Маршрутизатор или шлюз?
Небольшое замечание о терминологии.
С точки зрения топологии соединений G2 (рис. 2.3.2) является собственно маршрутизатором (router), так как он коммутирует потоки дейтаграмм между своими многочисленными IP-интерфейсами, в то время как G1 является шлюзом (gateway) — интерфейсом между двумя разнородными средами передачи данных (локальной сетью Ethernet и выделенной линией). Все дейтаграммы, идущие вовне локальной сети, он безусловно транслирует на G2, и только G2 приступает именно к маршрутизации. Однако, с точки зрения общего подхода к задаче маршрутизации как определения следующего маршрутизатора в пути дейтаграммы на основе записей в таблице маршрутов, функции G1 и G2 не различаются, различается только сложность их маршрутных таблиц. Поэтому мы будем считать термины “маршрутизатор” (“router”) и “шлюз” (“gateway”) синонимами и будем использовать термин “шлюз”, говоря о маршрутизаторе, расположенном между локальной сетью конечного пользователя (например, сетью предприятия) и “внешним миром”.
Методы и инструменты
Для достижения своих целей злоумышленник использует прослушивание (sniffing), сканирование сети и генерацию пакетов. Под генерацией пакетов понимается создание и отправка специально сконструированных датаграмм или кадров, позволяющих злоумышленнику выполнить ту или иную атаку. Особо выделим здесь фальсификацию пакетов, то есть создание IP-датаграмм или кадров уровня доступа к сети, направленных якобы от другого узла (spoofing).
Метрики
Метрика представляет собой оценку качества связи в данной сети (на данном физическом канале); чем меньше метрика, тем лучше качество соединения. Метрика маршрута равна сумме метрик всех связей (сетей), входящих в маршрут. В простейшем случае (как это имеет место в протоколе ) метрика каждой сети равна единице, а метрика маршрута тогда просто является его длиной в хопах.
Поскольку при работе алгоритма SPF ситуации, приводящие к счету до бесконечности, отсутствуют, значения метрик могут варьироваться в широком диапазоне. Кроме того, протокол OSPF позволяет определить для любой сети различные значения метрик в зависимости от типа сервиса. (Тип сервиса запрашивается дейтаграммой в соответствии со значением поля TOS ее заголовка, см. ) Для каждого типа сервиса будет вычисляться свой маршрут, и дейтаграммы, затребовавшие наиболее скоростной канал, могут быть отправлены по одному маршруту, а затребовавшие наименее дорогостоящий канал - по другому.
Метрика сети, оценивающая пропускную способность, определяется как количество секунд, требуемое для передачи 100 Мбит через физическую среду данной сети. Например, метрика сети на базе 10Base-T Ethernet равна 10, а метрика выделенной линии 56 кбит/с равна 1785. Метрика канала со скоростью передачи данных 100 Мбит/с и выше равна единице.
Порядок расчета метрик, оценивающих надежность, задержку и стоимость, не определен. Администратор, желающий поддерживать маршрутизацию по этим типам сервисов, должен сам назначить разумные и согласованные метрики по этим параметрам.
Если не требуется маршрутизация с учетом типа сервиса (или маршрутизатор ее не поддерживает), используется метрика по умолчанию, равная метрике по пропускной способности.
В нашем примере мы будем использовать метрики, указанные на рисунке, без учета типов сервиса. Следует заметить, что маршрутизация по типам сервиса крайне редка, более того, она исключена из последних версий стандарта OSPF.
Межсетевой уровень и протокол IP
Основным протоколом этого уровня является протокол IP (Internet Protocol).
Протокол IP доставляет блоки данных, называемых дейтаграммами, от одного IP-адреса к другому. IP-адрес является уникальным 32-битным идентификатором компьютера (точнее, его сетевого интерфейса). Данные для дейтаграммы передаются IP-модулю транспортным уровнем. IP-модуль предваряет эти данные заголовком, содержащим IP-адреса отправителя и получателя и другую служебную информацию, и сформированная таким образом дейтаграмма передается на уровень доступа к среде передачи (например, одному из физических интерфейсов) для отправки по каналу передачи данных.
Не все компьютеры могут непосредственно связаться друг с другом; часто для того, чтобы передать дейтаграмму по назначению, требуется направить ее через один или несколько промежуточных компьютеров по тому или иному маршруту. Задача определения маршрута для каждой дейтаграммы решается протоколом IP.
Когда модуль IP получает дейтаграмму с нижнего уровня, он проверяет IP-адрес назначения. Если дейтаграмма адресована данному компьютеру, то данные из нее передаются на обработку модулю вышестоящего уровня (какому конкретно - указано в заголовке дейтаграммы). Если же адрес назначения дейтаграммы - чужой, то модуль IP может принять два решения: первое - уничтожить дейтаграмму, второе - отправить ее дальше к месту назначения, определив маршрут следования - так поступают промежуточные станции - маршрутизаторы.
Также может потребоваться, на границе сетей с различными характеристиками, разбить дейтаграмму на фрагменты, а потом собрать в единое целое на компьютере-получателе. Это тоже задача протокола IP.
