
Примечание: Неискаженностъ данных гарантируется лишь тем, что ошибку можно обнаружить с помощью контрольной суммы. Поскольку эта сумма представляет собой 16-разрядное дополнение до единицы суммы двойных байтов, то она способна обнаружить пакет ошибок в 15 бит или менее [Plummer 1978]. Предполагая равномерное распределение данных, вероятность принятия TCP ошибочного сегмента за правильный составляет не более 1 / (2^16 - 1). Однако в работе [Stone et al. 1998] показано, что в реальных данных, встречающихся в сегментах TCP, частота ошибок, не обнаруживаемых с помощью контрольной суммы, при некоторых обстоятельствах может быть намного выше.
Другие ресурсы, относящиеся к конференциям
Следует упомянуть еще о двух ценных ресурсах, связанных с сетевыми конференциями. Первый - это сайт DejaNews (http://www.deja.com).
Примечание: В мае 1999 сайт Deja News изменил свое название на Deja.com. Владельцы объясняют это расширением спектра услуг. В этом разделе говорится только о первоначальных услугах по архивации сообщений из сетевых конференций и поиску в архивах.
На этом сайте хранятся архивы примерно 45000 дискуссионных форумов, включая конференции Usenet и собственные конференции Deja Community Discussions. Владельцы Deja.com утверждают, что примерно две трети всех архивов составляют сообщения из конференций Usenet. На конец 1999 года в архивах хранились сообщения, начиная с марта 1995 года.
Поисковая система сайта Power Search позволяет искать ответ на конкретный вопрос или информацию по некоторой проблеме в отдельной конференции, в группе или даже во всех конференциях по ключевому слову, теме, автору или диапазону дат. Второй ценный ресурс - это список ресурсов по TCP/IP (TCP/IP Resources List) Юри Раца (Uri Raz), который каждые две недели рассылается в конференцию comp.protocols.tcp-ip и некоторые более специальные. Этот список - отличная отправная точка для тех, кто ищет конкретную информацию или общий обзор TCP/IP и соответствующих API.
В списке имеются ссылки на книги по этому вопросу и другим, касающимся сетей; онлайновые ресурсы (к примеру, страницы IETF и сайты, где размещаются FAQ); онлайновые книги и журналы, учебники по TCP/IP; источники информации по протоколу IPv6; домашние страницы многих популярных книг по сетям; домашние страницы книжных издательств; домашние страницы проекта GNU и открытых операционных систем; поисковые машины с описанием способов работы с ними и конференции, посвященные сетям.
Самая последняя редакция списка находится на сайтах:
http://www.private.org.il/tcpip_rl.html;
http://www.best.com.il/~mphunter/tcpip_resources.html;
Также информация может быть загружена по FTP с сайтов:
ftp://rtfra.mit.edu/pub/usenet-by-group/news.answers/internet/tcp-ip/resource-list;
ftp://rtfm.mit.edu/pub/usenet-by-hierarchy/comp/protocols/tcp-ip/TCP-IP_Resources_List.
Особую ценность списку ресурсов по TCP/IP придает тот факт, что автор регулярно обновляет его. Это немаловажно, так как ссылки в Web имеют тенденцию быстро устаревать.
| | |
Еще один пример пульсации
Использованная в предыдущем примере модель не совсем пригодна в ситуации, когда одна сторона посылает другой поток данных, не разбитый на сообщения. Проблема в том, что посланный пульс оказывается частью потока, поэтому его идется явно выискивать и, возможно, даже экранировать (совет 6). Чтобы избежать сложностей, следует воспользоваться другим подходом.
Идея в том, чтобы использовать для контрольных пульсов отдельное соединение. На первый взгляд, кажется странной возможность контролировать одно соединение с помощью другого. Но помните, что делается попытка обнаружить крах оста на другом конце или разрыв в сети. Если это случится, то пострадают оба соединения. Задачу можно решить несколькими способами. Традиционный способ - создать отдельный поток выполнения (thread) для управления пульсацией. Можно также применить универсальный механизм отсчета времени, который разработан в совете 20. Однако, чтобы не вдаваться в различия между API потоков на платформе Win32 и библиотекой PThreads в UNIX, модифицируем написанный для предыдущего примера код с использованием системного вызова select.
Новые версии клиента и сервера очень похожи на исходные. Основное различие состоит в логике работы select, который теперь должен следить за двумя сокетами, а также в дополнительном коде для инициализации еще одного соединения. После соединения клиента с сервером, клиент посылает ему номер порта, по которому отслеживается пульсация сервера. Это напоминает то, что делает FТР-сервер, устанавливая соединение для обмена данными с клиентом.
Примечание: Может возникнуть проблема, если для преобразования частных сетевых адресов в открытые используется механизм NAT (совет 3). В отличие от ситуации с FTP программное обеспечение NAT не имеет информации, что нужно подменить указанный номер порта преобразованным. В таком случае самый простой путь - выделить приложению второй хорошо известный порт.
Начнем с логики инициализации и установления соединения на стороне клиента (листинг 2.26).
Листинг 2.26. Код инициализации и установления соединения на стороне клиента
1 #include "etcp.h"
2 #include "heartbeat.h"
3 int main( int argc, char **argv )
4 {
5 fd_set allfd;
6 fd_set readfd;
7 char msg[ 1024 ];
8 struct tirneval tv;
9 struct sockaddr_in hblisten;
10 SOCKET sdata;
11 SOCKET shb;
12 SOCKET slisten;
13 int rc;
14 int hblistenlen = sizeof( hblisten );
15 int heartbeats = 0;
16 int maxfdl;
17 char hbmsg[ 1 ];
18 INIT();
19 slisten = tcp_server( NULL, "0" ) ;
20 rc = getsockname( slisten, ( struct sockaddr * )&hblisten,
21 &hblistenlen );
23 error( 1, errno, "ошибка вызова getsockname" );
24 sdata = tcp_client( argv[ 1 ], argv[ 2 ] );
25 rc = send( sdata, ( char * ) &hblisten. sin__port,
26 sizeof( hblisten.sin_port ), 0 ) ;
27 if ( rc < 0 )
28 error( 1, errno, "ошибка при посылке номера порта");
29 shb = accept( slisten, NULL, NULL );
30 if ( !isvalidsock( shb ) )
31 error( 1, errno, "ошибка вызова accept" );
32 FD_ZERO( &allfd ) ;
33 FD_SET( sdata, &allfd );
34 FD_SET( shb, &allfd ) ;
35 maxfdl = ( sdata > shb ? sdata: shb ) + 1;
36 tv.tv_sec = Tl;
37 tv.tv_usec = 0;
Инициализация и соединение
19-23 Вызываем функцию tcp_server с номером порта 0, таким образом заставляя ядро выделить эфемерный порт (совет 18). Затем вызываем getsockname, чтобы узнать номер этого порта. Это делается потому, что с данным сервером ассоциирован только один хорошо известный порт.
24-28 Соединяемся с сервером и посылаем ему номер порта, с которым он должен установить соединение для посылки сообщений-пульсов.
29-31 Вызов accept блокирует программу до тех пор, пока сервер не установит соединение для пульсации. В промышленной программе, наверное, стоило бы для этого вызова взвести таймер, чтобы программа не «зависла», если сервер не установит соединения. Можно также проверить, что соединение для пульсации определил именно тот сервер, который запрашивался в строке 24.
32- 37 Инициализируем маски для select и взводим таймер.
Оставшийся код клиента показан в листинге 2.27. Здесь вы видите обработку содержательных сообщений и контрольных пульсов.
Листинг 2.27. Обработка сообщений клиентом
38 for ( ;; )
39 {
40 readfd = allfd;
41 rc = select( maxfdl, &readfd, NULL, NULL, &tv );
42 if ( rc < 0 )
43 error( 1, errno, "ошибка вызова select" );
44 if ( rc == 0 ) /* Произошел тайм-аут. */
45 {
46 if ( ++heartbeats > 3 )
47 error( 1, 0, "соединения нет\n" );
4g error( 0, 0, "посылаю пульс #%d\n", heartbeats );
49 rc = send( shb, "", 1, 0 ) ;
50 if ( rc < 0 )
51 error( 1, errno, "ошибка вызова send" );
52 tv.tv_sec = T2;
53 continue;
54 }
55 if ( FD_ISSET( shb, &readfd ) )
56 {
57 rc = recv( shb, hbmsg, 1, 0 );
58 if ( rc == 0 )
59 error( 1, 0, "сервер закончил работу (shb)\n" );
60 if ( rc < 0 )
61 error( 1, errno, "ошибка вызова recv для сокета shb");
62 }
63 if ( FD_ISSET( sdata, &readfd ) )
64 {
65 rc = recv( sdata, msg, sizeof( msg ), 0 );
66 if ( rc == 0 )
67 error( 1, 0, "сервер закончил работу (sdata)\n" );
68 if ( rc < 0 )
69 error( 1, errno, "ошибка вызова recv" );
70 /* Обработка данных. */
71 }
72 heartbeats = 0;
73 tv.tv_sec = T1;
74 }
75 }
Обработка данных и пульсов
40-43 Вызываем функцию select и проверяем код возврата.
44-54 Таймаут обрабатывается так же, как в листинге 2.24, только пульсы посылаются через сокет shb.
55-62 Если через сокет shb пришли данные, читаем их, но ничего не делаем.
63-71 Если данные пришли через сокет sdata, читаем столько, сколько сможем, и обрабатываем. Обратите внимание, что теперь производится работа не с сообщениями фиксированной длины. Поэтому читается не больше, чем помещается в буфер. Если данных меньше длины буфера, вызов recv вернет все, что есть, но не заблокирует программу. Если данных больше, то из сокета еще можно читать. Поэтому следующий вызов select немедленно вернет управление, и можно будет обработать очередную порцию данных.
72- 73 Поскольку только что пришло сообщение от сервера, сбрасываем переменную heartbeats в 0 и снова взводим таймер.
И в заключение рассмотрим код сервера для этого примера (листинг 2.28) Как и код клиента, он почти совпадает с исходным сервером (листинг 2.25) за тем и исключением, что устанавливает два соединения и работает с двумя сокетами.
Листинг 2.28. Код инициализации и установления соединения на стороне сервер^!
hb_server2.c
1 #include "etcp.h"
2 #include "heartbeat.h"
3 int main( int argc, char **argv )
4 {
5 fd_set allfd;
6 fd_set readfd;
7 char msg[ 1024 ];
8 struct sockaddr_in peer;
9 struct timeval tv;
10 SOCKET s;
11 SOCKET sdata;
12 SOCKET shb;
13 int rc
14 int maxfdl;
15 int missed_heartbeats = 0;
16 int peerlen = sizeof( peer);
17 char hbmsg[ 1 ];
18 INIT ();
19 s = tcp_server( NULL, argv[ 1 ] );
20 sdata = accept( s, ( struct sockaddr * )&peer,
21 &peerlen );
22 if ( !isvalidsock( sdata ) )
23 error( 1, errno, "accept failed" );
24 rc = readn( sdata, ( char * )&peer.sin_port,
25 sizeof( peer.sin_port ) );
26 if ( rc < 0 )
27 error( 1, errno, "ошибка при чтении номера порта" );
28 shb = socket( PF_INET, SOCK_STREAM, 0 );
29 if ( !isvalidsock( shb ) )
30 error ( 1, errno, "ошибка при создании сокета shb" );
31 rc = connect ( shb, ( struct sockaddr * )&peer, peerlen );
32 if (rc )
33 error( 1, errno, "ошибка вызова connect для сокета shb");
34 tv.tv_sec = T1 + T2;
35 tv.tv_usec = 0;
36 FD_ZERO( &allfd ) ;
37 FD_SET( sdata, &allfd );
38 FD_SET( shb, &allfd ) ;
39 maxfdl = ( sdata > shb ? sdata : shb ) + 1;
Инициализация и соединение
19-23 Слушаем и принимаем соединения от клиента. Кроме того, сохраняем адрес клиента в переменной peer, чтобы знать, с кем устанавливать соединение для пульсации.
24-27 Читаем номер порта, который клиент прослушивает в ожидании соединения для пульсации. Считываем его непосредственно в структуру peer. О преобразовании порядка байтов с помощью htons или ntohs беспокоиться не надо, так как порт уже пришел в сетевом порядке. В таком виде его и надо сохранить в peer.
28- 33 Получив сокет shb, устанавливаем соединение для пульсации.
34-39 Взводим таймер и инициализируем маски для select.
Оставшаяся часть сервера представлена в листинге 2.29.
Листинг 2.29. Обработка сообщений сервером
40 for ( ;; )
41 {
42 readfd = allfd;
43 rc = select( maxfdl, &readfd, NULL, NULL, &tv );
44 if ( rc < 0 )
45 error( 1, errno, "ошибка вызова select" );
46 if ( rc == 0 ) /* Произошел тайм-аут. */
47 {
48 if ( ++missed_heartbeats > 3 )
49 error( 1, 0, "соединения нет\n" );
50 error( 0, 0, "пропущен пульс #%d\n",
51 missed_heartbeats );
52 tv.tv_sec = T2;
53 continue;
54 }
55 if ( FD_ISSET( shb, &readfd ) )
56 {
57 rc = recv( shb, hbmsg, 1, 0 );
58 if ( rc == 0 )
59 error( 1, 0, "клиент завершил работу\n" );
60 if ( rc < 0 )
61 error( 1, errno, "ошибка вызова recv для сокета shb" );
62 rc = send( shb, hbmsg, 1, 0 );
63 if ( rc < 0 )
64 error( 1, errno, "ошибка вызова send для сокета shb" );
65 }
66 if ( FD_ISSET( sdata, &readfd ) )
67 {
68 rc = recv (sdata, msg, sizeof( msg ), 0);
69 if ( rc == 0 )
70 error (1, 0, “клиент завершил работу\n”);
71 if ( rc < 0 )
72 error (1, errno, “ошибка вызова recv”);
73 /*Обработка данных*/
74 }
75 missed_heartbeats = 0;
76 tv.tv_sec = T1 + T2;
77 }
78 EXIT( 0 );
79 }
42-45 Как и в ситуации с клиентом, вызываем select и проверяем возвращаемое значение.
46-53 Обработка тайм-аута такая же, как и в первом примере сервера в листинге 2.25.
55-65 Если в сокете shb есть данные для чтения, то читаем однобайтовый пульс и возвращаем его клиенту.
66-74 Если что-то поступило по соединению для передачи данных, читаем и обрабатываем данные, проверяя ошибки и признак конца файла.
75-76 Поскольку только что получены данные от клиента, соединение все еще живо, поэтому сбрасываем в нуль счетчик пропущенных пульсов и переустанавливаем таймер.
Если запустить клиента и сервер и имитировать сбой в сети, отсоединив один из хостов, то получим те же результаты, что при запуске hb_server и hb_client.
Функции совместимости с Windows
В листинге П2.2 приведены различные функции, которые использованы в примерах, но отсутствуют в Windows.
Листинг П 2.2. Функции совместимости с Windows
1 #include <sys/timeb.h>
2 #include "etcp.h"
3 #include <winsock2.h>
4 #define MINBSDSOCKERR ( WSAEWOULDBLOCK )
5 #define MAXBSDSOCKERR ( MINBSDSOCKERR + \
6 ( sizeof( bsdsocketerrs ) / \
7 sizeof( bsdsocketerrs[ 0 ] ) ) )
8 extern int sys_nerr;
9 extern char *sys_errlist [];
10 extern char *program_name;
11 static char *bsdsocketerrs [] =
12 {
13 "Resource temporarily unavailable", /* Ресурс временно недоступен. */
14 "Operation now in progress", /* Операция начала выполняться. */
15 "Operation already in progress", /* Операция уже выполняется. */
16 "Socket operation on non-socket", /* Операция сокета не над сокетом. */
17 "Destination address required", /* Нужен адрес назначения. */
18 "Message too long", /* Слишком длинное сообщение. */
19 "Protocol wrong type for socket", /* Неверный тип протокола для сокета. */
20 "Bad protocol option", /* Некорректная опция протокола. */
21 "Protocol not supported", /* Протокол не поддерживается. */
22 "Socket type not supported", /* Тип сокета не поддерживается. */
23 "Operation not supported", /* Операция не поддерживается. */
24 "Protocol family not supported", /* Семейство протоколов не поддерживается. */
25 "Address family not supported by protocol family", /* Адресное семейство не поддерживается семейством протоколов*/
26 "Address already in use", /* Адрес уже используется. */
27 "Can't assign requested address", /* He могу выделить затребованный адрес. */
28 "Network is down", /* Сеть не работает. */
29 "Network is unreachable", /* Сеть недоступна. */
30 "Network dropped connection on reset", /* Сеть сбросила соединение при перезагрузке. */
31 "Software caused connection abort", /* Программный разрыв соединения. */
32 "Connection reset by peer", /* Соединение сброшено другой стороной. */
33 "No buffer space available", /* Нет буферов. */
34 "Socket is already connected", /* Сокет уже соединен. */
35 "Socket is not connected", /* Сокет не соединен. */
36 "Cannot send after socket shutdown", /* He могу послать данные после размыкания. */
37 "Too many references: can't splice", /* Слишком много ссылок. */
38 "Connection timed out", /* Таймаут на соединении. */
39 "Connection refused", /* В соединении отказано. */
40 "Too many levels of symbolic links", /* Слишком много уровней символических ссылок. */
41 "File name too long", /* Слишком длинное имя файла. */
42 "Host is down", /* Хост не работает. */
43 "No route to host" ' /* Нет маршрута к хосту. */
44 };
45 void init ( char **argv )
46 {
47 WSADATA wsadata;
48 ( program_name = strrchr( argv[ 0 ], '\\' ) ) ?
49 program_name++ : ( program_name = argv[ 0 ] ) ;
50 WSAStartupf MAKEWORD( 2, 2 ), &wsadata );
51 }
52 /* inet_aton - версия inet_aton для SVr4 и Windows. */
53 int inet_aton( char *cp, struct in_addr *pin )
54 {
55 int rc;
56 rc = inet_addr( cp );
57 if ( rc == -1 && strcmpl cp, "255.255.255.255" ))
58 return 0;
59 pin->s_addr = rc;
60 return 1;
61 }
62 /* gettimeofday - для tselect. */
63 int gettimeofday( struct timeval *tvp, struct timezone *tzp )
64 {
65 struct _timeb tb;
66 _ftime( &tb );
67 if ( tvp )
68 {
69 tvp->tv_sec = tb.time;
70 tvp->tv_usec = tb.millitm * 1000;
71 }
72 if ( tzp )
73 {
74 tzp->tz_minuteswest = tb.timezone;
75 tzp->tz_dsttime = tb.dstflag;
76 }
77 }
78 /* strerror - версия, включающая коды ошибок Winsock. */
79 char *strerror( int err )
80 {
81 if ( err >= 0 й& err < sys_nerr )
82 return sys_errlist[ err ];
83 else if ( err >= MINBSDSOCKERR && err < MAXBSDSOCKERR )
84 return bsdsocketerrs[ err - MINBSDSOCKERR ];
85 else if ( err == WSASYSNOTREADY )
86 return "Network subsystem is unusable";
/* Сетевая подсистема неработоспособна. */
87 else if ( err == WSAVERNOTSUPPORTED )
88 return " This version of Winsock not supported";
/* Эта версия Winsock не поддерживается. */
89 else if ( err == WSANOTINITIALISED )
90 return "Winsock not initialized";
/* Winsock не инициализирована. */
91 else
92 return "Unknown error";
/* Неизвестная ошибка. */
93 }
| | |
повысить свою квалификацию. Для получения
| | |
Цель этой книги - помочь программистам разных уровней - от начального до среднего - повысить свою квалификацию. Для получения статуса мастера требуется практический опыт и накопление знаний в конкретной области. Конечно, опыт приходит только со временем и практикой, но данная книга существенно пополнит багаж ваших знаний.
Сетевое программирование - это обширная область с большим выбором различных технологий для желающих установить связь между несколькими машинами. Среди них такие простые, как последовательная линия связи, и такие сложные, как системная сетевая архитектура (SNA) компании IBM. Но сегодня протоколы TCP/IP - наиболее перспективная технология построения сетей. Это обусловлено развитием Internet и самого распространенного приложения - Всемирной паутины (World Wide Web).
Примечание: Вообще- то, Web - не приложение. Но это и не протокол, хотя в ней используются и приложения (Web-браузеры и серверы), и протоколы (например, HTTP). Web - это самое популярное среди пользователей Internet применение сетевых технологий.
Однако и до появления Web TCP/IP был распространенным методом создания сетей. Это открытый стандарт, и на его основе можно объединять машины разных производителей. К концу 90-х годов TCP/IP завоевал лидирующее положение среди сетевых технологий, видимо, оно сохранится и в дальнейшем. По этой причине в книге рассматриваются TCP/IP и сети, в которых он работает.
При желании совершенствоваться в сетевом программировании необходимо сначала овладеть некоторыми основами, чтобы в полной мере оценить, чем же вам предстоит заниматься. Рассмотрим несколько типичных проблем, с которыми сталкиваются начинающие. Многие из этих проблем - результат частичного или полного непонимания некоторых аспектов протоколов TCP/IP и тех API, с помощью которых программа использует эти протоколы. Такие проблемы возникают в реальной жизни и порождают многочисленные вопросы в сетевых конференциях.
Интерфейсы
С помощью netstat можно также получить информацию об интерфейсах. Такой пример был приведен в совете 7. Основная информация выдается при наличии опции -i:
bsd: $ netstat -i
Name Mtu Network Address Ipkts Ierrs Opkts Oerrs Coll
ed0 1500 <Link> 00.00.cO.54.53.73 40841 0 5793 0 0
ed0 1500 172.30 bsd 40841 0 5793 0 0
tun0 *1500 <Link> 397 0 451 0 0
tun0 *1500 205.184.142 205.184.142.171 397 0 451 0 0
sl0 * 552 <Link> 0 0 0 0 0
lo0 16384 <Link> 353 0 353 0 0
lo0 16384 127 localhost 353 0 353 0 0
Отсюда видно, что в машине bsd сконфигурировано четыре интерфейса. Первый– ed0- это адаптер сети Ethernet. Он входит в частную (RFC 1918 [Rekhter Moskowitz et al. 1996]) сеть 172.30.0.0. Адрес 00.00.с0.54.73 - это первый в списке МАС-адресов (media access control - контроль доступа к носителю) данной сетевой карты. Через этот интерфейс прошло 40841 входных пакетов и 5793 выходных; не было зарегистрировано ни ошибок, ни коллизий. MTU (совет 7) составляет 1500 байт - максимальное значение для сетей Ethernet.
Интерфейс tun0 - это телефонный канал, по которому связь осуществляется по протоколу РРР (Point-to-Point Protocol). Он входит в сеть 205.184.142.0. MTU для этого интерфейса также составляет 1500 байт.
Интерфейс sl0 - это телефонный канал, по которому связь осуществляется по протоколу SLIP (Serial Line Internet Protocol), RFC 1055 [Romkey 1988]. Это еще один, ныне устаревший протокол двухточечного соединения по телефонным линиям. Данный интерфейс в машине bsd не используется.
Наконец, есть еще возвратный интерфейс 1o0. О нем уже неоднократно говорилось.
В сочетании с опцией -i можно также задать опции -b или -d. Тогда будет напечатано количество байт, прошедших через интерфейс в обе стороны, или число отброшенных пакетов.
Использование select
Другой, более общий метод организации тайм-аута connect состоит в том, чтобы сделать сокет неблокирующим, а затем ожидать с помощью вызова select. При таком подходе удается избежать большинства трудностей, возникающих при попытке воспользоваться alarm, но остаются проблемы переносимости даже между разными UNIX-системами.
Сначала рассмотрим код установления соединения. В каркасе tcpclient.skel Модифицируйте функцию main, как показано в листинге 3.25.
Листинг 3.25. Прерывание connect по тайм-ауту с помощью select
connectto1.с
1 int main( int argc, char **argv )
2 {
3 fd_set rdevents;
4 fd_set wrevents;
5 fd_set exevents;
6 struct sockaddr_in peer;
7 struct timeval tv;
8 SOCKET s;
9 int flags;
10 int rc;
11 INIT();
12 set_address( argv[ 1 ], argv[ 2 ], &peer, "tcp" );
13 S = socket( AF_INET, SOCK_STREAM, 0 );
14 if ( !isvalidsock( s ) )
15 error( 1, errno, "ошибка вызова socket");
16 if( ( flags = fcntl( s, F_GETFL, 0 ) ) < 0 )
17 error( 1, errno, "ошибка вызова fcntl (F_GETFL)");
18 if ( fcntl( s, F_SETFL, flags | 0_NONBLOCK ) < 0 )
19 error( 1, errno, "ошибка вызова fcntl (F_SETFL)");
20 if ( ( rc = connect ( s, ( struct sockaddr * )&peer,
21 sizeoff peer ) ) ) && errno != EINPROGRESS )
22 error( 1, errno, "ошибка вызова connect" );
23 if ( rc == 0 ) /* Уже соединен? */
24 {
25 if ( fcntl( s, F_SETFL, flags ) < 0 )
26 error(1,errno,"ошибка вызова fcntl (восстановление флагов)”);
27 client( s, &peer );
28 EXIT( 0 );
29 }
30 FD_ZERO( &rdevents );
31 FD_SET( s, krdevents );
32 wrevents = rdevents;
33 exevents = rdevents;
34 tv.tv_sec = 5;
35 tv.tv_usec =0;
36 rc = select( s + 1, &rdevents, &wrevents, &exevents, &tv );
37 if ( rc < 0 )
38 error( 1, errno, "ошибка вызова select" );
39 else if ( rc == 0 )
40 error( 1, 0, "истек тайм-аут connect\n" );
41 else if ( isconnected( s, &rdevents, &wrevents, kexevents ))
42 {
43 if (fcntl (s, F_SETFL, flags) < 0)
44 error(1,errno,"ошибка вызова fcntl(восстановление флагов)");
45 client( s, &peer );
46 }
47 else
48 error( 1, errno, "ошибка вызова connect");
49 EXIT( 0 );
50 }
Инициализация
16- 19 Получаем текущие флаги, установленные для сокета, с помощью операции OR, добавляем к ним флаг O_NONBLOCK и устанавливаем новые флаги.
Инициирование connect
20-29 Начинаем установление соединения с помощью вызова connect. Поскольку сокет помечен как неблокирующий, connect немедленно возвращает управление. Если соединение уже установлено (это возможно, если, например, вы соединялись с той машиной, на которой запущена программа), то connect вернет нуль, поэтому возвращаем сокет в режим блокирования и вызываем функцию client. Обычно в момент Возврата из connect соединение еще не установлено, и приходит код EINPROGRESS. Если возвращается другой код, то печатаем диагностическое сообщение и завершаем программу.
Вызов select
30-36 Подготавливаем, как обычно, данные для select и, в частности, устанавливаем тайм-аут на пять секунд. Также следует объявить заинтересованность в событиях исключения. Зачем - станет ясно позже.
Обработка код возврата select
37-40 Если select возвращает код ошибки или признак завершения по тайм-ауту, то выводим сообщение и заканчиваем работу. В случае ответа можно было бы, конечно, сделать что-то другое.
41-46 Вызываем функцию isconnected, чтобы проверить, удалось ли установить соединение. Если да, возвращаем сокет в режим блокирования и вызываем функцию client. Текст функции isconnected приведен в листингах 3.26 и 3.27.
4 7-48 Если соединение не установлено, выводим сообщение и завершаем сеанс.
К сожалению, в UNIX и в Windows применяются разные методы уведомления об успешной попытке соединения. Поэтому проверка вынесена в отдельную функцию. Сначала приводится UNIX-версия функции isconnected.
В UNIX, если соединение установлено, сокет доступен для записи. Если же произошла ошибка, то сокет будет доступен одновременно для записи и для чтения. Однако на это нельзя полагаться при проверке успешности соединения, поскольку можно возвратиться из connect и получить первые данные еще до обращения к select. В таком случае сокет будет доступен и для чтения, и для записи -в точности, как при возникновении ошибки.
Листинг 3.26. UNIX-версия функции isconnected
1 int isconnected( SOCKET s, fd_set *rd, fd_set *wr, fd_set *ex )
2 {
3 int err;
4 int len = sizeoff err );
5 errno =0; /* Предполагаем, что ошибки нет. */
6 if ( !FD_ISSET( s, rd ) && !FD_ISSET( s, wr ) )
7 return 0;
8 if (getsockopt( s, SOL_SOCKET, SO_ERROR, &err, &len ) < 0)
9 return 0;
10 errno = err; /* Если мы не соединились. */
11 return err == 0;
12 }
5-7 Если сокет не доступен ни для чтения, ни для записи, значит, соединение не установлено, и возвращается нуль. Значение errno заранее установлено в нуль, чтобы вызывающая программа могла определить, что сокет действительно, не готов (разбираемый случай) или имеет Metro ошибка.
8-11 Вызываем getsockopt для получения статуса сокета. В некоторых версиях UNIX getsockopt возвращает в случае ошибки -1. В таком случае записываем в errno код ошибки. В других версиях система просто возвращает статус, оставляя его проверку пользователю. Идея кода, который корректно работает в обоих случаях, позаимствована из книги [Stevens 1998].
Согласно спецификации Winsock, ошибки, которые возвращает connect через неблокирующий сокет, индицируются путем возбуждения события исключения в select. Следует заметить, что в UNIX событие исключения всегда свидетельствует о поступлении срочных данных. Версия функции isconnected для;Windows показана в листинге 3.27.
Листинг 3.27. Windows-версия функции isconnected
1 int isconnected( SOCKET s, fd_set *rd, fd_set *wr, fd_set *ex)
2 {
3 WSASetLastError ( 0 );
4 if ( !FD_ISSET( s, rd ) && !FD_ISSET(s, wr ) )
5 return 0;
6 if ( FD_ISSET( s, ex ) )
7 return 0;
8 return 1;
9 }
3-5 Так же, как и в версии для UNIX, проверяем, соединен ли сокет. Если нет, устанавливаем последнюю ошибку в нуль и возвращаем нуль.
6-8 Если для сокета есть событие исключения, возвращается нуль, в противном случае - единица.
Использование tcpdump
Прежде всего для использования tcpdump надо получить разрешение. Поскольку применение сетевых анализаторов небезопасно, по умолчанию tcpdump конфигурируется с полномочиями суперпользователя root.
Примечание: К системе Windows это не относится. Коль скоро NDIS-драйвер для перехвата пакетов установлен, воспользоваться программой WinDump может любой.
Во многих случаях лучше дать возможность всем пользователям работать с программой tcpdump, не передавая им полномочия суперпользователя. Это делается по-разному, в зависимости от версии UNIX и документировано в руководстве по tcpdump. В большинстве случаев надо либо предоставить всем права на чтение из сетевого интерфейса, либо сделать tcpdump setuid-программой.
Проще всего вызвать tcpdump вообще без параметров. Тогда она будет перехватывать все сетевые пакеты и выводить о них информацию. Однако полезнее, указать какой-нибудь фильтр, чтобы видеть только нужные пакеты и не отвлекаться на остальные. Например, если требуются лишь пакеты, полученные от хоста bsd или отправленные ему, то можно вызвать tcpdump так:
tcpdump host bsd
Если же нужны пакеты, которыми обмениваются хосты bsd и sparc, то можно использовать такой фильтр:
host bsd and host spare
или сокращенно -
host bsd and spare
Язык для задания фильтров достаточно богат и позволяет фильтровать, например, по следующим атрибутам:
протокол;
хост отправления и/или назначения;
сеть отправления и/или назначения;
Ethernet-адрес отправления и/или назначения;
порт отправления и/или назначения;
размер пакета;
пакеты, вещаемые на всю локальную сеть или на группу (как в Ethernet так, и в IP);
пакет, используемый в качестве шлюза указанным хостом.
Кроме того, можно проверять конкретные биты или байты в заголовках протоколов. Например, чтобы отбирать только TCP-сегменты, в которых выставлен бит срочных данных, следует использовать фильтр
tcp[ 13 ] & 16
Чтобы понять последний пример, надо знать, что четвертый бит четырнадцатого байта заголовка TCP - это бит срочности.
Поскольку разрешается использовать булевские операторы and (или &&), or (или ) и not (или !) для комбинирования простых предикатов, можно задавать фильтры произвольной сложности. Ниже приведен пример фильтра, отбирающего ICMP-пакеты, приходящие из внешней сети:
icmp and not src net localnet
Примеры более сложных фильтров рассматриваются в документации по tcpdump.
Использование вызова alarm
Есть два способа прерывания connect по тайм-ауту. Самый простой - окружить этот вызов обращениями к alarm. Предположим, например, что вы не хотите ждать завершения connect более пяти секунд. Тогда можно модифицировать каркас tcpclient. skel (листинг 2.6), добавив простой обработчик сигнала и немного видоизменив функцию main:
void alarm_hndlr (int sig)
{
return;
}
int main ( int argc, char **argv )
{
…
signal ( SIGALRM, alarm_hndlr );
alarm( 5 );
rc = connect(s, ( struct sockaddr * )&peer, sizeof( peer ) )
alarm( 0 );
if ( rc < 0 )
{
if ( errno == EINTR )
error( 1, 0, "истек тайм-аут connect\n" );
…
}
Назовем программу, созданную по этому каркасу, connecto и попытаемся с помощью соединиться с очень загруженным Web-сервером Yahoo. Получите ожидаемый результат:
bsd: $ connectto yahoo.com daytime
connectto: истек тайм-аут connect спустя 5 с
bsd: $
Хотя это и простое решение, с ним связано две потенциальных проблемы. Сначала обсудим их, а потом рассмотрим другой метод - он сложнее, но лишен этих недостатков.
Прежде всего в данном примере подразумевается, что «тревожный» таймер, используемый в вызове alarm, нигде в программе не применяется, и, значит, для сигнала SIGALRM не установлен другой обработчик. Если таймер уже взведен где-то еще, то приведенный код его переустановит, поэтому старый таймер не сработает. Правильнее было бы сохранить и затем восстановить время, оставшееся до срабатывания текущего таймера (его возвращает вызов alarm), а также сохранить и восстановить текущий обработчик сигнала SIGALRM (его адрес возвращает вызов signal). Чтобы все было корректно, надо было также получить время, проведенное в вызове connect, и вычесть его из времени, оставшегося до срабатывания исходного таймера.
Далее, для упрощения вы завершаете клиент, если connect не вернул управления вовремя. Вероятно, нужно было бы предпринять иные действия. Однако надо иметь в виду, что перезапустить connect нельзя. Дело в том, что в результате вызова connect сокет остался привязанным к ранее указанному адресу, так что попытка повторного выполнения приведет к ошибке «Address already in use». При желании повторить connect, возможно, немного подождав, придется сначала закрыть, а затем заново открыть сокет, вызвав close (или closesocket) и socket.
Еще одна потенциальная проблема в том, что некоторые UNIX- системы могут автоматически возобновлять вызов connect после возврата из обработчика сигнала. В таком случае connect не вернет управления, пока не истечет тайм-аут TCP. Во всех современных вариантах системы UNIX поддерживается вызов sigaction, который можно использовать вместо signal. В таком случае следует указать, хотите ли вы рестартовать connect. Но в некоторых устаревших версиях UNIX этот вызов не поддерживается, и тогда использование alarm для прерыва ния connect по тайм-ауту затруднительно.
Если нужно вывести всего лишь диагностическое сообщение и завершить сеанс, то это можно сделать в обработчике сигнала. Поскольку это происходит до рес тарта connect, не имеет значения, поддерживает система вызов sigaction или не. Однако если нужно предпринять какие-то другие действия, то, вероятно, придется выйти из обработчика с помощью функции longjmp, а это неизбежно приводит к возникновению гонки.
Примечание: Следует заметить, что гонка возникает и в более простом случае, когда вы завершаете программу. Предположим, что соединение успешно установлено, и connect вернул управление. Однако прежде чем вы успели его отменить, таймер сработал, что привело к вызову обработчика сигнала и, следовательно, к завершению программы.
alarm( 5 };
rc = connect( s, NULL, NULL );
/* здесь срабатывает таймер */
alarm ( 0 );
Вы завершаете программу, хотя соединение и удалось установить. В первоначальном коде такая гонка не возникает, поскольку даже если таймер сработает между возвратом из connect и вызовом alarm, обработчик сигнала вернет управление, не предпринимая никаких действий.
Принимая это во внимание, многие эксперты считают, что для прерывания вызова connect по тайм-ауту лучше использовать select.
Источник и приемник на базе TCP
В совете 32 объясняется, что повысить производительность TCP можно за счет выбора правильного размера буферов передачи и приема. Нужно установить размер буфера приема для сокета сервера и размер буфера передачи для сокета клиента.
Поскольку в функциях tcp_server и tcp_client используются размеры буферов по умолчанию, следует воспользоваться не библиотекой, а каркасами из совета 4. Сообщать TCP размеры буферов нужно во время инициализации соединения, то есть до вызова listen в сервере и до вызова connect в клиенте. Поэтому невозможно воспользоваться функциями tcp_server и tcp_client, так как к моменту возврата из них обращение к listen или connect уже произошло. Начнем с клиента, его код приведен в листинге 2.18.
Листинг 2.18. Функция main TCP-клиента, играющего роль источника
1 int main ( int argc, char **argv )
2 {
3 struct sockaddr_in peer;
4 char *buf;
5 SOCKET s;
6 int с;
7 int blks = 5000;
8 int sndbufsz = 32 * 1024;
9 int sndsz = 1440; /* MSS для Ethernet по умолчанию. */
10 INIT();
11 opterr = 0;
12 while ( ( с = getopt( argc, argv, "s:b:c:" ) ) != EOF )
13 {
14 switch ( с )
15 {
16 case "s" :
17 sndsz = atoi( optarg ) ;
18 break;
19 case "b" :
20 sndbufsz = atoi( optarg ) ;
21 break;
22 case "c" :
23 blks = atoi( optarg );
2 4 break;
25 case "?" :
26 error( 1, 0, "некорректный параметр: %c\n", с );
27 }
28 }
28 if ( argc <= optind )
30 error( 1, 0, "не задано имя хоста\n" };
31 if ( ( buf = malloc( sndsz ) ) == NULL )
32 error( 1, 0, "ошибка вызова malloc\n" );
33 set_address( argv[ optind ], "9000", &peer, "tcp" );
34 s = socket( AF_INET, SOCK_STREAM, 0 );
35 if ( !isvalidsock( s ) )
36 error( 1, errno, "ошибка вызова socket" );
37 if ( setsockopt( s, SOL_SOCKET, SO_SNDBUF,
38 ( char * )&sndbufsz, sizeof( sndbufsz ) ) )
39 error( 1, errno, "ошибка вызова setsockopt с опцией SO_SNDBUF" );
40 if ( connect( s, ( struct sockaddr * )&peer,
41 sizeof( peer ) ) )
42 error( 1, errno, "ошибка вызова connect" );
43 while( blks-- > 0 )
44 send( s, buf, sndsz, 0 );
45 EXIT( 0 );
46 }
12-30 В цикле вызываем getopt для получения и обработки параметров из командной строки. Поскольку эта программа будет использоваться и далее, то делаем ее конфигурируемой в большей степени, чем необходимо для данной задачи. С помощью параметров в командной строке можно задать размер буфера передачи сокета, количество данных, передаваемых при каждой операции записи в сокет, и число операций записи.
31-42 Это стандартный код инициализации TCP-клиента, только добавлено еще обращение к setsockopt для установки размера буфера передачи, а также с помощью функции malloc выделен буфер запрошенного размера для размещения данных, посылаемых при каждой операции записи. Обратите внимание, что инициализировать память, на которую указывает buf, не надо, так как в данном случае безразлично, какие данные посылать.
43-44 Вызываем функцию send нужное число раз.
Функция main сервера, показанная в листинге 2.19, взята из стандартного каркаса с добавлением обращения к функции getopt для получения из командной строки параметра, задающего размер буфера приема сокета, а также вызов функции getsockopt для установки размера буфера.
Листинг 2.19. Функция main TCP-сервера, играющего роль приемника
tcpsink.с
1 int main( int argc, char **argv )
2 {
3 struct sockaddr_in local;
4 struct sockaddr_in peer;
5 int peerlen;
6 SOCKET s1;
7 SOCKET s;
8 int c;
9 int rcvbufsz = 32 * 1024;
10 const int on = 1;
11 INIT();
12 opterr = 0;
13 while ( ( с = getopt( argc, argv, "b:" ) ) != EOF )
14 {
15 switch ( с )
16 {
17 case "b" :
18 rcvbufsz = atoi( optarg };
19 break;
20 case ".?" :
21 error( 1, 0, "недопустимая опция: %c\n", с );
22 }
23 }
24 set_address( NULL, "9000", &local, "tcp" );
25 s = socket( AF_INET, SOCK_STREAM, 0 );
26 if ( !isvalidsock( s ) )
27 error( 1, errno, "ошибка вызова socket" ) ;
28 if ( setsockopt( s, SOL_SOCKET, SO_REUSEADDR,
29 ( char * )&on, sizeof( on ) ) )
30 error( 1, errno, "ошибка вызова setsockopt SO_REUSEADDR")
31 if ( setsockopt( s, SOL_SOCKET, SO_RCVBUF,
32 ( char * )&rcvbufsz, sizeof( rcvbufsz ) ) )
33 error( 1, errno, "ошибка вызова setsockopt SO_RCVBUF")
34 if ( bind( s, ( struct sockaddr * ) &local,
35 sizeof( local ) ) )
36. error ( 1, errno, "ошибка вызова bind" ) ;
37 listen( s, 5 );
38 do
39 {
40 peerlen = sizeof( peer );
41 s1 = accept( s, ( struct sockaddr *)&peer, &peerlen );
42 if ( !isvalidsock( s1 ) )
43 error( 1, errno, "ошибка вызова accept" );
44 server( s1, rcvbufsz );
45 CLOSE( s1 );
46 } while ( 0 );
47 EXIT( 0 );
48 }
Функция server читает и подсчитывает поступающие байты, пока не обнаружит конец файла (совет 16) или не возникнет ошибка. Она выделяет память под буфер того же размера, что и буфер приема сокета, чтобы прочитать максимальное количество данных за одно обращение к recv. Текст функции server приведен в листинге 2.20.
Листинг 2.20. Функция server
1 static void server( SOCKET s, int rcvbufsz )
2 {
3 char *buf;
4 int rc;
5 int bytes =0;
6 if ( ( buf = malloc( rcvbufsz ) ) == NULL )
7 error( 1, 0, "ошибка вызова malloc\n"};
8 for ( ; ; )
9 {
10 rc = recv( s, buf, rcvbufsz, 0 );
11 if ( rc <= 0 )
12 break;
13 bytes += rc;
14 }
15 error( 0, 0, "получено байт: %d\n", bytes );
16 }
Для измерения сравнительной производительности протоколов TCP и UDP при передаче больших объемов данных запустим клиента на машине bsd, а сервер- на localhost. Физически хосты bsd localhost - это, конечно, одно и то же, но, как вы увидите, результаты работы программы в значительной степени зависят от того, какое из этих имен использовано. Сначала запустим клиента и сервер на одной машине, чтобы оценить производительность TCP и UDP, устранив влияние сети. В обоих случаях сегменты TCP или датаграммы UDP инкапсулируются в IP-датаграммах и посылаются возвратному интерфейсу 1оО, который немедленно переправляет их процедуре обработки IP-входа, как показано на рис. 2.17.

Рис. 2.17. Возвратный интерфейс
Каждый тест был выполнен 50 раз с заданным размером датаграмм (в случае UDP) или числом передаваемых за один раз байтов (в случае TCP), равным 1440. Эта величина выбрана потому, что она близка к максимальному размеру сегмента, который TCP может передать по локальной сети на базе Ethernet.
Примечание: Это число получается так. В одном фрейме Ethernet может быть передано не более 1500 байт. Каждый заголовок IP и TCP занимает 20 байт, так что остается 1460. Еще 20 байт резервировано для опций TCP. В системе BSD TCP посылает 12 байт с опциями, поэтому в этом случае максимальный размер сегмента составляет 1448 байт.
В табл. 2.2 приведены результаты, усредненные по 50 прогонам. Для каждого протокола указано три времени: по часам - время с момента запуска до завершения работы клиента; пользовательское - проведенное программой в режиме пользователя; системное - проведенное программой в режиме ядра. В колонке «Мб/с» указан результат деления общего числа посланных байтов на время по часам. В колонке «Потеряно» для UDP приведено среднее число потерянных датаграмм.
Первое, что бросается в глаза, - TCP работает намного быстрее, когда в качестве имени сервера выбрано localhost, а не bsd. Для UDP это не так – заметной разницы в производительности нет. Чтобы понять, почему производительность TCР так возрастает, когда клиент отправляет данные хосту localhost, запустим программу netstat (совет 38) с опцией -i. Здесь надо обратить внимание на две строки (ненужная информация опущена):
Name Mtu Network Address
Ed0 1500 172.30 bsd
lo0 16384 127 localhost
Таблица 2.2. Сравнение производительности TCP и UDP при количестве посылаемых байтов, равном 1440
|
TCP |
||||||
|
Сервер |
Время по часам |
Пользовательское время |
Системное время |
Мб/с |
||
|
bsd |
2,88 |
0,0292 |
1,4198 |
2,5 |
||
|
localhost |
0,9558 |
0,0096 |
0,6316 |
7,53 |
||
|
sparс |
7,1882 |
0,016 |
1,6226 |
1,002 |
||
|
UDP |
||||||
|
Сервер |
Время по часам |
Пользовательское время |
Системное время |
Мб/с |
Потеряно |
|
|
bsd |
1,9618 |
0,0316 |
1,1934 |
3,67 |
336 |
|
|
localhost |
1,9748 |
0,031 |
1,1906 |
3,646 |
272 |
|
|
sparс |
5,8284 |
0,0564 |
0,844 |
1,235 |
440 |
|
Как видите, максимальный размер передаваемого блока (MTU - maximum transmission unit) для bsd равен 1500, а для localhost - 16384.
Примечание: Такое поведение свойственно реализациям TCP в системах, производных от BSD. Например, в системе Solaris это уже не так. При первом построении маршрута к хосту bsd в коде маршрутизации предполагается, что хост находится в локальной сети, поскольку сетевая часть IP-адреса совпадает с адресом интерфейса Ethernet. И лишь при первом использовании маршрута TCP обнаруживает, что он ведет на тот же хост и переключается на возвратный интерфейс. Однако к этому моменту все метрики маршрута, в том числе и MTU, уже установлены в соответствии с интерфейсом к локальной сети.
Это означает, что при посылке данных на localhost TCP может отправлять сегменты длиной до 16384 байт (или 16384 - 20 - 20 - 12 - 16332 байт). Однако при посылке данных на хост bsd число байт в сегменте не превышает 1448 (как было сказано выше). Но чем больше размер сегментов, тем меньшее их количество приходится посылать, а это значит, что требуется меньший объем обработки, и соответственно снижаются накладные расходы на добавление к каждому сегменту заголовков IP и TCP. А результат налицо - обмен данными с хостом localhost происходит в три раза быстрее, чем с хостом bsd.
Можно заметить, что на хосте localhost TCP работает примерно в два раза быстрее, чем UDP. Это также связано с тем, что TCP способен объединять несколько блоков по 1440 байт в один сегмент, тогда как UDP посылает отдельно каждую датаграмму длиной 1440 байт.
Следует отметить, что в локальной сети UDP примерно на 20% быстрее TCP, потеря датаграмм значительнее. Потери имеют место даже тогда, когда и сервер и клиент работают на одной машине; связаны они с исчерпанием буферов. Хотя передача 5000 датаграмм на максимально возможной скорости - это скорее отклонение, чем нормальный режим работы, но все же следует иметь в виду возможность такого результата. Это означает, что UDP не дает никакой гарантии относительно доставки данной датаграммы, даже если оба приложения работают на одной машине.
По результатам сравнения сеансов с хостами localhost и bsd можно предположить, что на производительность влияет также длина посылаемых датаграмм. Например, если прогнать те же тесты с блоком длиной 300 байт, то, как следует из табл. 2.3, TCP работает быстрее UDP и на одной машине, и в локальной сети.
Из этих примеров следует важный вывод: нельзя строить априорные предположения о сравнительной производительности TCP и UDP. При изменении условий, даже очень незначительном, показатели производительности могут очень резко измениться. Для обоснованного выбора протокола лучше сравнить их производительность на контрольной задаче (совет 8). Когда это неосуществимо на практике, все же можно написать небольшие тестовые программы для получения хотя бы приблизительного представления о том, чего можно ожидать,
Таблица. 2.3. Сравнение производительности TCP и UDP при количестве посылаемых байтов, равном 300
|
TCP |
||||||
|
Сервер |
Время по часам |
Пользовательское время |
Системное время |
Мб/с |
||
|
bsd |
1,059 |
0,0124 |
0,445 |
1,416 |
||
|
sparс |
1,5552 |
0,0084 |
1,2442 |
0,965 |
||
|
UDP |
||||||
|
Сервер |
Время по часам |
Пользовательское время |
Системное время |
Мб/с |
Потеряно |
|
|
bsd |
1,6324 |
0,0324 |
0,9998 |
0,919 |
212 |
|
|
sparс |
1,9118 |
0,0278 |
1,4352 |
0,785 |
306 |
|
Примечение: 29 июля 1999 года исследователи из Университета Дъюка на рабочей станции ХР1000 производства DEC/Compaq на базе процессора Alpha в сети Myrinet получили скорости передачи порядка гигабита в секунду. В экспериментах использовался стандартный стек TCP/IP из системы FreeBSD 4.0, модифицированный по технологии сокетов без копирования (zero-copy sockets). В том же эксперименте была получена скорость более 800 Мбит/с на персональном компьютере PII 450 МГц и более ранней версии сети Myrinet. Подробности можно прочитать на Web-странице http://www.cs.duke.edu/ari/trapeze.
Источник и приемник на базе UDP
В случае UDP клиент посылает нефиксированное количество датаграмм, которые сервер читает, подсчитывает и отбрасывает. Исходный текст клиента приведен в листинге 2.16.
Листинг 2.16. UDP-клиент, посылающий произвольное число датаграмм
1 #include "etcp.h"
2 int main( int argc, char **argv )
3 {
4 struct sockaddr_in peer;
5 SOCKET s;
6 int rc;
7 int datagrams;
8 int dgramsz = 1440;
9 char buf[ 1440 ];
10 INIT();
11 datagrams = atoi( argv[ 2 ] );
12 if ( argc > 3 )
13 dgramsz = atoi( argv [ 3 ] );
14 s = udp_client( argv[ 1 ], "9000", &peer );
15 while ( datagrams-- > 0 )
16 {
17 rc = sendto( s, buf, dgramsz, 0,
18 ( struct sockaddr * )&peer, sizeof( peer ) );
19 if ( rc <= 0 )
20 error( 0, errno, "ошибка вызова sendto" );
21 }
22 sendto( s, "", 0, 0,
23 ( struct sockaddr * )&peer, sizeof( peer ) );
24 EXIT( 0 );
25 }
10-14 Читаем из командной строки количество посылаемых датаграмм и их размер (второй параметр необязателен). Подготавливаем в переменной peer UDP-сокет с адресом сервера. Вопреки совету 29 номер порта 9000 жестко «зашит» в код.
15-21 Посылаем указанное количество датаграмм серверу.
22-23 Посылаем серверу последнюю датаграмму, содержащую нулевой байт. Для сервера она выполняет роль конца файла.
Текст сервера в листинге 2.17 еще проще.
Листинг 2.17. Приемник датаграмм
1 #include "etcp.h"
2 int main( int argc, char **argv )
3 {
4 SOCKET s;
5 int rc;
6 int datagrams = 0;
7 int rcvbufsz = 5000 * 1440;
8 char buf[ 1440 ];
9 INIT();
10 s = udp_server( NULL, "9000" );
11 setsockopt ( s, SOL_SOCKET, SO_RCVBUF,
12 ( char * )&rcvbufsz, sizeof( int ) ) ;
13 for ( ;; )
14 {
15 rc = recv( s, buf, sizeof( buf ), 0 );
16 if ( rc <= 0 )
17 break;
18 datagrams++;
19 }
20 error( 0, 0, "получено датаграмм: %d \n", datagrams );
21 EXIT( 0 ) ;
22 }
10 Подготавливаем сервер к приему датаграмм из порта 9000 с любого интерфейса.
11-12 Выделяем память для буфера на 5000 датаграмм длиной до 1440 байт.
Примечание: Здесь устанавливается размер буфера 7200000 байт, но нет гарантии, что операционная система выделит столько памяти. Хост, работающий под управлением системы BSD, выделил буфер размером 41600 байт. Этим объясняется потеря датаграмм, которая будет рассмотрена далее.
13-19 Читаем и подсчитываем датаграммы, пока не придет пустая датаграмма или не произойдет ошибка.
20 Выводим число полученных датаграмм на stdrerr.
Элементы API сокетов
В этом разделе кратко рассмотрены основы API сокетов и построены простейшие 11 клиентское и серверное приложения. Хотя эти приложения очень схематичны, на их примере проиллюстрированы важнейшие характеристики клиента и сервера TCP.
Начнем с вызовов API, необходимых для простого клиента. На рис. 1.2 показаны функции, применяемые в любом клиенте. Адрес удаленного хоста задается с помощью структуры sockaddr_in, которая передается функции connect.
Первое, что вы должны сделать, - это получить сокет для логического соединения. Для этого предназначен системный вызов socket.
#include <sys/socket.h> /* UNIX */
#include <winsock2.h> /* Windows */
SOCKET socket( int domain, int type, int protocol);
Возвращаемое значение: дескриптор сокета в случае успеха; —1 (UNIX) или INVALID_SOCKET (Windows) - ошибка.
API сокетов не зависит от протокола и может поддерживать разные адресные домены. Параметр domain - это константа, указывающая, какой домен нужен сокету.
Чаще используются домены AF_INET (то есть Internet) и AF_LOCAL (или AF_UNIX). В книге рассматривается только домен AF_INET. Домен AF_LOCAL применяется для межпроцессного взаимодействия (IPC) на одной и той же машине.
Примечание: Существуют разногласия по поводу того, следует ли обозначать константы доменов AF_* или PF_*. Сторонники PF_* указывают на их происхождение от уже устаревших вариантов вызова socket в системах 4.1c/2.8/2.9BSD. И, кроме того, они считают, то PF означает protocol family (семейство протоколов). Сторонники же AF_* говорят, что в коде ядра, относящемся к реализации сокетов, параметр domain сравнивается именно с константами AF_*. Но, поскольку оба набора констант определены одинаково действительности одни константы просто выражаются через другие, — на практике можно употреблять оба варианта.
С помощью параметра type задается тип создаваемого сокета. Чаще встречаются следующие значения (а в этой книге только такие) сокетов:
SOCK_STREAM - обеспечивают надежный дуплексный протокол на основе установления логического соединения. Если говорится о семействе протоколов TCP/IP, то это TCP;
SOCK_DGRAM - обеспечивают ненадежный сервис доставки датаграмм. В рамках TCP/IP это будет протокол UDP;
SOCK_RAW -предоставляют доступ к некоторым датаграммам на уровне протокола IP Они используются в особых случаях, например для просмотра всех ICMP- сообщений.

Рис. 1.2. Основные вызовы API сокетов для клиентов
Параметр protocol показывает, какой протокол следует использовать с данным сокетом. В контексте TCP/IP он обычно неявно определяется типом сокета, поэтому в качестве значения задают 0. Иногда, например в случае простых (raw) сокетов, имеется несколько возможных протоколов, так что нужный необходимо задавать явно. Об этом будет рассказано в совете 40.
Для самого простого TCP-клиента потребуется еще один вызов API сокетов, обеспечивающий установление соединения:
#include <sys./socket.h> /* UNIX */
#include <winsock2.h> /* Windows */
int connect(SOCKET s, const struct sockaddr *peer, int peer_len);
Возвращаемое значение: 0 - нормально, -1 (UNIX) или не 0 (Windows) - ошибка.
Параметр s — это дескриптор сокета, который вернул системный вызов socket. Параметр peer указывает на структуру, в которой хранится адрес удаленного хоста и некоторая дополнительная информация. Для домена AF_INET - это структура типа sockaddr_in. Ниже вы увидите, как она заполняется. Параметр peer_len содержит размер структуры в байтах, на которую указывает peer.
После установления соединения можно передавать данные. В ОС UNIX вы должны обратиться к системным вызовам read и write и передать им дескриптор сокета точно так же, как передали бы дескриптор открытого файла. Увы, как уже говорилось, в Windows эти системные вызовы не поддерживают семантику сокетов, поэтому приходится пользоваться вызовами recv и send. Они отличаются от read и write только наличием дополнительного параметра.
#include <sys/socket.h> /*UNIX*/
#include <winsock2.h> /*Windows*/
int recv(SOCKET s, void *buf, size_t left, int flags);
int send(SOCKET s, const void *buf, size_t len, int flags);
Возвращаемое значение: число принятых или переданных байтов в случае успеха или -1 в случае ошибки.
Параметры s, buf и len означают то же, что и для вызовов read и write. Значение параметра flags в основном зависит от системы, но и UNIX, и Windows поддерживают следующие флаги:
MSG_OOB - следует послать или принять срочные данные;
MSG_PEEK - используется для просмотра поступивших данных без их удаления из приемного буфера. После возврата из системного вызова данные еще могут быть получены при последующем вызове read или recv;
MSG_DONTROUTE - сообщает ядру, что не надо выполнять обычный алгоритм маршрутизации. Как правило, используется программами маршрутизации или для диагностических целей.
При работе с протоколом TCP вам ничего больше не понадобится. Но при работе с UDP нужны еще системные вызовы recvfrom и sendto. Они очень похожи на recv и send, но позволяют при отправке датаграммы задать адрес назначения, а при приеме - получить адрес источника.
#include <sys/socket.h> /*UNIX*/
#include <winsock2.h> /*Windows*/
int recvfrom(SOCKET s, void *buf, size_t len, int flags,
struct sockaddr *from, int *fromlen);
int sendto(SOCKET s, const void *buf, size_t len, int flags,
const struct sockaddr *to, int tolen);
Возвращаемое значение: число принятых или переданных байтов в случае успеха или -1 при ошибке.
Первые четыре параметра - s, buf, len к flags - такие же, как в вызовах recv и send. Параметр from в вызове recvfrom указывает на структуру, в которую ядро помещает адрес источника пришедшей датаграммы. Длина этого адреса хранится в целом числе, на которое указывает параметр fromlen. Обратите внимание, что fromlen - это указатель на целое.
Аналогично параметр to в вызове sendto указывает на адрес структуры, содержащей адреса назначения датаграммы, а параметр tolen - длина этого адреса. Заметьте, что to - это целое, а не указатель.
В листинге 1.1 приведен пример простого TCP-клиента.
Листинг 1.1. Простейший TCP-клиент
1 #include <sys/types .h>
2 #include <sys/socket .h>
3 #include <netinet/in.h>
4 #include <arpa/inet. h>
5 #include <stdio.h>
6 int main( void )
7 {
8 struct sockaddr_in peer;
9 int s ;
10 int rc;
11 char buf [ 1 ];
12 peer. sin_family = AF_INET;
13 peer.sin_port = htons( 7500 );
14 peer.sin_addr.s_addr = inet_addr( "127.0.0.1" );
15 s = socket ( AF_INET, SOCK_STREAM, 0 );
16 if (s < 0)
17 {
18 perror( "ошибка вызова socket" );
19 exit ( 1 );
20 }
21 rc = connect( s, ( struct sockaddr * )&peer, sizeof( peer ) );
22 if (rc)
23 {
24 perror( "ошибка вызова connect" );
25 exit( 1 )
26 }
27 rc = send( s, "1", 1, 0 );
28 if (rc <= 0)
29 {
30 perror( "ошибка вызова send" ) ;
31 exit ( 1 ) ;
32 }
33 rc = recv( s, buf, 1, 0 ) ;
34 if ( rc <= 0 )
35 perror ( "ошибка вызова recv"' );
36 else
37 printf( "%c\n", buf[ 0 ] );
38 exit( 0 );
39 }
Клиент в листинге 1.1 написан как UNIX-программа, чтобы не было сложностей, связанных с переносимостью и Windows-функцией WSAStartup. В совете 4 сказано, что в основном эти сложности можно скрыть в заголовочном файле, но сначала надо подготовить некоторые механизмы. Пока ограничимся более простой моделью UNIX.
Подготовка адреса сервера
12-14 Заполняем структуру sockaddr_in, заплывая в ее поля номер порта (7500) и адрес. 127.0.0.1 - это возвратный адрес, который означает, что сервер находится на той же машине, что и клиент.
Получение сокета и соединение с сервером
15-20 Получаем сокет типа SOCK_STREAM. Как было отмечено выше, протокол TCP, будучи потоковым, требует именно такого сокета.
21-26 Устанавливаем соединение с сервером, обращаясь к системному вызову connect. Этот вызов нужен, чтобы сообщить ядру адрес сервера.
Отправка и получение одного байта
27- 38 Сначала посылаем один байт серверу, затем читаем из сокета один байт и записываем полученный байт в стандартный вывод и завершаем сеанс.
Прежде чем тестировать клиента, необходим сервер. Вызовы API сокетов для сервера немного иные, чем для клиента. Они показам на рис. 1.3.
Сервер должен быть готов к установлению соединений с клиентами. Для этого он обязан прослушивать известный ему порт с помощью системного вызова listen. Но предварительно необходимо привязан адрес интерфейса и номер порта к прослушивающему сокету. Для этого предназначен вызов bind:
#include <sys/socket.h> /* UNIX */
#include <winsock2.h> /* Windows */
int bind(SOCKET s, const struct sockaddl *name, int namelen);
Возвращаемое значение: 0 - нормально, -1 (UNIX) или SOCKET_ERROR (Windows) - ошибка.
Параметр s - это дескриптор прослушивающег сокета. С помощью параметров name и namelen передаются порт и сетевой интерфейс, которые нужно прослушивать. Обычно в качестве адреса задается консанта INADDR_ANY. Это означает, что будет принято соединение, запрашиваемое по любому интерфейсу. Если хосту с несколькими сетевыми адресами нужно принимать соединения только по одному интерфейсу, то следует указать IP-адрес этого интерфейса. Как обычно, namelen - длина структуры sockaddr_in.
После привязки локального адреса к сокету нужно перевести сокет в режим прослушивания входящих соединений с помощью системного вызова listen, назначение которого часто не понимают. Его единственная задача - пометить сокет как прослушивающий. Когда хосту поступает запрос на установление соединения, ядро ищет в списке прослушивающих сокетов тот, для которого адрес назначения и номер порта соответствуют указанным в запросе.
#include <sys/socket.h> /* UNIX */
#include <winsock2.h> /* Windows */
int listen( SOCKET s, int backlog);
Возвращаемое значение: О - нормально, -1 (UNIX) или SOCKET_ERROR (Windows) - ошибка.
Параметр s - это дескриптор сокета, который нужно перевести в режим прослушивания. Параметр backlog - это максимальное число ожидающих, но еще не принятых соединений. Следует отметить, что это не максимальное число одновременных соединений с данным портом, а лишь максимальное число частично установленных соединений, ожидающих в очереди, пока приложение их примет (описание системного вызова accept дано ниже).

Рис. 1.3. Основные вызовы API сокетов для сервера
Традиционно значение параметра backlog не более пяти соединений, но в современных реализациях, которые должны поддерживать приложения с высокой нагрузкой, например, Web-сервера, оно может быть намного больше. Поэтому, чтобы выяснить его истинное значение, необходимо изучить документацию по конкретной системе. Если задать значение, большее максимально допустимого, то система уменьшит его, не сообщив об ошибке.
И последний вызов, который будет здесь рассмотрен, - это accept. Он служит для приема соединения, ожидающего во входной очереди. После того как соединение принято, его можно использовать для передачи Данных, например, с помощью вызовов recv и send. В случае успеха accept возвращает дескриптор нового сокета, по которому и будет происходить обмен данными. Номер локального порта для этого сокета такой же, как и для прослушивающего сокета. Адрес интерфейса, на который поступил запрос о соединении, называется Локальным. Адрес и номер порта клиента считаются удаленными.
Обратите внимание, что оба сокета имеют один и тот же номер локального порта. Это нормально поскольку TCP-соединение полностью определяется четырьмя параметрами - локальным адресом, локальным портом, удаленным адресом и удаленным портом. Поскольку удаленные адрес и порт для этих двух сокетов различны, то ядро может отличить их друг от друга.
#include <sys/socket.h> /* UNIX */
#include <winsock2.h> /* windows */
int accept (SOCKET s, struct sockaddr *addr, int *addrlen);
Возвращаемое значение: 0- нормально, -1 (UNIX) или INVALID_SOCKET (Windows) - ошибка
Параметр s – это дескриптор прослушивающего сокета. Как показано на рис. 1.3, accept возвращает адрес приложения на другом конце соединения в структуре sockaddr_in, на которую указывает параметр addr. Целому числу, на которое указывает параметр addrlen, ядро присваивает значение, равное длине этой структуры. Часто нет необходимости знать адрес клиентского приложения, поэтому в качестве add и addrlen будет передаваться NULL.
В листинге 1. 2 приведен простейший сервер. Эта программа также очень схематична, поскольку ее назначение - продемонстрировать структуру сервера и элементарные вызовы API сокетов, которые обязан выполнить любой сервер. Обратите внимание что как и в случае с клиентом на рис. 1.2, сервер следует потоку управления, годному на рис. 1.3.
Листинг 1.2. Простой TCP-сервер
1 #include <sys/types.h>
2 #include <sys/socket.h>
3 #include <netinet/in.h>
4 #include <stdio.h>
5 int main (void)
6 {
7 struct sockaddr_in local;
8 int s;
9 int s1;
10 int rc;
11 char buf [ 1 ];
12 local.sin_family = AF_INET;
13 local.sin_port = htons( 7500 ) ;
14 local.sin_addr.s_ addr = htonl ( INADDR_ANY );
15 s = socket ( AF_INET, SOCK_STREAM, 0 );
16 if ( s < 0 )
17 {
18 perror("ошибка вызова socket" );
19 exit ( 1 );
20 }
21 rc = bind( s, ( struct sockaddr * )&local, sizeof ( local ) );
22 if ( rc < 0 )
23 {
24 perror ( "ошибка вызова bind" );
25 exit ( 1 );
26 }
27 rc = listen( s, 5 );
28 if ( rc )
29 {
30 perror ( "ошибка вызова listen" );
31 exit ( 1 );
32 }
33 s1 = accept( s, NULL, NULL );
34 if ( s1 < 0 )
35 {
36 perror ( "ошибка вызова accept" );
37 exit ( 1 );
38 }
39 rc = recv( s1, buf, 1, 0 );
40 if ( rc <= 0 )
41 {
42 perror( "ошибка вызова recv" );
43 exit ( 1 );
44 }
45 printf( "%c\n", buf[ 0 ] );
46 rc = send( s1, "2", 1, 0 );
47 if ( rc <= 0 )
48 perror( "ошибка вызова send" );
49 exit ( 0 )
50 }
Заполнение адресной структуры и получение сокета
12- 20 Заполняем структуру sockaddr_in, записывая в ее поля известные адресе и номер порта, получаем сокет типа SOCK_STREAM, который и будет прослушивающим.
Привязка известного порта и вызов listen
21-32 Привязываем известные порт и адрес, записанные в структуру local, к полученному сокету. Затем вызываем listen, чтобы пометить сокет как прослушивающий.
Принятие соединения
33-39 Вызываем accept для приема новых соединений. Вызов accept блокирует выполнение программы до тех пор, пока не поступит запрос на соединение, после чего возвращает новый сокет для этого соединения.
Обмен данными
39-49 Сначала читаем и печатаем байт со значением 1, полученный от клиента. Затем посылаем один байт со значением 2 назад клиенту и завершаем программу.
Теперь можно протестировать клиент и сервер, запустив сервер в одном окне, а клиент - в другом. Обратите внимание, что сервер должен быть запущен первым, иначе клиент аварийно завершится с сообщением Connection refused (В соединении отказано).
bsd: $ simplec
ошибка вызова connect: Connection refused
bsd: $
Ошибка произошла потому, что при попытке клиента установить соединение не было сервера, прослушивающего порт 7500.
Теперь следует поступить правильно, то есть запустить сервер до запуска клиента:
|
bsd: $ simples 1 bsd: $ |
bsd: $ simplec 2 bsd: $ |
Как работает tcpdump
Посмотрим, как работает программа t cpdump и на каком уровне протоколов она перехватывает пакеты. Как и большинство сетевых анализаторов, tcpdump состоит из двух компонент: первая работает в ядре и занимается перехватом и, возможно фильтрацией пакетов, а вторая действует в адресном пространстве пользователя и определяет интерфейс пользователя, а также выполняет форматирование и фильтрацию пакетов, если последнее не делается ядром.
Пользовательская компонента tcpdump взаимодействует с компонентой в ядре при помощи библиотеки libpcap (библиотека для перехвата пакетов), которая абстрагирует системно-зависимые детали общения с канальным уровнем стека протоколов. Например, в системах на основе BSD libpcap взаимодействует с пакетным фильтром BSD (BSD packet filter - BPF) [McCanne and Jacobson 1993]. BPF исследует каждый пакет, проходящий через канальный уровень, и сопоставляет его с фильтром, заданным пользователем. Если пакет удовлетворяет критерию фильтрации, то его копия помещается в выделенный ядром буфер, который ассоциируется с данным фильтром. Когда буфер заполняется или истекает заданный пользователем тайм-аут, содержимое буфера передается приложению с помощью libpcap.
Этот процесс изображен на рис. 4.4. Показано, как tcpdump и любая другая программа считывают необработанные пакеты с помощью BPF, а также изображено еще одно приложение, читающее данные из стека TCP/IP, как обычно.
Примечание: Хотя на этом рисунке и tcpdump, и программа используют библиотеку libpcap, можно напрямую общаться с ВРF или иным интерфейсом, о чем будет сказано ниже. Достоинство libpcap в том, что она предоставляет системно-независимые средства доступа к необработанным пакетам. В настоящее время эта библиотека поддерживает BPF; интерфейс канального провайдера (data link provider interface – DLPI); систему SunOS NIT; потоковую NIT; сокеты типа SOCK_PACKET, применяемые в системе Linux; интерфейс snoop (IRIX) и разработанный в Стэнфордском университете интерфейс enet. В дистрибутив WinDump входит также версия libpcap для Windows.
Обратите внимание, что BPF перехватывает сетевые пакеты на уровне драйвера устройства, то есть сразу после того, как они считаны с носителя. Это не то же самое что чтение из простого сокета. В ситуации с простым сокетом вы получаете IР-датаграммы, уже обработанные уровнем IP и переданные непосредственно приложению минуя транспортный уровень (TCP или UDP). Об этом рассказывается в совете 40.
Начиная с версии 2.0, архитектура WinDump очень напоминает используемую в системах BSD. Эта программа пользуется специальным NDIS-драйвером (NDIS- Network Driver Interface Specification - спецификация стандартного интерфейса сетевых адаптеров), предоставляющим совместимый с BPF фильтр и интерфейс. В архитектуре WinDump NDIS-драйвер фактически представляет собой часть стека протоколов, но функционирует он так же, как показано на рис. 4.4, только надо заменить BPF на пакетный драйвер NDIS.

Рис. 4.4. Перехват пакетов с помощью BPF
Другие операционные системы используют несколько иные механизмы. В системах, производных от SVR4, для доступа к простым сокетам применяется интерфейс DLPI [Unix International 1991]. DLPI - это не зависящий от протокола, основанный на системе STREAMS [Ritchie 1984] интерфейс к канальному уровню, С помощью DLPI можно напрямую получить доступ к канальному уровню, но по соображениям эффективности обычно вставляют в поток STREAMS-модули pfmod и bufmod. Модуль bufmod предоставляет услуги по буферизации сообщений и увеличивает эффективность за счет ограничения числа контекстных переключений, требуемых для доставки данных.
Примечание: Это аналогично чтению полного буфера из сокета вместо побайтного чтения.
Модуль pfmod - это фильтр, аналогичный BPF. Поскольку он несовместим с фильтром BPF, tcpdump вставляет этот модуль в поток, а фильтрацию выполняет в пространстве пользователя. Это не столь эффективно, как при использовании BPF, так как в пространство пользователя приходится передавать каждый пакет, даже если он не нужен программе tcpdump.
На рис. 4.5 показаны tcpdump без модуля pf mod и приложение, которое получает необработанные пакеты с использованием находящегося в ядре фильтра.
На рис. 4. 5 также представлены приложения, пользующиеся библиотекой libpcap, но, как и в случае BPF, это необязательно. Для отправки сообщений непосредственно в поток и получения их обратно можно было бы воспользоваться вызовами getmsg и putmsg. Книга [Rago 1993] - отличный источник информации о программировании системы STREAMS, DLPI и системных вызовах getmsg и putmsq. Более краткое обсуждение вопроса можно найти в главе 33 книги [Stevens 1998].

Рис. 4.5. Перехват пакетов с помощью DLPI
Наконец, есть еще и архитектура Linux. В этой системе доступ к необработанным сетевым пакетам производится через интерфейс сокетов типа SOCK_PACKET. Для использования этого простого механизма надо открыть подобный сокет, привязать к нему требуемый сетевой интерфейс, включить режим пропускания всех пакетов (promiscuous mode) и читать из сокета.
Примечание: Начиная с версии 2.2 ядра Linux, рекомендуется несколько другой интерфейс, но последняя версия libpcap по-прежнему поддерживает описанный выше.
Например, строка
s = socket( AF_INET, SOCK_PACKET, htons( ETH_P_ALL ) );
открывает сокет, предоставляющий доступ ко всем Ethernet-пакетам. В качестве третьего параметра можно также указать ЕТН_Р_IР (пакеты IP), ETH_P_IPV6 (пакеты IPv6) или ETH_P_ARP (пакеты ARP). Будем считать, что этот интерфейс аналогичен простым сокетам (SOCK_RAW), только доступ производится к канальному, а не сетевому (IP) уровню.
К сожалению, несмотря на простоту и удобство этого интерфейса, он не очень эффективен. В отличие от обычных сокетов, ядро в этом случае не осуществляет никакой буферизации, так что каждый пакет доставляется приложением сразу после поступления. Отсутствует также фильтрация на уровне ядра (если не считать параметра ЕТН_Р_* ). Поэтому фильтровать приходится на прикладном уровне, а это означает, что приложение должно получать все пакеты без исключения.
Как работает traceroute
А теперь разберемся, как работает traceroute. Вспомним (совет 22), что в IP-датаграмме есть поле TTL, которое уменьшается на единицу каждым промежуточным
bsd: $ traceroute panther.cs.ucla.edu
traceroute to panther.cs-ucla.edu (131.179.128.25),
30 hops max, 40 bytes packets
1 tam-f1-pm8.netcom.net (163.179.44.15)
178.957 ms 129.049 ms 129.585 ms
2 tam-f1-gw1.netcom.net (163.179.44.254)
1390435 ms 139.258 ms 139.434 ms
3 h1-0.mig-f1-gw1.netcom.net (165.236.144.110)
139.538 ms 149.202 ms 139.488 ms
4 a5-0-0-7.was-dc-gw1.netcom.net (163.179.235.121)
189.535 ms 179.496 ms 168.699 ms
5 h2-0.mae-east.netcom.net (163.179.136.10)
180.040 ms 189.308 ms 169.479 ms
6 cpe3-fddi-0.Washington.cw.net (192.41.177.180)
179.186 ms 179.368 ms 179.631 ms
7 core5-hssi6-0-0.Washington.cw.net (204.70.1.21)
199.268 ms 179.537 ms 189.694 ms
8 corerouter2.Bloomington.cw.net (204.70.9.148)
239.441 ms 239.560 ms 239.417 ms
9 bordercore3.Bloomington.cw.net (166.48.180.1)
239.322 ms 239.348 ms 249.302 ms
10 ucla-internet –t-3.Bloomington.cw.net (166.48.181.254)
249.989 ms 249.384 ms 249.662 ms
11 cbn5-t3-1.cbn.ucla.edu (169.232.1.34)
258.756 ms 259.370 ms 249.487 ms
12 131.179.9.6 (131.179.9.6) 249.457 ms 259.238 ms 249.666 ms
13 Panther.CS.UCLA.EDU (131.179.128.25) 259.256 ms 259.184 ms*
bsd: $
Рис. 4.8. Маршрут до хоста panther.cs.ucla.edu, прослеженный traceroute
маршрутизатором. Когда маршрутизатор получает датаграмму, у которой в поле TTL находится единица (или нуль), он отбрасывает ее и посылает отправителю ICМР-сообщение «истекло время в пути».
Программа traceroute использует это свойство. Сначала она посылает получателю UDP-датаграмму, в которой TTL установлено в единицу. Когда датаграмма доходит до первого маршрутизатора, тот определяет, что поле TTL равно единице, отбрасывает датаграмму и посылает отправителю ICМР-сообщение. как вы узнаете адрес первого промежуточного узла (из поля «адрес отправителя» в заголовке ICMP). И traceroute пытается выяснить его имя с помощью Функции gethostbyaddr. Чтобы получить информацию о втором узле, traceroute Повторяет процедуру, на этот раз установив TTL равным двум. Маршрутизатор в первом промежуточном узле уменьшит TTL на единицу и отправит датаграмму Дальше. Но второй маршрутизатор определит единицу в поле TTL, отбросит датаграмму и пошлет ICМР-сообщение отправителю. Повторяя эти действия, но увеличивая каждый раз значение TTL, traceroute может построить весь маршрут От отправителя к получателю.

Рис. 4.9. Маршрутизатор N ошибочно переправляет датаграмму с TTL, равным нулю
Когда датаграмма с достаточно большим начальным значением TTL наконец доходит до получателя, TTL будет равно единице, но, поскольку дальше переправлять датаграмму некуда, стек TCP/IP попытается доставить ее ожидающему приложению. Однако traceroute установлено в качестве порта назначения такое значение, которое вряд ли кем-то используется, поэтому хост-получатель вернет ICMP-сообщение «порт недоступен». Получив такое сообщение, tracerout определяет, что конечный получатель обнаружен, и трассировку можно завершить.
Поскольку протокол UDP ненадежен (совет 1), не исключена возможность потери датаграмм. Поэтому traceroute пытается «достучаться» до каждого промежуточного хоста или маршрутизатора несколько раз, то есть посылает несколько датаграмм с одним и тем же значением TTL. По умолчанию делается три попытки, но это можно изменить с помощью опции -q.
Кроме того, tracerout нужно определить, сколько времени ждать IСМР- сообщения после каждой попытки. По умолчанию время ожидания - 5 с, но это значение можно изменить с помощью опции -w. Если в течение этого времени IСМР-сообщение не получено, то вместо значения RTT печатается звездочка (*).
В описанном процессе могут быть некоторые трудности: traceroute полагается на то, что маршрутизаторы будут, как положено, отбрасывать IP-датаграммы, в которых TTL равно единице, и посылать при этом ICMP-сообщение «истекло время в пути». К сожалению, некоторые маршрутизаторы таких сообщений не посылают, и тогда печатаются звездочки. Есть также маршрутизаторы, которые посылают сообщение, но с тем значением TTL, которое обнаружили во входящей датаграмме. Поскольку оно оказалось равным нулю, то датаграмма будет отброшена первым узлом на обратном пути (если, конечно, это не случилось на первом шаге). Результате точно такой же, как если бы ICMP-сообщение не посылалось вовсе.
Некоторые маршрутизаторы ошибочно переправляют далее датаграммы, в которых TTL равно нулю. Если такое происходит, то следующий маршрутизатор, например N + 1, отбросит датаграмму и вернет ICMP-сообщение «истекло врем в пути». На дальнейшей итерации маршрутизатор N + 1 получит датаграмму со значением TTL, равным единице, и вернет обычное ICMP-сообщение. Таким образом, маршрутизатор N + 1 появится дважды: первый раз в результате ошибки предыдущего маршрутизатора, а второй - после корректного отбрасывания датаграммы с истекшим временем работы. Такая ситуация изображена на рис. 4.9, а ее видимое проявление - в строках, соответствующих узлам 5 и 6 на рис. 4.10.
bed: $ traceroute syrup.hill.com
traceroute to syrup.hil1.corn (208.162.106.3),
30 hops max, 40 byte packets
1 tam-fl-pm5.netcom.net (163.179.44.11)
129.120 ms 139.263 ms 129.603 ms
2 tarn-fl-gwl.netcom.net (163.179.44.254)
29.584 ms 129.328 ms 149.578 ms
3 hl-O.mig-fl-gwl.netcom.net (165.236.144.110)
219.595 ms 229.306 ms 209.602 ms
4 a5-0-0-7.was-dc-gwl.netcom.net (163.179.235.121)
179.248 ms 179.521 ms 179.694 ms
5 h2-0.mae-east.netcom.net (163.179.136.10)
179.274 ms 179.325 ms 179.623 ms
6 h2-0.mae-east.netcom.net (163.179.136.10)
169.443 ms 199.318 ms 179.601 ms
7 cpe3-fddi-0.washington.cw.net (192.41.177.180) 189.529 ms
core6-seria!5-l-0.Washington.cw.net
(204.70.1.221) 209.496 ms 209.247 ms
8 bordercore2.Boston.cw.net (166.48.64.1)
209.486 ms 209.332 ms 209.598 ms
9 hill-associatesinc-internet.Boston.cw.net (166.48.67.54)
229.602 ms 219.510 ms *
10 syrup.hill.corn (208.162.106.3) 239.744 ms 239.348 m 219.607 ms
bsd: $
Рис. 4.10. Выдача traceroute с повторяющимися узлами
На рис. 4.10 показано еще одно интересное явление. Вы видите, что в узле 7 маршрут изменился после первой попытки. Возможно, это было вызвано тем, что маршрутизатор в узле 6 выполнил какие-то действия по балансированию нагрузки. А возможно, что узел среЗ-fddi-0 .washington.cw.net за время, прошедшее с момента первой попытки, успел «отключиться», и вместо него был использован маршрутизатор с адресом core6-serial5-l-0.Washington.cw.net.
Еще одна проблема, встречающаяся, к сожалению, все чаще, состоит в том, что маршрутизаторы полностью блокируют все ICMP-сообщения. Некоторые организации, ошибочно полагая, что ICMP-сообщения несут какую-то опасность, отключают их. В таких условиях traceroute становится бесполезной, поскольку первый же такой узел, встретившийся на маршруте к получателю, с точки зрения traceroute Ведет себя как «черная дыра». Никакая информация от последующих узлов не доходит, так как этот маршрутизатор отбрасывает и сообщение «истекло время в пути», и сообщение «порт недоступен».
Следующая проблема при работе с traceroute - это асимметрия маршрутов. Запуская traceroute, вы получаете маршрут от пункта отправления до пункта назначения, но нет гарантии, что датаграмма, отправленная из пункта назначении будет следовать тем же маршрутом. Хотя кажется естественным предположении о том, что почти все маршруты одинаковы, в действительности, как показано в работе [Paxson 1997], 49% изученных маршрутов демонстрируют асимметрию хотя бы в одном промежуточном узле.
Примечание: С помощью опции -s, которая устанавливает режим свободной маршрутизации, заданной источником (loose source routing) oт пункта назначения в пункт отправления, теоретически можно получить оба маршрута. Но, как отмечает Джекобсон в комментариях к исходному тексту trace-route, количество маршрутизаторов, которые некорректно выполняют маршрутизацию, заданную источником, настолько велико, что этот метод на практике не работает. В главе 8 книги [Stevens 1994] объясняетсясуть метода и приводится пример его успешного применения.
В другой работе Паксон отмечает, что асимметричные маршруты возникают также из-за эффекта «горячей картофелины» [Paxson 1995].
Примечание: Этот эффект состоит в следующем. Предположим, что хост А, расположенный на восточном побережье Соединенных Штатов, отправляет датаграмму хосту В на западном побережье. Хост А подключен к Internet через провайдера 1, а хост В - через провайдера 2. Допустим, что у обоих провайдеров есть опорные сети, проходящие через всю страну. Поскольку полоса пропускания опорной сети - это дефицитный ресурс, провайдер 1 пытается доставить датаграмму хосту в сети провайдера 2, пользуясь его же опорной сетью. Но точно также, когда хост В отвечает, провайдер 2 пытается доставить ответ на противоположное побережье, пользуясь опорной сетью провайдера 1. Отсюда и асимметрия.
Каркас TCP-клиента
Рассмотрим каркас приложения TCP-клиента (листинг 2.6). Если не считать Функции main и замены заглушки server заглушкой client, то код такой же, как для каркаса TCP-сервера.
Листинг 2.6. Функция main из каркаса tcpclientskel
tcpclient. skel
1 int main( int argc, char **argv )
2 {
3 struct sockaddr_in peer;
4 SOCKET s;
5 INIT ( ) ;
6 set_address(argv[ 1 ], argv[ 2 ], &peer, "tcp");
7 s = socket( AF_INET, SOCK_STREAM, 0 );
8 if ( !isvalidsock( s ) )
9 error( 1, errno, "ошибка вызова socket" );
10 if ( connect( s, ( struct sockaddr * )&peer;
11 sizeof( peer ) ) )
12 error ( 1, errno, "ошибка вызова connect" );
13 client ( s, &peer );
14 EXIT ( 0 );
15 }
tcp_dient.skel
6-9 Как и в случае tcpserver.skel, записываем в поля структуры sockaddr_in указанные адрес и номер порта, после чего получаем сокет.
10-11 Вызываем connect для установления соединения с сервером.
13 После успешного возврата из connect вызываем заглушку client передавая ей соединенный сокет и структуру с адресом сервера.
Протестировать клиент можно, скопировав каркас в файл helloc.с и дописав в заглушку следующий код:
static void client ( SOCKET s, struct sockaddr_in *peerp )
{
int rc;
char buf[120];
for ( ; ; )
{
rc = recv( s, buf, sizeof( buf ), 0 );
if ( rc <= 0 )
break;
write( 1, buf, rc );
}
}
Этот клиент читает из сокета данные и выводит их на стандартный вывод до тех пор, пока сервер не пошлет конец файла (EOF). Подсоединившись к серверу hello, получаете:
bsd: $
hello localhost 9000
hello, world
bsd: $
Поместим фрагменты кода tcpclient.skel в библиотеку, так же, как поступили с каркасом tcpclient.skel. Новая функция- tcp_client, приведенная в листинге 2.7, имеет следующий прототип:
#include "etcp.h"
SOCKET tcp_client( char *host, char *port );
Возвращаемое значение: соединенный сокет (в случае ошибки завершает программу).
Как и в случае tcp_server, параметр host содержит либо имя, либо IР-адрес хоста, а параметр port - символическое имя сервиса или номер порта в виде ASCII-строки.
Листинг 2.7. Функция tcp_client
1 SOCKET tcp_client( char *hname, char *sname )
2 {
3 struct sockaddr_in peer;
4 SOCKET s;
5 set_address( hname, sname, &peer, "tcp" );
6 s = socket( AF_INET, SOCK_STREAM, 0 );
7 if ( !isvalidsock( s ) )
8 error( 1, errno, "ошибка вызова socket" );
9 if ( connect( s, ( struct sockaddr * )&peer,
10 sizeof( peer ) ) )
11 error( 1, errno, "ошибка вызова connect" );
12 return s;
13 }
Каркас TCP-сервера
Начнем с каркаса TCP-сервера. Затем можно приступить к созданию библиотеки, поместив в нее фрагменты кода из каркаса. В листинге 2.2 показана функция main.
Листинг 2.2. Функция main из каркаса tcpserver.skel
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <unistd.h>
4 #include <stdarg.h>
5 #include <string.h>
6 #include <errno.h>
7 #include <netdb.h>
8 #include <fcntl.h>
9 #include <sys/time.h>
10 #include <sys/socket.h>
11 #include <netinet/in.h>
12 #include <arpa/inet.h>
13 #include "skel.h"
14 char *program_name;
15 int main( int argc, char **argv )
17 struct sockaddr_in local;
18 struct sockaddr_in peer;
19 char *hname;
20 char *sname;
21 int peerlen;
22 SOCKET s1;
23 SOCKET s;
24 const int on = 1;
25 INIT ();
26 if ( argc == 2 )
27 {
28 hname = NULL;
29 sname = argv[ 1 ];
30 }
31 else
32 {
33 hname = argv[ 1 ];
34 sname = argv[ 2 ];
35 }
36 set_address( hname, sname, &local, "tcp" );
37 s = socket( AF_INET, SOCK_STREAM, 0 );
38 if ( !isvalidsock( s ) )
39 error ( 1, errno, "ошибка вызова socket" );
40 if ( setsockopt( s, SOL_SOCKET, SO_REUSEADDR, &on,
41 sizeof( on ) ) )
42 error( 1, errno, "ошибка вызова setsockopt" );
43 if ( bind( s, ( struct sockaddr * ) klocal,
44 sizeof( local ) ) )
45 error( 1, errno, "ошибка вызова bind" );
46 if ( listen ( s, NLISTEN ) )
47 error( 1, errno, "ошибка вызова listen" );
48 do
49 {
50 peerlen = sizeof( peer );
51 s1 = accept( s, ( struct sockaddr * )&peer, &peerlen );
52 if ( !isvalidsock( s1 ) )
53 error( 1, errno, "ошибка вызова accept" );
54 server( s1, &peer );
55 CLOSE( s1 );
56 } while ( 1 );
57 EXIT( 0 );
58 }
Включаемые файлы и глобальные переменные
1- 14 Включаем заголовочные файлы, содержащие объявления используемых стандартных функций.
25 Макрос INIT выполняет стандартную инициализацию, в частности, установку глобальной переменной program_name для функции error и вызов функции WSAStartup при работе на платформе Windows.
Функция main
26-35 Предполагается, что при вызове сервера ему будут переданы адрес и номер порта или только номер порта. Если адрес не указан, то привязываем к сокету псевдоадрес INADDR_ANY, разрешающий прием соединений по любому сетевому интерфейсу. В настоящем приложении в командной строке могут, конечно, быть и другие аргументы, обрабатывать их надо именно в этом месте.
36 Функция set_address записывает в поля переменной local типа sockaddr_in указанные адрес и номер порта. Функция set_address показана в листинге 2.3.
37-45 Получаем сокет, устанавливаем в нем опцию SO_REUSEADDR (совет 23) и привязываем к нему хранящиеся в переменной local адрес и номер порта.
46-47 Вызываем listen, чтобы сообщить ядру о готовности принимать соединения от клиентов.
48-56Принимаем соединения и для каждого из них вызываем функцию server. Она может самостоятельно обслужить соединение или создать Для этого новый процесс. В любом случае после возврата из функции server соединение закрывается. Странная, на первый взгляд конструкция do-while позволяет легко изменить код сервера так, чтоб завершался после обслуживания первого соединения. Для этого достаточно вместо
while ( 1 );
написать
while ( 0 );
Далее обратимся к функции set__address. Она будет использована во всех каркасах. Это естественная кандидатура на помещение в библиотеку стандартных функций.
Листинг 2.3. Функция set_address
tcpserver.skel
1 static void set_address(char *hname, char *sname,
2 struct sockaddr_in *sap, char *protocol)
3 {
4 struct servant *sp;
5 struct hostent *hp;
6 char *endptr;
7 short port;
8 bzero (sap, sizeof(*sap));
9 sap->sin_family = AF_INET;
10 if (hname != NULL)
11 {
12 if (!inet_aton (hname, &sap->sin_addr))
13 {
14 hp = gethostbyname(hname);
15 if ( hp == NULL )
16 error( 1, 0, "неизвестный хост: %s\n", hname );
17 sap->sin_addr = *( struct in_addr * )hp->h_addr;
18 }
19 }
20 else
21 sap->sin_addr.s_addr = htonl( INADDR_ANY );
22 port = strtol( sname, &endptr, 0 );
23 if ( *endptr == '\0' )
24 sap->sin_port = htons( port );
25 else
26 {
27 sp = getservbyname( sname, protocol );
28 if ( sp == NULL )
29 error( 1, 0, "неизвестный сервис: %s\n", sname );
30 sap->sin_port = sp->s_port;
31 }
32 }
set_address
8- 9 Обнулив структуру sockaddr_in, записываем в поле адресного семейства AF_INET.
10-19 Если hname не NULL, то предполагаем, что это числовой адрес в стандартной десятичной нотации. Преобразовываем его с помощью функции inet_aton, если inet_aton возвращает код ошибки, - пытаемся преобразовать hname в адрес с помощью gethostbyname. Если и это не получается, то печатаем диагностическое сообщение и завершаем программу.
20-21 Если вызывающая программа не указала ни имени, ни адреса хоста, устанавливаем адрес INADDR_ANY.
22-24 Преобразовываем sname в целое число. Если это удалось, то записываем номер порта в сетевом порядке (совет 28).
27-30 В противном случае предполагаем, что это символическое название ервиса и вызываем getservbyname для получения соответствующего номера порта. Если сервис неизвестен, печатаем диагностическое сообщение и завершаем программу. Заметьте, что getservbyname уже возвращает номер порта в сетевом порядке.
Поскольку иногда приходится вызывать функцию set_address напрямую, лесь приводится ее прототип:
#include "etcp.h"
void set_address(char *host, char *port,
struct sockaddr_in *sap, char *protocol);
Последняя функция - error - показана в листинге 2.4. Это стандартная диагностическая процедура.
#include "etcp.h"
void error(int status, int err, char *format,...);
Если status не равно 0, то error завершает программу после печати диагностического сообщения; в противном случае она возвращает управление. Если err не равно 0, то считается, что это значение системной переменной errno. При этом в конце сообщения дописывается соответствующая этому значению строка и числовое значение кода ошибки.
Далее в примерах постоянно используется функция error, поэтому добавим в библиотеку.
Листинг2.4. Функция error
tcpserver.skel
1 void error( int status, int err, char *fmt, ... )
2 {
3 va_list ap;
4 va_start ( ар, fmt );
5 fprintf (stderr, "%s: ", program_name );
6 vfprintf( stderr, fmt, ap ) ;
7 va_end( ap ) ;
8 if ( err )
9 fprintf( stderr, ": %s (%d)\n", strerror( err ), err);
10 if ( status )
11 EXIT( status );
12 }
В каркас включена также заглушка для функции server:
static void server(SOCKET s, struct sockaddr_in *peerp)
{
}
Каркас можно превратить в простое приложение, добавив код внутрь этой заглушки. Например, если скопировать файл tcpserver.skel в и заменить заглушку кодом
static void server(SOCKET s, struct sockaddr_in *peerp)
{
send( s, "hello, world\n", 13, 0);
}
то получим сетевую версию известной программы на языке С. Если откомпилировать и запустить эту программу, а затем подсоединиться к ней с помощью программы telnet, то получится вполне ожидаемый результат:
bsd: $ hello 9000
[1] 1163
bsd: $ telnet localhost 9000
Trying 127 .0.0.1...
Connected to localhost
Escape character '^]'.
hello, world
Connection closed by foreign host.
Поскольку каркас tcpserver. skel описывает типичную для TCP-сервера ситуацию, поместим большую часть кода main в библиотечную функцию tcp_serv показанную в листинге 2.5. Ее прототип выглядит следующим образом:
#include "etcp.h"
SOCKET tcp_server( char *host, char *port );
Возвращаемое значение: сокет в режиме прослушивания (в случае ошибки завершает программу).
Параметр host указывает на строку, которая содержит либо имя, либо IP – адрес хоста, а параметр port - на строку с символическим именем сервиса или номером порта, записанным в виде ASCII-строки.
Далее будем пользоваться функцией tcp_server, если не возникнет необхомо модифицировать каркас кода.
Листинг 2.5. Функция tcp_server
1 SОСКЕТ tcp_server( char *hname, char *sname )
2 {
3 struct sockaddr_in local;
4 SOCKET s;
5 const int on = 1;
6 set_address( hname, sname, &local, "tcp" );
7 s = socket( AF_INET, SOCK_STREAM, 0 );
8 if ( !isvalidsock( s ) )
9 error( 1, errno, "ошибка вызова socket" );
10 if ( setsockopt ( s, SOL_SOCKET, SO_REUSEADDR,
11 ( char * )&on, sizeoff on ) ) )
12 error( 1, errno, "ошибка вызова setsockopt" );
13 if ( bind( s, ( struct sockaddr * } &local,
14 sizeof( local ) ) )
15 error( 1, errno, "ошибка вызова bind" );
16 if ( listen( s, NLISTEN ) )
17 error( 1, errno, "ошибка вызова listen" );
18 return s;
19 }
Каркас UDP-клиента
Функция main в каркасе UDP-клиента выполняет в основном запись в поля переменной peer указанных адреса и номера порта сервера и получает сокет типа SOCK_DGRAM. Она показана в листинге 2.10. Весь остальной код каркаса такой же, как для .
Листинг 2.10. Функция main из каркаса udpclient.skel
1 int main( int argc, char **argv )
2 {
3 struct sockaddr_in peer;
4 SOCKET s;
5 INIT();
6 set_address( argv[ 1 ], argv[ 2 ], &peer, "udp" );
7 s = socket( AF_INET, SOCK_DGRAM, 0 );
8 if ( !isvalidsock( s ) )
9 error( 1, errno, "ошибка вызова socket" ) ;
10 client( s, &peer ) ;
11 exit( 0 ) :
12 }
Теперь можно протестировать одновременно этот каркас и программу udphello, для чего необходимо скопировать udpclient.skel в файл udphelloc.с и вместо клиентской заглушки подставить такой код:
static void client( SOCKET s, struct sockaddr_in *peerp )
{
int rc;
int peerlen;
char buff [ 120 ];
peerlen = sizeof( *peerp );
if ( sendto( s, "", 1, 0, ( struct sockaddr * )peerp,
peerlen ) < 0 )
error( 1, errno, "ошибка вызова sendto" );
rc= recvfrom( s, buf, sizeof( buf ), 0,
( struct sockaddr * )peerp, &peerlen );
if ( rc >= 0 )
write ( 1, buf, rc );
else
error( 1, errno, "ошибка вызова recvfrom" );
}
Функция client посылает серверу нулевой байт, читает возвращенную датаграмму, выводит ее в стандартное устройство вывода и завершает программу. Функции recvfrom в коде udphello вполне достаточно одного нулевого байта. После его приема она возвращает управление основной программе, которая и посылает ответную датаграмму.
При одновременном запуске обеих программ выводится обычное приветствий
bsd: $ udphello 9000 &
[1] 448
bsd: $ updhelloc localhost 9000
hello, world
bsd: $
Как всегда, следует вынести стартовый код из main в библиотеку. Обратите внимание, что библиотечной функции, которой дано имя udp_client (листинг 2.11), передается третий аргумент - адрес структуры sockaddr_in; в нее будет помещен адрес и номер порта, переданные в двух первых аргументах.
#include "etcp.h"
SOCKET udp_client( char *host, char *port,
struct sockaddr_in *sap );
Возвращаемое значение: UDP-сокет и заполненная структура sockaddr_in (в случае ошибки завершает программу).
Листинг 2.11. Функция udp_client
1 SOCKET udp_client( char *hname, char *sname,
2 struct sockaddr_in *sap )
3 {
4 SOCKET s;
5 set_address( hname, sname, sap, "udp" );
6 s = socket( AF_INET, SOCK_DGRAM, 0 );
7 if ( !isvalidsockt ( s ) )
8 error( 1, errno, "ошибка вызова socket" );
9 return s;
10 }
Каркас UDP-сервера
Каркас UDP-сервера в основном похож на каркас TCP-сервера. Его отличительная особенность - не нужно устанавливать опцию сокета SO_REUSEADDR и обращаться к системным вызовам accept и listen, поскольку UDL - это протокол, не требующий логического соединения (совет 1). Функция main из каркаса [приведена в листинге 2.8.
Листинг 2.8. Функция main из каркаса udpserver.skel
1 int main( int argc, char **argv )
2 {
3 struct sockaddr_in local;
4 char *hname;
5 char *sname;
6 SOCKET s;
7 INIT();
8 if ( argc == 2 )
9 {
10 hname = NULL;
11 sname = argv[ 1 ];
12 }
13 else
14 {
15 hname = argv[ 1 ];
16 sname = argv[ 2 ];
17 }
18 set_address( hname, sname, &local, "udp" );
19 s = socket( AF_INET, SOCK_DGRAM, 0 );
20 if ( !isvalidsock( s ) )
21 error ( 1, errno, "ошибка вызова socket" );
22 if ( bind( s, ( struct sockaddr * ) &local,
23 sizeoff local ) ) )
24 error( 1, errno, "ошибка вызова bind" );
25 server( s, &local );
26 EXIT( 0 ) ;
27 }
udpserver.skel
18 Вызываем функцию set_address для записи в поля переменнойlocal типа sockaddr_in адреса и номера порта, по которому сервер будет принимать датаграммы. Обратите внимание, что вместо "tcp" задается третьим параметром " udp".
19-24 Получаем сокет типа SOCK_DGRAM и привязываем к нему адрес и нон» порта, хранящиеся в переменной local.
25 Вызываем заглушку server, которая будет ожидать входящие датаграммы.
Чтобы получить UDP-версию программы «hello world», следует скопировать каркас в файл udphelloc.с и вместо заглушки вставить следующий код:
static void server( SOCKET s, struct sockaddr_in *localp )
{
struct sockaddr_in peer;
int peerlen;
char buf [ 1 ];
for ( ; ; )
{
peerlen = sizeof( peer );
if ( recvfrom( s, buf, sizeof( buf ), 0,
( struct sockaddr * )&peer, &peerlen ) < 0 )
error( 1, errno, "ошибка вызова recvfrom" );
if ( sendto( s, "hello, world\n", 13, 0,
( struct sockaddr * )&peer, peerlen ) < 0 )
error( 1, errno, "ошибка вызова sendto" );
}
}
Прежде чем тестировать этот сервер, нужно разработать каркас UDP-клиента (листинг 2.10). Но сначала нужно вынести последнюю часть main в библиотечную функцию udp_server:
#include "etcp.h"
SOCKET udp_server( char *host, char *port );
Возвращаемое значение: UDP-сокет, привязанный к хосту host и порту port (в случае ошибки завершает программу).
Как обычно, параметры host и port указывают на строки, содержащие соответственно имя или IP-адрес хоста и имя сервиса либо номер порта в виде ASCII-строки.
Листинг 2.9. Функция udpjserver
1 SOCKET udp_server( char *hname, char *sname )
2 {
3 SOCKET s;
4 struct sockaddr_in local;
5 set_address( hname, sname, &local, "udp" );
6 s = socket( AF_INET, SOCK_DGRAM, 0 );
7 if ( !isvalidsock( s ) )
8 error( 1, errno, "ошибка вызова socket" );
9 if ( bind( s, ( struct sockaddr * ) &local,
10 sizeof( local ) ) )
11 error( 1, errno, "ошибка вызова bind" );
12 return s;
13 }
Классы адресов
По традиции все IP-адреса подразделены на пять классов, показанных на рис. 2.4. Адреса класса D используются для группового вещания, а класс Е зарезервирован для будущих расширений. Остальные классы - А, В и С – предназначены для адресации отдельных сетей и хостов.

Рис. 2.4. Классы IP - адресов
Класс адреса определяется числом начальных единичных битов. У адресов класса А вообще нет бита 1 в начале, у адресов класса В - один такой бит, у адресов класса С - два и т.д. Идентификация класса адреса чрезвычайно важна, поскольку от этого зависит интерпретация остальных битов адреса.
Остальные биты любого адреса классов А, В и С разделены на две группы. Первая часть любого адреса представляет собой идентификатор сети, вторая -идентификатор хоста внутри этой сети.
Примечание: Биты идентификации класса также считаются частью идентификатора сети. Так, 130.50.10.200 - это адрес класса В, в котором идентификатор сети равен 0x8232.
Смысл разбивки адресного пространства на классы в том, чтобы обеспечить необходимую гибкость, не теряя адресов. Например, класс А позволяет адресовать сети с огромным (16777214) количеством хостов.
Примечание: Существует 224, или 16777216 возможных идентификаторов хостов, но адрес 0 и адрес, состоящий из одних единиц, имеют специальный смысл. Адрес из одних единиц - это широковещательный адрес. IP-датаграммы, посланные по этому адресу, доставляются всем хостам в сети. Адрес 0 означает «этот хост»и используется хостом как адрес источника, которому в ходе процедуры начальной загрузки необходимо определить свой истиннный сетевой адрес. Поэтому число хостов в сети всегда равно 2^n - 2, где n - число бит в части адреса, относящейся к хосту.
Поскольку в адресах класса А под идентификатор сети отводятся 7 бит, то всего существует 128 сетей класса А.
Примечание: Как и в случае идентификаторов хостов, два из этих адресов зарезервированы. Адрес 0 означает «эта сеть» и, аналогично хосту 0, используется для определения адреса сети в ходе начальной Р загрузки. Адрес 127 - это адрес «собственной» сети хоста. Датаграммы, адресованные сети 127, не должны покидать хост отправитель. Часто этот адрес называют «возвратным» (loopback) адресом, поскольку отправленные по нему датаграммы «возвращаются» на тот же самый хост.
На другом полюсе располагаются сети класса С. Их очень много, но в каждой может быть не более 254 хостов. Таким образом, адреса класса А предназначены для немногих гигантских сетей с миллионами хостов, тогда как адреса класса С - для миллионов сетей с небольшим количеством хостов.
В табл. 2.1 показано, сколько сетей и хостов может существовать в каждом классе, а также диапазоны допустимых адресов. Будем считать, что сеть 127 принадлежит классу А, хотя на самом деле она, конечно, недоступна для адресации.
Таблица 2.1. Число сетей, хостов и диапазоны адресов для классов А, В и С
|
Класс |
Сети |
Хосты |
Диапазон адресов |
|
A |
127 |
16777214 |
0.0.0.1-127.255.255.255 |
|
B |
16384 |
65534 |
128.0.0.0-191.255.255.255 |
|
C |
2097252 |
254 |
192.0.0.0-223.255.255.255 |
Примечание: В действительности, как отмечается в работе [Huitema 1995], в исходном проекте фигурировали только адреса, которые теперь относятся к классу А. Подразделение на три класса былосделано позже, чтобы иметь более 256 сетей
Появление дешевых, повсеместно применяемых персональных компьютеров привело к значительному росту числа сетей и хостов. Нынешний размер Internet намного превосходит ожидания его проектировщиков.
Такой рост выявил некоторые недостатки классов адресов. Прежде всего, число хостов в классах А и В слишком велико. Вспомним, что идентификатор сети, как предполагалось, относится к физической сети, например локальной. Но никто не станет строить физическую сеть из 65000 хостов, не говоря уже о 16000000. Вместо этого большие сети разбиваются на сегменты, взаимосвязанные маршрутизаторами.
В качестве простого примера рассмотрим два сегмента сети, изображенной
на рис. 2.5.
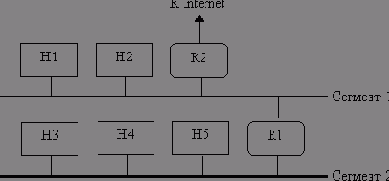
Рис. 2.5. Сеть из двух сегментов
Если хосту H1 нужно обратиться к хосту Н2, то он получает физический адрес, соответствующий IP-адресу Н2 (используя для этого метод, свойственный данной реализации физической сети), и помещает датаграмму «на провод».
А если хосту H1 необходимо обратиться к хосту Н3? Напрямую послать датаграмму невозможно, даже если известен физический адрес получателя, поскольку H1 и Н3 находятся в разных сетях. Поэтому H1 должен отправить датаграмму через маршрутизатор R1. Если у двух сегментов разные идентификаторы сетей, то H1 по своей маршрутной таблице определяет, что пакеты, адресованные сегменту 2, обрабатываются маршрутизатором R1, и отправляет ему датаграмму в предположении, что тот переправит ее хосту Н3.
Итак, можно назначить двум сегментам различные идентификаторы сети. Но есть и другие решения в рамках системы адресных классов. Во-первых, маршрутная таблица хоста H1 может содержать по одному элементу для каждого хоста в сегменте 2, который определит следующего получателя на пути к этому хосту - R1. Такая же таблица должна размещаться на каждом хосте в сегменте 1. Аналогичные таблицы, описывающие достижимость хостов из сегмента 1, следует поместить на каждом хосте из сегмента 2. Очевидно, такое решение плохо масштабируется при значительном количестве хостов. Кроме того, маршрутные таблицы придется вести вручную, что очень скоро станет непосильной задачей для администратора. Поэтому на практике такое решение почти никогда не применяется
Во-вторых, можно реализовать ARP-прокси (proxy ARP) таким образом, что - бы R1 казался для хостов из сегмента 1 одновременно Н3, Н4 и Н5, а для хостов из сегмента 2 – H1, H2 и R2.
Примечание: Агента ARP в англоязычной литературе еще называют promiscuous ARP (пропускающий ARP) или ARP hack (трюк ARP).
Это решение годится только в случае, когда в физической сети используется протокол ARP (Address Resolution Protocol - протокол разрешения адресов) для отображения IP-адресов на физические адреса. В соответствии с ARP хост, которому нужно получить физический адрес, согласующийся с некоторым IP-адресом, должен послать широковещательное сообщение с просьбой хосту, обладающему данным IP-адресом, выслать свой физический адрес. ARP-запрос получают все хосты в сети, но отвечает только тот, IP-адрес которого совпадает с запрошенным.
Если применяется агент ARP, то в случае, когда хосту H1 необходимо послать IP-датаграмму НЗ, физический адрес которого неизвестен, он посылает ARP-запрос физического адреса Н3. Но Н3 этот запрос не получит, поскольку находится в другой сети. Поэтому на запрос отвечает его агент - R1, сообщая свой собственный адрес. Когда R1 получает датаграмму, адресованную Н3, он переправляет ее конечному адресату. Все происходит так, будто Н3 и H1 находятся в одной сети.
Как уже отмечалось, агент ARP может работать только в сетях, которые используют протокол ARP и к тому же имеют сравнительно простую топологию. Подумайте, что случится при наличии нескольких маршрутизаторов, соединяющих сегменты 1 и 2.
Из вышесказанного следует, что общий способ организовать сети с несколькими сегментами - это назначить каждому сегменту свой идентификатор сети. Но у этого решения есть недостатки. Во-первых, при этом возможна потеря многих адресов в каждой сети. Так, если у любого сегмента сети имеется свой адрес класса В, то большая часть IP-адресов просто не будет использоваться.
Во-вторых, маршрутная таблица любого узла, который направляет датаграммы напрямую в комбинированную сеть, должна содержать по одной записи для каждого сегмента. В указанном примере это не так страшно. Но вообразите сеть из нескольких сотен сегментов, а таких сетей может быть много. Понятно, что размеры маршрутных таблиц станут громадными.
Примечание: Эта проблема более серьезна, чем может показаться на первый взгляд. Объем памяти маршрутизаторов обычно ограничен, и нередко маршрутные таблицы размещаются в памяти специального назначения на сетевых картах. Реальные примеры отказа маршрутизаторов из-за роста маршрутных таблиц рассматриваются в работе [Huitema 1995].
Обратите внимание, что эти проблемы не возникают при наличии хотя бы одного идентификатора сети. IP-адреса не остаются неиспользованными, поскольку при потребности в новых хостах можно всегда добавить новый сегмент. С другой стороны, так как имеется лишь один идентификатор сети, в любой маршрутной таблице необходима всего одна запись для отправки датаграмм любому хосту в этой сети.
Kрax хоста на другом конце соединения
Последняя ошибка, которую следует рассмотреть, - это аварийный останов хоста на другом конце. Ситуация отличается от краха хоста, поскольку TCP на другом конце не может с помощью сегмента FIN проинформировать программу о то, что ее партнер уже не работает.
Пока хост на другом конце не перезагрузят, ситуация будет выглядеть как сбой в сети- TCP удаленного хоста не отвечает. Как и при сбое в сети, TCP продолжает повторно передавать неподтвержденные сегменты. Но в конце концов, если удаленный хост так и не перезагрузится, то TCP вернет приложению код ошибки ETIMEDOUT.
А что произойдет, если удаленный хост перезагрузится до того, как TCP Прекратит попытки и разорвет соединение? Тогда повторно передаваемые вами сегменты дойдут до перезагрузившегося хоста, в котором нет никакой информации о старых соединениях. В таком случае спецификация TCP [Postel 1981b] требует, чтобы принимающий хост послал отправителю RST. В результате отправитель оборвет соединение, и приложение либо получит код ошибки ECONNRESET (если есть ожидающее чтение), либо следующая операция записи закончится сигналов SIGPIPE или ошибкой EPIPE.
Литература
Albitz, P. and Liu, С. 1998. DNS and BIND, 3rd Edition. O'Reilly & Associates, Sebastopol, Calif.
Baker, R, ed. 1995. «Requirements for IP Version 4 Routers», RFC 1812 (June).
Banga, G. and Mogul, J. C. 1998. «Scalable Kernel Performance for Internet Servers Under Realistic Loads», Proceedings of the 1998 USENIX Annual Technica Conference, New Orleans, LA.
http://www.cs.rice.edu/~gaurav/my_p.apers/usenix98.ps
Bennett, J. C. R., Partridge, C., and Shectman, N. 1999. «Packet Reordering Is Not Pathological Network Behavior», IEEE/ACM Transactions on Networking, vol. 7, no. 6, pp. 789-798 (Dec.).
Braden, R. T. 1985. «Towards a Transport Service for Transaction Processina Applications», RFC 955 (Sept.).
Braden, R. T. 1992a. «Extending TCP for Transactions-Concepts,» RFC 1379 (Nov.).
Braden, R. T. 1992b. «TIME-WAIT Assassination Hazards in TCP,» RFC 133 (May).
Braden, R. T. 1994. «T/TCP—TCP Extensions for Transactions, Functional Speci-fication», RFC 1644 (July).
Braden, R. T, ed. 1989. «Requirements for Internet Hosts—Communicatior Layers», RFC 1122 (Oct.).
Brown, C. 1994. UNIX Distributed Programming. Prentice Hall, Englewood Cliffc
NJ.
Castro, E. 1998. Peri and CGI for the World Wide Web: Visual QuickStart Guide Peachpit Press, Berkeley, Calif.
Clark, D. D. 1982. «Window and Acknowledgement Strategy in TCP», RFC 813
(July).
Cohen, D. 1981. «On Holy Wars and a Plea for Peace», IEEE Computer Magazine, vol. 14, pp. 48-54 (Oct.).
Comer, D. E. 1995. Internetworking with TCP/IP Volume I: Principles, Protocols, апd Architecture, Third Edition. Prentice Hall, Englewood Cliffs, NJ.
Comer, D. E. and Lin, J. C. 1995. «TCP Buffering and Performance Over an ATM Network» Journal of Internetworking: Research and Experience, vol. 6, no. 1, pp. 1-13 (Mar.).
ftp://gwen.cs.purdue.edu/pub/lin/TCP.atm.ps.
Comer, D. E. and Stevens, D. L. 1999. Internetworking with TCP/IP Volume II: Design, Implementation, and Internals, Third Edition. Prentice Hall, Englewood Cliffs, NJ.
Fuller, V, Li, T, Yu, J., and Varadhan, K. 1993. «Classless Inter-Domain Routing (CIDR): An Address Assignment», RFC 1519 (Sept.).
Gallatin, A., Chase, J., and Yocum, K. 1999. «Trapeze/IP: TCP/IP at Near-Gigabit Speeds», 1999 Usenix Technical Conference (Freenix track), Monterey, Calif.
http://www.cs.duke.edu/ari/publications/tcpgig.ps
Haverlock, P. 2000. Private communication.
Hinden, R. M. 1993. « Applicability Statement for the Implementation of Classless Inter-Domain Routing (CIDR)», RFC 1517 (Sept.).
Huitema, C. 1995. Routing in the Internet. Prentice Hall, Englewood Cliffs, NJ.
International Standards Organization 1984. «OSI—Basic Reference Model», ISO 7498, International Standards Organization, Geneva.
Jacobson, V. 1988. «Congestion Avoidance and Control», Proc. of SIGCOMM '88 i; vol. 18, no. 4, pp. 314-329 (Aug.).
Jacobson, V. 1999. «Re: Traceroute History: Why UDP?», Message-ID <79m7m4$reh$l ©dog.ee.lbl.gov>, Usenet, comp.protocols.tcp-ip (Feb.).
http://www.kohala.com/start/vanj99Feb08.txt
Jacobson, V., Braden, R. Т., and Borman, D. 1992. «TCP Extensions for High Performance», RFC 1323 (May).
Jain, B.N. and Agrawala, A. K. 1993. Open Systems Interconnection: Its Architecture and Protocols, Revised Edition. McGraw-Hill, N.Y.
Kacker, M. 1998. Private communication.
Kacker, M. 1999. Private communication.
Kantor, B. and Lapsley, P. 1986. «Network News Transfer Protocol», RFC 977 (Feb.).
Kernighan, B. W. and Pike, R. 1999. The Practice of Programming. Addison-Wesley, Reading, Mass.
Kernighan, B. W. and Ritchie, D. M. 1988. The С Programming Language, Second Edition. Prentice Hall, Englewood Cliffs, NJ.
Knuth, D. E. 1998. The Art of Computer Programming, Volume 2, Seminumerical Algorithms, Third Edition. Addison-Wesley, Reading, Mass.
Lehey, G. 1996. The Complete FreeBSD. Walnut Creek CDROM, Walnut Creek, Calif.
Lions, J. 1977. Lions' Commentary on UNIX 6th Edition with Source Code. Peer-to-Peer Communications, San Jose, Calif.
Lotter, M. K. 1988. «TCP Port Service Multiplexer (TCPMUX)», RFC 1078 (Nov.).
Mahdavi, J. 1997. « Enabling High Performance Data Transfers on Hosts: (Notes for Users and System Administrators)», Technical Note (Dec.).
http://www.psc.edu/networking/perf_tune.html
Malkin, G. 1993. «Traceroute Using an IP Option», RFC 1393 (Jan.).
McCanne, S. and Jacobson, V. 1993. «The BSD Packet Filter: A New Architecture for User-Level Packet Capture», Proceedings of the 1993 Winter USENIX Conference, pp. 259-269, San Diego, Calif.
ftp://ftp.ee.lbl.gov/papers/bpf-usenix93-ps.Z
Miller, B. P., Koski, D., Lee, C. P., Maganty, V, Murthy, R., Natarajan, A, and Steidi, J. 1995. «Fuzz Revisited: A Re-examination of the Reliability of UNIX Utilities and Services», CS-TR-95-1268, University of Wisconsin (Apr.).
ftp://grilled.cs.wise.edu/technical_papers/fuzz-revisited.ps.
Minshall, G., Saito, Y., Mogul, J. C., and Verghese, B. 1999. «Application
Performance Pitfalls and TCP's Nagle Algorithm», ACM SIGMETRICS Workshop
on Internet Server Performance, Atlanta, Ga..
http://www.cc.gatech.edu/fac/Ellen.Zegura/wisp99/papers/minshall.ps
Mogul, J. and Postel, J. B. 1985. «Internet Standard Subnetting Procedure», RFC 950 (Aug.).
Nagle, J. 1984. «Congestion Control in IP/TCP Internetworks», RFC 896 (Jan.).
Oliver, M. 2000. Private communication. ;
Padlipsky, M. A. 1982. «A Perspective on the ARPANET Reference Model,» RFC 871 (Sept.).
Partridge, C. 1993. «Jacobson on TCP in 30 Instruction», Message-ID I
<1993Sep8.213239.28992 @sics.se>, Usenet, comp.protocols.tcp-ip Newsgroup (Sept.).http://www-nrg.ee. ibl .gov/nrg-email.html
Partridge, C. and Pink, S. 1993. «A Faster UDP», IEEE/ACM Transactions оп Networking, vol. 1, no. 4, pp. 427-440 (Aug.).
Patchett, C. and Wright, M. 1998. The CGI/PerI Cookbook. John Wiley & Sons, N.Y.
Paxson, V. 1995. «Re: Traceroute and TTL», Message-ID <48407@dog.ee.lbl.gov>, Usenet, comp.protocols.tcp-ip (Sept.).
ftp://ftp.ee.Ibl.gov/email/paxson.95sep29.txt
Paxson, V. 1997. «End-to-End Routing Behavior in the Internet», IEEE/ACM
Transactions on Networking, vol. 5, no. 5, pp. 601-615 (Oct.).
ftp://ftp.ee.Ibl.gOv/papers/vp-routing-TON.ps.Z
Plummer, W. W. 1978. «TCP Checksum Function Design», IEN 45 (June)
Reprinted as an appendix to RFC 1071.
Postel, J. B. 1981. «Internet Control Message Protocol», RFC 792 (Sept.).
Postel, J. В., ed. 1981a. «Internet Protocol», RFC 791 (Sept.).
Postel, J. В., ed. 1981b. «Transmission Control Protocol», RFC 793 (Sept.).
Quinn, B. and Shute, D. 1996. Windows Sockets Network Programming. Addison-Wesley, Reading, Mass.
Rago, S. A. 1993. UNIX System V Network Programming. Addison-Wesley, Reading, Mass.H
Rago, S. A. 1996. «Re: Sockets vs TLL» Message-ID <50pcds$jl8@prologic.plc.com>,
Usenet, comp.protocols.tcp-ip (Oct.).
Rekhter, Y. and Li, T. 1993. «An Architecture for IP Address Allocation with CIDR»,
RFC 1518 (Sept.).
Rekhter, Y, Moskowitz, R. G., Karrenberg, D., Groot, G. J. de, and Lear, E. 1996.
«Address Allocation of Private Internets», RFC 1918 (Feb.).
Reynolds, J. K. and Postel, J. B. 1985. «File Transfer Protocol (FTP)», RFC 959 ,
(Oct.).
Richter, J. 1997. Advanced Windows, Third Edition. Microsoft Press, Redmond, Wash.
Ritchie, D. M. 1984. «A Stream Input-Output System», AT&T Bell Laboratories
Technicaljoumal, vol. 63, no. No. 8 Part 2, pp. 1897-1910 (Oct.).
http://cm.bell-labs.com/cm/cs/who/dmr/st.ps
Romkey, J. L. 1988. «A Nonstandard for Transmission of IP Datagrams Over Seria Lines: SLIP», RFC 1055 Qune).
Saltzer, J. H., Reed, D. P., and Clark, D. D. 1984. «End-to-End Arguments ir System Design», ACM Transactions in Computer Science, vol. 2, no. 4, pp. 277-288 (Nov.)
Sedgewick, R. 1998. Algorithms in C, Third Edition, Parts 1-4. Addison-Wesley Reading, Mass.
Semke, J., Mahdavi, J., and Mathis, M. 1998. «Automatic TCP Buffer Tuning» Computer Communications Review, vol. 28, no. 4, pp. 315-323 (Oct.).
http://www.psc.edu/networking /ftp/papers/autotune-sigcomm98.ps
Srinivasan, R. 1995. «XDR: External Data Representation Standard», RFC 1832 (Aug.)
Stevens.W. R. 1990. UNIX Network Programming. Prentice Hall, Englewood Cliffs
Stevens, W. R. 1994. TCP/IP Illustrated, Volume 1: The Protocols. Addison-Wesley Reading, Mass.
Stevens, W. R. 1996. TCP/IP Illustrated, Volume 3: TCP for Transactions, HTTP NNTP, and the UNIX Domain Protocols. Addison-Wesley, Reading, Mass.
Stevens, W. R. 1998. UNIX Network Programming, Volume 1, Second Edition, Networking APIs: Sockets and XTI. Prentice Hall, Upper Saddle River, NJ.
Stevens, W. R. 1999. UNIX Network Programming, Volume 2, Second Edition, Interprocess Communications. Prentice Hall, Upper Saddle River, NJ.
Stone, J., Greenwald, M., Partridge, C., and Hughes, J. 1998. «Performance oi Checksums and CRC's Over Real Data», IEEE/ACM Transactions on Networking, vol. 6 no. 5, pp. 529-543 (Oct.).
Tanenbaum, A. S. 1996. Computer Networks, Third Edition. Prentice Hall Englewood Cliffs, NJ.
Tanenbaum, A. S. and Woodhull, A. S. 1997. Operating Systems: Design ana Implementation, Second Edition. Prentice Hall, Upper Saddle River, NJ.
Torek, C. 1994. «Re: Delay in Re-Using TCP/IP Port», Message-ID <199501010028.QAA16863 ©elf.bsdi.com>, Usenet, comp.unix.wizards (Dec.).
http://www.kohala.corn/start/torek.94dec31 .txt
Unix International 1991. «Data Link Provider Interface Specification,» Revision 2.0.0, Unix International, Parsippany, NJ. (Aug.).
http://www.whitefang.com/rin/docs/dlpi-ps
http://www.opengroup.org/publications/catalog/c 81 l.htm
Varghese, G. and Lauck, A. 1997. «Hashed and Hierarchical Timing Wheels: Efficient Data Structures for Implementing a Timer Facility», IEEE/ACM Transactions on Networking, vol.5, no. 6, pp. 824-834 (Dec.).
http://www.cere-wusti.edu/-varghese/PAPERS/twheel.ps.Z
Wall, L., Christiansen, T, and Schwartz, R. L. 1996. Programming Peri, Secona Edition. O'Reilly & Associates, Sebastopol, Calif.
WinSock Group 1997. «Windows Sockets 2 Application Programming Interface», Revision 2.2.1, The Winsock Group (May).
http://www.stardust.com/wsresource/winsock2/ws2docs.html
Wright, G. R. and Stevens, W. R. 1995. TCP/IP Illustrated, Volume 2: The Implementation. Addison-Wesley, Reading, Mass.
Маршрутная таблица
Кроме того, netstat может дать маршрутную таблицу. Назначьте опцию -n, чтобы получить не символические имена, а IP-адреса; так лучше видно, в какие сети маршрутизируются пакеты.
Интерфейсы и соединения, выведенные на рис. 4.13, показаны и на рис. 4.14. Интерфейс 1оО не показан, так как полностью находится внутри машины bsd.
bsd: $ netstat -rn
Routing tables
Internet:
Destination Gateway Flags Refs Use Netif Expire
default 163.179.44.41 UGSc 2 0 tun0
127.0.0.1 127.0.0.1 UH 1 34 lo0
163.179.44.41 205.184.142.171 UH 3 0 tunO
172.30 linkt#l UC 0 0 ed0
172.30.0.1 0:0:c0:54:53:73 UHLW 0 132 lo0
Рис. 4.13. Маршрутная таблица, выведенная программой netstart

Рис. 4.14. Информация об интерфейсах и хостах, выведенная программой netstat
Прежде чем знакомиться с отдельными элементами этой выдачи, обсудим назначение колонок. В первой колонке находится пункт назначения маршрута. Это может быть конкретный хост, сеть или маршрут по умолчанию.
В колонке Flags печатаются различные флаги, большая часть которых зависит от реализации. Следует упомянуть только следующие:
U - маршрут задействован («UP»);
Н - маршрут к хосту. Если этот флаг отсутствует, то речь идет о маршруте к сети (или к подсети, если используется бесклассовая междоменная маршрутизация CIDR - совет 2);
G - непрямой маршрут. Иными словами, пункт назначения не связан напрямую с данным хостом, к нему следует добираться через промежуточный маршрутизатор или шлюз (G - gateway).
Легко сделать ошибку, полагая, что флаги Н и G взаимоисключающие, то есть маршрут может идти либо к хосту (Н), либо к промежуточному шлюзу (G). Флаг Н означает, что адрес в первой колонке представляет собой полный IP-адрес хоста. Если флага Н нет, то адрес в этой колонке не содержит идентификатора хоста, иными словами, он - адрес сети. Флаг G показывает, достижим ли адрес, проставленный в первой колонке, непосредственно с данного хоста или необходимо пройти через промежуточный маршрутизатор.

Рис. 4.15. H2 выступает в роли шлюза к H3
Вполне возможно, что для некоторого маршрута будут одновременно установлены флаги G и Н. Рассмотрим, например, две сети, изображенные на рис. 4.15. Хосты H1 и Н2 подключены к сети Ethernet с адресом 172.20. Хост Н3 соединен с Н2 по РРР-линии с сетевым адресом 198.168.2.
Маршрут к НЗ в маршрутной таблице HI будет выглядеть так:
Destination Gateway Flags Refs Use Netif Expire
192.168.2.2 172.20.10.2 UGH 0 0 edO
Флаг Н установлен потому, что 192.168.2.2 - полный адрес хоста. А флаг G - так как HI не имеет прямого соединения с Н3 и должен идти через хост Н2 (172.20.10.2). Обратите внимание, что на рис. 4.13 для маршрута к хосту 163.179.44.41 нет флага G, поскольку этот хост напрямую подключен к интерфейсу tun0 (205.184.142.171) в машине bsd.
На рис. 2.9 в маршрутной таблице H1 не должно быть записи для Н3. Вместо нее присутствует запись для подсети 190.50.2, поскольку именно в этом состоит смысл организации подсетей - уменьшить размеры маршрутных таблиц. Запись в маршрутной таблице HI для этой подсети выглядела бы так:
Destination Gateway Flags Refs Use Netif Expire
190.50.2 190.50.1.4 UG 0 0 edO
Флаг Н не установлен, так как 190.50.2 - адрес подсети, а не отдельного хоста. Имеется флаг G, так как Н3 не соединен напрямую с HI. Датаграммы от Н3 к H1 должны проходить через маршрутизатор R1 (190.50.1.4).
Смысл колонки Gateway зависит от того, есть флаг G или нет. Если маршрут непрямой (флаг G есть), то в колонке Gateway находится IP-адрес следующего узла (шлюза). Если же флага G нет, то в этой колонке печатается информация о том, как достичь напрямую подсоединенного пункта назначения. Во многих реализациях это всегда IP-адрес интерфейса, к которому и подсоединен пункт казна»; чтения. В реализациях, производных от BSD, это может быть также МАС-адрес, как, показано в последней строке на рис. 4.13. В таком случае будет установлен флаг L
Колонка Refs содержит счетчик ссылок на маршрут, то есть количество активных пользователей этого маршрута.
Колонка Use указывает, сколько пакетов было послано по этому маршруту, а колонка Netif содержит имя ассоциированного сетевого интерфейса, который представляет собой тот же объект, о котором вы получаете информацию с помощью опции -i.
Теперь, разобравшись, что означают колонки, печатаемые командой netstat -rn, вернемся к рис. 4.13.
Первая строка на этом рисунке описывает маршрут по умолчанию. Именно по нему отсылаются датаграммы, когда в маршрутной таблице нет более точного маршрута. Например, если выполнить команду ping netcom4. netcom. com, то получится такой результат:
bsd: $ ping netcom4.netcom.com
PING netcom4.netcom.com (199.183.9.104): 56 data bytes
64 bytes from 199.183.9.104: icmp_seq=0 ttl=248 time=268.604 ms
...
Поскольку нет маршрута ни до хоста 199.183.9.104, ни до сети, содержащей этой хост, эхо-запросы ICMP (совет 33) посылаются по маршруту по умолчанию. В соответствии с первой строкой выдачи netstat шлюз для этого маршрута имеет адрес 163.179.44.41, туда и посылается датаграмма. Строка 3 на рис. 4.13 показывает, что есть прямой маршрут к хосту 163.179.44.41, и отсылать ему Дата граммы следует через интерфейс с IP-адресом 205.184.142.171.
Строка 2 в выдаче - это маршрут для возвратного адреса (127.0.0.1). Поскольку это адрес хоста, установлен флаг Н. Так как хост подсоединен напрямую, то имеется и флаг G. А в колонке Gateway вы видите IP-адрес интерфейса 1о0.
В строке 4 представлен маршрут к локальной сети Ethernet. В связи с тем, что на машине bsd установлена операционная система, производная от BSD, в колонке Gateway находится строка Link#l. В других системах был бы просто напечатан IP-адрес интерфейса, подсоединенного к локальной сети (172.30.0.1).
Механизм контролеров
В действительности протокол TCP обладает механизмом обнаружения мертвых соединений - так называемыми контролерами (keep-alive). Но, как вы вскоре увидите, для приложении подобный механизм часто бесполезен. Если приложение его активирует, то TCP посылает на другой конец специальный сегмент, когда по соединению в течение некоторого времени не передавались данные. Если хост на другом конце доступен и приложение там все еще работает, то TCP отвечает сегментом ACK. В этом случае TCP, пославший контролера, сбрасывает время простоя в нуль; приложение не получает извещения о том, что имел место обмен информацией.
Если хост на другом конце работает, а приложение - нет, то TCP посылает в ответ сегмент RST. A TCP, отправивший контролер, разрывает соединение и возвращает приложению код ECONNRESET. Обычно так бывает после перезагрузки и удаленного хоста, поскольку, как говорилось в совете 9, если бы завершилось всего лишь приложение на другом конце, то TCP послал сегмент FIN.
Если удаленный хост не посылает в ответ ни АСК, ни RST, то TCP продолжает посылать контролеров, пока не получит сведений, что хост недоступен. В этот момент он разрывает соединение и возвращает приложению код ETIMEDOUT либо, если маршрутизатор прислал ICMP-сообщение о недоступности хоста или сети, соответственно код EHOSTUNREACH или ENETUNREACH.
Первая проблема, с которой сталкиваются приложения, нуждающиеся в немедленном уведомлении, при попытке воспользоваться механизмом контролеров, - это длительность временных интервалов. В соответствии с RFC 1122 [Braden 1989], если TCP реализует механизм контролеров, то по умолчанию время простоя должно быть не менее двух часов. И только после этого можно посылать контролеров. Затем, поскольку АСК, посланный удаленным хостом, доставляется ненадежно, процесс отправки контролеров необходимо несколько раз повторить; и лишь тогда можно разрывать соединение. В системе 4.4BSD отправляется девять контролеров с интервалом 75 с.
Примечание: Точные величины - деталь реализации. В RFC 1122 не говорится о том, сколько и с каким интервалом нужно посылать контролеры, прежде чем разорвать соединение. Утверждается лишь, что реализация не должна интерпретировать отсутствие ответа на посылку одного контролера как индикатор прекращения соединения.
Таким образом, в реализациях на основе BSD для обнаружения потери связи потребуется 2 ч 11 мин 15 с. Этот срок приобретает смысл, если вы понимаете, что назначение контролеров - освободить ресурсы, занятые уже несуществующими соединениями. Такое возможно, например, если клиент соединяется с сервером, а затем хост клиента неожиданно отключается. Без механизма дежурных серверу пришлось бы ждать следующего запроса от клиента вечно, поскольку он не получит FIN
Примечание: Эта ситуация очень распространена из-за ошибок пользователей персональных компьютеров, которые просто выключают компьютер или модем, не завершив корректно работающие приложения.
В некоторых реализациях разрешено изменять один или оба временных интервала, но это всегда распространяется на систему в целом. Иными словами, изменение затрагивает все TCP-соединения, установленные данной системой, и есть основная причина, по которой механизм контролеров почти бесполезен в качестве средства мониторинга связи. Период, выбранный по умолчанию, слишком велик, а если его сократить, то контролеры перестанут выполнять свою исходную задачу - обнаруживать давно «зависшие» соединения.
В последней версии стандарта POSIX появилась новейшая опция сокета TCP_KEEPALIVE, которая позволяет устанавливать временной интервал для отдельного соединения, но пока она не получила широкого распространения.
Еще одна проблема, связанная с механизмом контролеров, состоит в том, что он не просто обнаруживает «мертвые» соединения, а еще и разрывает их независимо от того, допускает ли это приложение.
Модель OSI
Наверное, самый известный пример многоуровневой схемы сетевых протоколов- это эталонная модель открытого взаимодействия систем (Reference Model of Open Systems Interconnection), предложенная Международной организацией по стандартизации (ISO).
Примечание: Многие ошибочно полагают, что в модели OSI были впервые введены концепции разбиения на уровни, виртуализации и многие другие. На самом деле, эти идеи были хорошо известны и активно применялись разработчиками сети ARPANET, которые создали семейство протоколов TCP/IP задолго до появления модели OSI. Об истории этого вопроса вы можете узнать в RFC 871 [Padlipsky 1982].
Поскольку в этой модели семь уровней (рис. 2.23), ее часто называют семиуровневой моделью OSI.

Рис. 2.23. Семиуровневая талонная модель OSI
Как уже отмечалось, уровень N предоставляет сервисы уровню N+1 и пользуется сервисами, предоставляемыми уровнем N-1. Кроме того, каждый уровень может взаимодействовать только со своими непосредственными соседями сверху и снизу. Это взаимодействие происходит посредством четко определенных интерфейсов между соседними уровнями, поэтому в принципе реализацию любого уровня можно заменить при условии, что новая реализация предоставляет в точности те же сервисы, и это не отразит на остальных уровнях. Одноименные уровни в коммуникационных стеках обмениваются данными (по сети) с помощью протоколов.
Эти уровни часто упоминаются в литературе по вычислительным сетям. Каждый из них предоставляет следующие сервисы:
физический уровень. Этот уровень связан с аппаратурой. Здесь определяю электрические и временные характеристики интерфейса, способ передачи битов физическому носителю, кадрирование и даже размеры и форма разъемов
канальный уровень. Это программный интерфейс к физическому уровню. В его задачу входит предоставление надежной связи с последним. На этом вне находятся драйверы устройств, используемые сетевым уровнем для общения с физическими устройствами. Кроме того, этот уровень обеспечивает формирование кадров для канала, проверку контрольных сумм с целью обнаружения искажения данных и управление совместным доступом к физическому носителю. Обычно задача интерфейса между сетевым и канальным уровнями - создание механизма, обеспечивающего независимость от конкретного устройства;
сетевой уровень. Этот уровень занимается доставкой пакетов от одного узла другому. Он отвечает за адресацию и маршрутизацию, фрагментацию и сборку, а также за управление потоком и предотвращение перегрузок;
транспортный уровень. Реализует надежную сквозную связь между узлами сети, а также управление потоком и предотвращение перегрузок. Он компенсирует ненадежность, присущую нижним уровням, за счет обработки ошибок, которые вызваны искажением данных, потерей пакетов и их доставкой не по порядку;
сеансовый уровень. Транспортный уровень предоставляет надежный полнодуплексный коммуникационный канал между двумя узлами. Сеансовый уровень добавляет такие сервисы, как организация и уничтожение сеанса (например, вход в систему и выход из нее), управление диалогом (эмуляция полудуплексного терминала), синхронизация (создание контрольных точек при передаче больших файлов) и иные надстройки над надежным протоколом четвертого уровня;
уровень представления. Отвечает за представление данных, например, преобразование форматов (скажем, из кода ASCII в код EBCDIC) и сжатие;
прикладной уровень. На нем располагаются пользовательские программы, использующиеся остальными четырьмя уровнями для обмена данными. Известные из мира TCP/IP примеры - это telnet, ftp, почтовые клиенты и Web-браузеры.
Официальное описание семиуровневой модели OSI приведено в документе International Standards Organization 1984], но оно лишь в общих чертах декларирует, что должен делать каждый уровень. Детальное описание сервисов, предоставляемых протоколами на отдельных уровнях, содержится в других документах ISO. Довольно подробное объяснение модели и ее различных уровней со ссылками на соответствующие документы ISO можно найти в работе (Jain and Agrawala 1993].
Хотя модель OSI полезна как основа для обсуждения сетевых архитектур и реализаций, ее нельзя рассматривать как готовый чертеж для создания любой сетевой архитектуры. Не следует также думать, что размещение некоторой функции на уровне N в этой модели означает, что только здесь наилучшее для нее место.
Модель OSI имеет множество недостатков. Хотя, в конечном итоге, были созданы работающие реализации, протоколы OSI на сегодняшний день утратили актуальность. Основные проблемы этой модели в том, что, во-первых, распределение функций между уровнями произвольно и не всегда очевидно, во-вторых, она была спроектирована (комитетом) без готовой реализации. Вспомните, как разрабатывался TCP/IP, стандарты которого основаны на результатах экспериментов.
Другая проблема модели OSI - это сложность и неэффективность. Некоторые функции выполняются сразу на нескольких уровнях. Так, обнаружение и исправление ошибок происходит на большинстве уровней.
Как отмечено в книге [Tanenbaum 1996], один из основных дефектов модели OSI состоит в том, что она страдает «коммуникационной ментальностью». Это относится и к терминологии, отличающейся от общеупотребительной, и к спецификации примитивов интерфейсов между уровнями, которые более пригодны для телефонных, а не вычислительных сетей.
Наконец, выбор именно семи уровней продиктован, скорее, политическими, а не техническими причинами. В действительности сеансовый уровень и уровень представления редко встречаются в реально работающих сетях.
Модель TCP/IP
Сравним модель OSI с моделью TCP/IP. Важно отдавать себе отчет в том, что модель TCP/IP документирует дизайн семейства протоколов TCP/IP. Ее не предполагалось представлять в качестве эталона, как модель OSI. Поэтому никто и не рассматривает ее как основу для проектирования новых сетевых архитектур. Тем не менее поучительно сравнить две модели и посмотреть, как уровни TCP/IP отображаются на уровни модели OSI. По крайней мере, это напоминает, что модель OSI - не единственный правильный путь.

Рис. 2.24. Сравнение модели OSI и стека TCP/IP
Как видно из рис. 2.24, стек протоколов TCP/IP состоит из четырех уровней. На прикладном уровне решаются все задачи, свойственные прикладному уровню, уровню представления и сеансовому уровню модели OSI. Транспортный уровень аналогичен соответствующему уровню в OSI и занимается сквозной доставкой. На транспортном уровне определены протоколы TCP и UDP, на межсетевом протоколы IP, ICMP и IGMP (Internet Group Management Protocol). Он соответствует сетевому уровню модели OSI.
Примечание: С протоколом IP вы уже знакомы. ICMP (Internet Control Message Protocol) - это межсетевой протокол контрольных сообщений, который используется для передачи управляющих сообщений и информации об ошибках между системами. Например, сообщение «хост недоступен» передается по протоколу ICMP, равно как запросы и ответы, формируемые утилитой ping. IGMP (Internet Group Management Protocol) - это межсетевой протокол управления группами, с помощью которого хосты сообщают маршрутизаторам, поддерживающим групповое вещание, о принадлежности к локальным группам. Хотя сообщения протоколов ICMP и IGMP передаются в виде IP-датаграмм, они рассматриваются как неотъемлемая часть IP, а не как протоколы более высокого уровня.
Интерфейсный уровень отвечает за взаимодействие между компьютером и физическим сетевым оборудованием. Он приблизительно соответствует канальному и физическому уровням модели OSI. Интерфейсный уровень по-настоящему не описан в документации по архитектуре TCP/IP. Там сказано только, что он обеспечивает доступ к сетевой аппаратуре системно-зависимым способом.
Прежде чем закончить тему уровней в стеке TCP/IP, рассмотрим, как происходит общение между уровнями стека протоколов в компьютерах на разных концах сквозного соединения. На рис. 2.25 изображены два стека TCP/IP на компьютерах, между которыми расположено несколько маршрутизаторов.
Вы знаете, что приложение передает данные стеку протоколов. Потом они опускаются вниз по стеку, передаются по сети, затем поднимаются вверх по стеку протоколов компьютера на другом конце и наконец попадают в приложение. Но три этом каждый уровень стека работает так, будто на другом конце находится только этот уровень и ничего больше. Например, если в качестве приложения выступает FTP, то FTP-клиент «говорит» непосредственно с FTP-сервером, не имея сведений о том, что между ними есть TCP, IP и физическая сеть.
Это верно и для других уровней. Например, если на транспортном уровне используется протокол TCP, то он общается только с протоколом TCP на другом конце, не зная, какие еще протоколы и сети используются для поддержания «беседы». В идеале должно быть так: если уровень N посылает сообщение, то уровень N на другом конце принимает только его, а все манипуляции, произведенные над этим сообщением нижележащими уровнями, оказываются невидимыми.
Последнее замечание требует объяснения. На рис. 2.25 вы увидите, что транспортный уровень - самый нижний из сквозных уровней, то есть таких, связь между которыми устанавливается без посредников. Напротив, в «разговоре» на межсетевом уровне участвуют маршрутизаторы или полнофункциональные компьютеры, расположенные на маршруте сообщения.
Примечание: Предполагается наличие промежуточных маршрутизаторов, то есть сообщение не попадает сразу в конечный пункт.

Рис. 2.25. Сквозная сеть
Но промежуточные системы могут изменять некоторые поля, например, время существования датаграммы (TTL - time to live) в IP-заголовке. Поэтому межсетевой уровень в пункте назначения может «видеть» не в точности то же сообщение, что межсетевой уровень, который его послал.
Этот подчеркивает различие между межсетевым и транспортным уровням. Межсетевой уровень отвечает за доставку сообщений в следующий узел на маршруте. И он общается с межсетевым уровнем именно этого узла, а не с межсетевым уровнем в конечной точке. Транспортные же уровни контактируют напрямую, не имея информации о существовании промежуточных систем.
Недостаточная производительность
Чтобы получить представление о такого рода проблемах, изменим программы hb_server (листинг 2.25) и hb_client (листинг 2.24), задав Т1, равным 2 с, а Т2 -1 с (листинг 2.23). Тогда пульс будет посылаться каждые две секунды, и при отсутствии ответа в течение трех секунд приложение завершится.
Сначала запустим эти программы в локальной сети. Проработав почти семь часов, сервер сообщил о пропуске одного пульса 36 раз, а о пропуске двух пульсов - один раз. Клиенту пришлось посылать второй пульс 11 из 12139 раз. И клиент, и сервер работали, пока клиент не остановили вручную. Такие результаты типичны для локальной сети. Если не считать редких и небольших задержек, сообщения доставляются своевременно.
А теперь запустим те же программы в Internet. Спустя всего лишь 12 мин клиент сообщает, что послал три пульса, не получив ответа, и завершает сеанс. Распечатка выходной информации от клиента, частично представленная ниже, показывает, как развивались события:
spare: $ hb_client 205.184.151.171 9000
hb_client: посылаю пульс: #l
hb_client: посылаю пульс: #2
hb_client: посылаю пульс: #3
hb_client: посылаю пульс: #1
hb_client: посылаю пульс: #2
hb_client: посылаю пульс: #1
Много строк опущено.
hb_client: посылаю пульс: #1
hb_client: посылаю пульс: #2
hb-client: посылаю пульс: #1
hb_client: посылаю пульс: #2
hb_client: посылаю пульс: #3
hb_client: посылаю пульс: #1
hb-client: посылаю пульс: #2
hb_client: Соединение завершается через
1с после последнего пульса.
sparc: $
В этот раз клиент послал первый пульс 251 раз, а второй - 247 раз. Таким образом, он почти ни разу не получил вовремя ответ на первый пульс. Десять раз клиенту пришлось посылать третий пульс.
Сервер также продемонстрировал значительное падение производительности. Тайм-аут при ожидании первого пульса происходил 247 раз, при ожидании второго пульса- 5 и при ожидании третьего пульса - 1 раз.
Этот пример показывает, что приложение, которое прекрасно работает в условиях локальной сети, может заметно снизить производительность в глобальной.
Некоторые термины
За немногими исключениями, весь материал этой книги, в том числе примеры программ, предложен для работы в системах UNIX (32 и 64-разрядных) и системах, использующих API Microsoft Windows (Win32 API). Я не экспериментировал c 16-разрядными приложениями Windows. Но и для других платформ почти все остается применимым.
Желание сохранить переносимость привело к некоторым несообразностям в примерах программ. Так, программисты, работающие на платформе UNIX, неодобрительно отнесутся к тому, что для дескрипторов сокетов применяется тип SOCKET вместо привычного int. А программисты Windows заметят, что я ограничился только консольными приложениями. Все принятые соглашения описаны в совете 4.
По той же причине я обычно избегаю системных вызовов read и write для сокетов, так как Win32 API их не поддерживает. Для чтения из сокета или записи в него применяются системные вызовы recv, recvf rom или recvmsg для чтения и send, sendto или sendmsg для записи.
Одним из самых трудных был вопрос о том, следует ли включать в книгу материал по протоколу IPv6, который в скором времени должен заменить современную версию протокола IP (IPv4). В конце концов, было решено не делать этого. Тому есть много причин, в том числе:
почти все изложенное в книге справедливо как для IPv4, так и для IPv6;
различия, которые все-таки имеются, по большей части сосредоточены в тех частях API, которые связаны с адресацией;
книга представляет собой квинтэссенцию опыта и знаний современных сетевых программистов, а реального опыта работы с протоколом IPv6 еще не накоплено.
Поэтому, если речь идет просто об IP, то подразумевается IPv4. Там, где упоминается об IPv6, об этом написано.
И, наконец, я называю восемь бит информации байтом. В сетевом сообществе принято называть такую единицу октетом - по историческим причинам. Когда-то размер байта зависел от платформы, и не было единого мнения о его точной длине. Чтобы избежать неоднозначности, в ранней литературе по сетям и был придуман термин октет. Но сегодня все согласны с тем, что длина байта равна восьми битам [Kernighan and Pike 1999], так что употребление этого термина можно считать излишним педантизмом.
Примечание: Однако утверждения о том, что длина байта равна восьми битам, время от времени все же вызывают споры в конференциях Usenet: «Ох уж эта нынешняя молодежь! Я в свое время работал на машине Баста-6, в которой байт был равен пяти с половиной битам. Так что не рассказывайте мне, что в байте всегда восемь бит».
Низкая производительность ttcp
Следующая ситуация - это продолжение примера из совета 36. Помните, что при размере буфера равном MSS соединения, время передачи 16 Мб возросло с 1,3 с до почти 41 мин.
На рис. 4.18 приведена репрезентативная выборка из результатов прогона ktrace для этого примера.
12512 ttcp 0.000023 CALL write(0x3,0x8050000, 0x2000)
12512 ttcp 1.199605 GIO fd 3 wrote 8192 bytes
“”
12512 ttcp 0.000442 RET write 8192/0x2000
12512 ttcp 0.000022 CALL write(0x3,0x8050000 , 0x2000)
12512 ttcp 1.199574 GIO fd 3 wrote 8192 bytes
“”
12512 ttcp 0.000442 RET write 8192/0x2000
12512 ttcp 0.000023 CALL write(0x3,0x8050000 , 0x2000)
12512 ttcp 1.199514 GIO fd 3 wrote 8192 bytes
“”
12512 ttcp 0.000432 RET write 8192/0x2000
Рис. 4.18. Выборка из результатов проверки ttcp -tsvb 1448 bsd под управлением ktrace
Вызвана kdump со следующими опциями:
kdump -R -m -l
для печати интервалов времени между вызовами и запрета вывода 8 Кб данных, ассоциированных с каждым системным вызовом.
Время каждой операции записи колеблется около значения 1,2 с. На рис. 4.19 для сравнения приведены результаты эталонного теста. На этот раз разброс значений несколько больше, но среднее время записи составляет менее 0,5 мс.
Большее время в записях типа GIO на рис. 4.18 по сравнению с временем на рис. 4.19 наводит на мысль, что операции записи блокировались в ядре (совет 36). Тогда становится понятна истинная причина столь резкого увеличения времени передачи.
12601 ttcp 0.000033 CALL write(0x3,0x8050000, 0x2000) 12601 ttcp 0.000279 GIO fd 3 wrote 8192 bytes
“”
12601 ttcp 0.000360 RET write 8192/0x2000
12601 ttcp 0.000033 CALL write(0x3,0x8050000, 0x2000)
12601 ttcp 0.000527 GIO fd 3 wrote 8192 bytes
“”
12601 ttcp 0.000499 RET write 8192/0x2000
12601 ttcp 0.000032 CALL write(0x3,0x8050000, 0x2000)
12601 ttcp 0.000282 GIO fd 3 wrote 8192 bytes
“”
12601 ttcp 0.000403 RET write 8192/0x2000
Рис. 4.19. Репрезентативная выборка из результатов проверки ttcp –tsvbsd под управлением ktrace
Ограниченное вещание
Адрес для ограниченного вещания - 255.255.255.255. Вещание называется ограниченным, поскольку датаграммы, посланные на этот адрес, не уходят дальше маршрутизатора. Они ограничены локальным кабелем. Такое широковещание применяется, главным образом, во время начальной загрузки, если хосту неизвестен свой IP-адрес или маска своей подсети.
Процесс передачи широковещательной датаграммы хостом, имеющим несколько сетевых интерфейсов, зависит от реализации. Во многих реализациях датаграмма отправляется только по одному интерфейсу. Чтобы приложение отправил широковещательную датаграмму по нескольким интерфейсам, ему необходим узнать у операционной системы, какие интерфейсы сконфигурированы для поддержки широковещания.
Операция записи с точки зрения приложения
Когда пользователь выполняет запись в TCP-соединение, данные сначала копируются из буфера пользователя в память ядра. Дальнейшее зависит от состояния соединения. TCP может «решить», что надо послать все данные, только часть или ничего не посылать. О том, как принимается решение, будет сказано ниже. Сначала рассмотрим операцию записи с точки зрения приложения.
Хочется думать, что если операция записи n байт вернула значение n, то все эти n байт, действительно, переданы на другой конец и, возможно, уже подтверждены. Увы, это не так. TCP посылает столько данных, сколько возможно (или ничего), и немедленно возвращает значение n. Приложение не определяет, какая часть данных послана и были ли они подтверждены.
В общем случае операция записи не блокирует процесс, если только буфер передачи TCP не полон. Это означает, что после записи управление почти всегда быстро возвращается программе. После получения управления нельзя ничего гарантировать относительно местонахождения «записанных» данных. Как упоминается в совете 9, это имеет значение для надежности передачи данных.
С точки зрения приложения данные записаны. Поэтому, помня о гарантиях доставки, предлагаемых TCP, можно считать, что информация дошла до другого конца. В действительности, некоторые (или все) эти данные в момент возврата из операции записи могут все еще стоять в очереди на передачу. И если хост или приложение на другом конце постигнет крах, то информация будет потеряна.
Примечание: Если отправляющее приложение завершает сеанс аварийно, то TCP все равно будет пытаться доставить данные.
Еще один важный момент, который нужно иметь в виду, - это обработка ошибки записи. Если при записи на диск вызов write не вернул код ошибки, то точно известно, что запись была успешной.
Примечание: Строго говоря, это неверно. Обычно данные находятся в буфере в пространстве ядра до того момента, пока не произойдет сброс буферов на диск. Поэтому если до этого момента система «упадет», то данные вполне могут быть потеряны. Но суть в том, что после возврата из write уже не будет никаких сообщений об ошибках. Можно признать потерю не сброшенных на диск данных неизбежной, но не более вероятной, чем отказ самого диска.
При работе с TCP получение кода ошибки от операции записи - очень редкое явление. Поскольку операция записи возвращает управление до фактической от правки данных, обычно ошибки выявляются при последующих операциях, о чем говорилось в совете 9. Так как следующей операцией чаще всего бывает чтение, предполагается, что ошибки записи обнаруживаются при чтении. Операция записи возвращает лишь ошибки, очевидные в момент вызова, а именно:
неверный дескриптор сокета;
файловый дескриптор указывает не на сокет (в случае вызова send и родственных функций);
указанный при вызове сокет не существует или не подсоединен;
в качестве адреса буфера указан недопустимый адрес.
Причина большинства этих проблем - ошибка в программе. После завершения стадии разработки они почти не встречаются. Исключение составляет код ошибки EPIPE (или сигнал SIGPIPE), который свидетельствует о сбросе соединения хостом на другом конце. Условия, при которых такая ошибка возникает, обсуждались в совете 9 при рассмотрении краха приложения-партнера.
Подводя итог этим рассуждениям, можно сказать, что применительно к TCP соединениям операцию записи лучше представлять себе как копирование в очередь для передачи, сопровождаемое извещением TCP о появлении новых данных. Понятно, какую работу TCP произведет дальше, но эти действия будут асинхронны по отношению к самой записи.
Операция записи с точки зрения TCP
Как отмечалось выше, операция записи отвечает лишь за копирование данных из буфера приложения в память ядра и уведомление TCP о том, что появились данные для передачи. А теперь рассмотрим некоторые из критериев, которыми руководствуется TCP, «принимая решение» о том, можно ли передать новые данные незамедлительно и в каком количестве. Я не задаюсь целью полностью объяснить логику отправки данных в TCP, а хочу лишь помочь вам составить представление о факторах, влияющих на эту логику. Тогда вы сможете лучше понять принципы работы своих программ.
Одна из основных целей стратегии отправки данных в TCP - максимально эффективное использование имеющейся полосы пропускания. TCP посылает данные блоками, размер которых равен MSS (maximum segment size - максимальный размер сегмента).
Примечание: В процессе установления соединения TCP на каждом конце может указать приемлемый для него MSS. TCP на другом конце обязан удовлетворить это пожелание и не посылать сегменты большего размера. MSS вычисляется на основе MTU (maximum transmission unit - максимальный размер передаваемого блока),как описано в совете 7.
В то же время TCP не может переполнять буферы на принимающем конце. Как вы видели в совете 1, это определяется окном передачи.
Если бы эти два условия были единственными, то стратегия отправки была бы проста: немедленно послать все имеющиеся данные, упаковав их в сегменты размером MSS, но не более чем разрешено окном передачи. К сожалению, есть и другие факторы.
Прежде всего, очень важно не допускать перегрузки сети. Если TCP неожиданно пошлет в сеть большое число сегментов, может исчерпаться память маршрутизатора, что повлечет за собой отбрасывание датаграмм. А из-за этого начнутся повторные передачи, что еще больше загрузит сеть. В худшем случае сеть будет загружена настолько, что датаграммы вообще нельзя будет доставить. Это называется затором (congestion collapse). Чтобы избежать перегрузки, TCP не посылает по простаивающему соединению все сегменты сразу. Сначала он посылает один сегмент и постепенно увеличивает число неподтвержденных сегментов в сети, пока не будет достигнуто равновесие.
Примечание: Эту проблему можно наглядно проиллюстрировать таким примером. Предположим, что в комнате, полной народу, кто-то закричал: «Пожар!» Все одновременно бросаются к дверям, возникает давка, и в результате никто не может выйти. Если же люди будут выходить по одному, то пробки не возникнет, и все благополучно покинут помещение.
Для предотвращения перегрузки TCP применяет два алгоритма, в которых используется еще одно окно, называемое окном перегрузки. Максимальное число байтов, которое TCP может послать в любой момент, - это минимальная из двух величин: размер окна передачи и размер окна перегрузки. Обратите внимание, что эти окна отвечают за разные аспекты управления потоком. Окно передачи, декларируемое TCP на другом конце, предохраняет от переполнения его буферов. Окно перегрузки, отслеживаемое TCP на вашем конце, не дает превысить пропускную способность сети. Ограничив объем передачи минимальным из этих двух окон, вы удовлетворяете обоим требованиям управления потоком.
Первый алгоритм управления перегрузкой называется «медленный старт». Он постепенно увеличивает частоту передачи сегментов в сеть до пороговой величины.
Примечание: Слово «медленный» взято в кавычки, поскольку на самом деле нарастание частоты экспоненциально. При медленном старте окно перегрузки открывается на один сегмент при получении каждого АСК. Если вы начали с одного сегмента, то последовательные размеры окна будут составлять 1,2, 4, 8 и т.д.
Когда размер окна перегрузки достигает порога, который называется порогом медленного старта, этот алгоритм прекращает работу, и в дело вступает алгоритм избежания перегрузки. Его работа предполагает, что соединение достигло равновесного состояния, и сеть постоянно зондируется - не увеличилась ли пропускная способность. На этой стадии окно перегрузки открывается линейно — по одному сегменту за период кругового обращения.
В стратегии отправки TCP окно перегрузки в принципе может запретить посылать данные, которые в его отсутствие можно было бы послать. Если происходит перегрузка (о чем свидетельствует потерянный сегмент) или сеть некоторое время простаивает, то окно перегрузки сужается, возможно, даже до размера одного сегмента. В зависимости от того, сколько данных находится в очереди, и сколько их пытается послать приложение, это может препятствовать отправке всех данных.
Авторитетным источником информации об алгоритмах избежания перегрузки является работа Jacobson 1988], в которой они впервые были предложены. Джекобсон привел результаты нескольких экспериментов, демонстрирующие заметное повышение производительности сети после внедрения управления перегрузкой. В книге [Stevens-1994] содержится подробное объяснение этих алгоритмов и результаты трассировки в локальной сети. В настоящее время эти алгоритмы следует включать в любую реализацию, согласующуюся со стандартом (RFC 1122 [Braden 1989]).
Примечание: Несмотря на впечатляющие результаты, реализация этих алгоритмов очень проста— всего две переменные состояния и несколько строчек кода. Детали можно найти в книге [Wright and Stevens 1995].
Еще один фактор, влияющий на стратегию отправки TCP, - алгоритм Нейгла. Этот алгоритм впервые предложен в RFC 896 [Nagle 1984]. Он требует, чтобы никогда не было более одного неподтвержденного маленького сегмента, то есть сегмента размером менее MSS. Цель алгоритма Нейгла — не дать TCP забить сеть последовательностью мелких сегментов. Вместо этого TCP сохраняет в своих буферах небольшие блоки данных, пока не получит подтверждение на предыдущий маленький сегмент, после чего посылает сразу все накопившиеся данные. В совете 24 вы увидите, что отключение алгоритма Нейгла может заметно сказаться на производительности приложения.
Если приложение записывает данные небольшими порциями, то эффект от алгоритма Нейгла очевиден. Предположим, что есть простаивающее соединение, окна передачи и перегрузки достаточно велики, а выполняются подряд две небольшие операции записи. Данные, записанные вначале, передаются немедленно, поскольку окна это позволяют, а алгоритм Нейгла не препятствует, так как неподтвержденных данных нет (соединение простаивало). Но, когда до TCP доходят данные, полученные при второй операции, они не передаются, хотя в окнах передачи и перегрузки есть место. Поскольку уже есть один неподтвержденный маленький сегмент, и алгоритм Нейгла требует оставить данные в очереди, пока не придет АСК.
Обычно при реализации алгоритма Нейгла не посылают маленький сегмент, если есть неподтвержденные данные. Такая процедура рекомендована RFC 1122. Но реализация в BSD (и некоторые другие) несколько отходит от этого правила и отправляет маленький сегмент, если это последний фрагмент большой одновременно записанной части данных, а соединение простаивает. Например, MSS для простаивающего соединения равен 1460 байт, а приложение записывает 1600 байт. При этом TCP пошлет (при условии, что это разрешено окнами передачи и перегрузки) сначала сегмент размером 1460, а сразу вслед за ним, не дожидаясь подтверждения, сегмент размером 140. При строгой интерпретации алгоритма Нейгла следовало бы отложить отправку второго сегмента либо до подтверждения первого, либо до того, как приложение запишет достаточно данных для формирования полного сегмента.
Алгоритм Нейгла - это лишь один из двух алгоритмов, позволяющих избежать синдрома безумного окна (SWS - silly window syndrome). Смысл этой тактики в том, чтобы не допустить отправки небольших объемов данных. Синдром SWS и его отрицательное влияние на производительность обсуждаются в RFC 813 [Clark 1982]. Как вы видели, алгоритм Нейгла пытается избежать синдрома SWS со стороны отправителя. Но требуются и усилия со стороны получателя, который не должен декларировать слишком маленькие окна.
Напомним, что окно передачи дает оценку свободного места в буферах хоста на другом конце соединения. Этот хост объявляет о том, сколько в нем имеется места, включая в каждый посылаемый сегмент информацию об обновлении окна. Чтобы избежать SWS, получатель не должен объявлять о небольших изменениях.
Следует пояснить это на примере. Предположим, у получателя есть 14600 свободных байт, a MSS составляет 1460 байт. Допустим также, что приложением на Конце получателя читается за один раз всего по 100 байт. Отправив получателю 10 сегментов, окно передачи закроется. И вы будете вынуждены приостановить отправку данных. Но вот приложение прочитало 100 байт, в буфере приема 100 байт освободилось. Если бы получатель объявил об этих 100 байтах, то вы тут же послали бы ему маленький сегмент, поскольку TCP временно отменяет алгоритм Нейгла, если из-за него длительное время невозможно отправить маленький сегмент. Вы и дальше продолжали бы посылать стобайтные пакеты, так как всякий раз, когда приложение на конце получателя читает очередные 100 байт, получатель объявляет освобождении этих 100 байт, посылая информацию об обновлении окна.
Алгоритм избежания синдрома SWS на получающем конце не позволяет объявлять об обновлении окна, если объем буферной памяти значительно не увеличился. В RFC 1122 «значительно» - это на размер полного сегмента или более чем на половину максимального размера окна. В реализациях, производных от BSD, требуется увеличение на два полных сегмента или на половину максимального размера окна.
Может показаться, что избежание SWS со стороны получателя излишне (поскольку отправителю не разрешено посылать маленькие сегменты), но в действительности это защита от тех стеков TCP/IP, в которых алгоритм Нейгла не реализован или отключен приложением (совет 24). RFC 1122 требует от реализаций TCP, удовлетворяющих стандарту, осуществлять избежание SWS на обоих концах.
На основе этой информации теперь можно сформулировать стратегию отправки, принятую в реализациях TCP, производных от BSD. В других реализациях стратегия может быть несколько иной, но основные принципы сохраняются.
При каждом вызове процедуры вывода TCP вычисляет объем данных, которые можно послать. Это минимальное значение количества данных в буфере передачи, размера окон передачи и перегрузки и MSS. Данные отправляются при выполнении хотя бы одного из следующих условий:
можно послать полный сегмент размером MSS;
соединение простаивает, и можно опустошить буфер передачи;
алгоритм Нейгла отключен, и можно опустошить буфер передачи;
есть срочные данные для отправки;
есть маленький сегмент, но его отправка уже задержана на достаточно дли тельное время;
Примечание: Если у TCP есть маленький сегмент, который запрещено посылать, то он взводит таймер на то время, которое потребовалось бы для ожидания АСК перед повторной передачей (но в пределах 5-60 с). Иными словами, устанавливается тайм-аут ретрансмиссии (RТО). Если этот таймер, называемый таймером терпения (persist timer), срабатывает, то TCP все-таки посылает сегмент при условии, что это не противоречит ограничениям, которые накладывают окна передачи и перегрузки. Даже если получатель объявляет окно размером нуль байт, TCP все равно попытается послать один байт. Это делается для того, чтобы потерянное обновление окна не привело к тупиковой ситуации.
окно приема, объявленное хостом на другом конце, открыто не менее чем наполовину;
необходимо повторно передать сегмент;
требуется послать АСК на принятые данные;
нужно объявить об обновлении окна.