Если модуль IP по какой-либо причине не может доставить дейтаграмму, она уничтожается. При этом модуль IP может отправить компьютеру-источнику этой дейтаграммы уведомление об ошибке; такие уведомления отправляются с помощью протокола ICMP, являющегося неотъемлемой частью модуля IP. Более никаких средств контроля корректности данных, подтверждения их доставки, обеспечения правильного порядка следования дейтаграмм, предварительного установления соединения между компьютерами протокол IP не имеет. Эта задача возложена на транспортный уровень.
Многие IP-адреса имеют эквивалентную форму записи в виде доменного имени (например, IP-адрес 194.84.124.4 может быть записан как maria.vvsu.ru). Преобразование между этими двумя формами выполняется службой DNS (Domain Name Service). Доменные имена обсуждаются в курсе “Введение в Интернет”, служба DNS рассматривается в курсе . Доменные имена введены для удобства использования человеком. Все TCP/IP-процессы и коммуникационное оборудование используют только IP-адреса.
Протоколы IP и ICMP подробно рассмотрены в .
MOSPF
Протокол MOSPF (Multicast OSPF, RFC-1584) является расширением протокола OSPF. Маршрутизатор, поддерживающий это расширение, устанавливает бит "М" в поле "Options" сообщения "Hello". В базе данных состояния связей вводится дополнительный тип записи: для указанной сети перечисляются все группы, члены которых есть в этой сети. Эти записи, как и все прочие записи базы данных состояния связей, распространяются по системе сетей с помощью протокола веерной рассылки. Для транзитной сети запись вносится в базу данных выделенным маршрутизатором.
Деревья рассылки групповых дейтаграмм строятся по методу RPF на основе базы данных состояния связей. Отметим, что рассылка "пробных" групповых дейтаграмм и последующее усечение ненужных ветвей дерева в данном случае не производится, так как информация о наличии в сетях членов групп уже содержится в базе данных.
Протокол MOSPF имеет серьезную проблему, связанную с масштабированием: для каждой пары "источник-группа" проводится отдельный запуск алгоритма SPF для расчета дерева рассылки. При большом числе источников, а также при нестабильной топологии системы сетей, на эти вычисления затрачиваются существенные вычислительные ресурсы маршрутизаторов. Кроме того, следует учесть необходимость веерной рассылки информации о членстве в группах при ее изменении.
И, наконец, очевидно, что MOSPF требует использования OSPF в качестве протокола маршрутизации, то есть, не является независимым и может применяться только в OSPF-системах.
MULTI_EXIT_DISC
MULTI_EXIT_DISC (тип 4) – необязательный атрибут, представляющий собой приоритет использования объявляющего маршрутизатора для достижения через него анонсируемой сети, то есть фактически это метрика маршрута с точки зрения анонсирующего маршрут BGP-узла. Имеет смысл не само значение а разница значений, когда несколько маршрутизаторов одной АС объявляют о достижимости через себя одной и той же сети, предоставляя таким образом получателям несколько вариантов маршрутов в одну сеть. При прочих равных условиях дейтаграммы в объявляемую сеть будут посылаться через маршрутизатор, заявивший меньшее значение MULTI_EXIT_DISC.
Атрибут сохраняется при последующих объявлениях маршрута по IBGP, но не по EBGP.
Накладывающиеся маршруты
Пусть в графе OSPF-системы некий маршрутизатор имеет связи с вершинами N и М, которые представляют сети хостов, подключенные к различным интерфейсам маршрутизатора. Это означает, что в таблице маршрутов этого маршрутизатора, будет две записи: одна для сети N, другая для сети M.
Предположим теперь, что адрес и маска сети М таковы, что она является подсетью сети N. Например, N=172.16.0.0 netmask 255.255.0.0; M=172.16.5.0 netmask 255.255.255.0.
В этом случае дейтаграммы, следующие по адресу, находящемуся в обеих сетях, будут отправлены в сеть с более длинной маской. Например, адрес 172.16.5.1 находится как в сети N, так и в сети М, но маска сети M длиннее, следовательно, дейтаграмма, следующая по этому адресу, будет отправлена в сеть М.
Навязывание ложного маршрутизатора
Для перехвата трафика, направленного от некоторого узла А в другую сеть, злоумышленник может навязать хосту свой адрес в качестве адреса маршрутизатора, которому должны быть переданы отправляемые узлом А данные. В этом случае узел А будет направлять трафик на узел злоумышленника, который после анализа и, возможно, модификации данных, отправит их далее настоящему маршрутизатору.
Ложное сообщение ICMP Redirect
Как правило, навязывание ложного маршрутизатора выполняется с помощью фальсифицированных ICMP-сообщений Redirect, так как документ RFC-1122 требует, чтобы хосты обязательно обрабатывали такие сообщения. В подложном сообщении злоумышленник объявляет свой собственный адрес в качестве адреса маршрутизатора (рис. 9.2).

Рис. 9.2. Навязывание ложного маршрутизатора с помощью ICMP Redirect
Напомним действия хоста А при получении сообщения Redirect. Хост А считает, что Redirect является реакцией на ранее отправленную датаграмму некому хосту В, причем заголовок и первые 64 бита этой датаграммы возвращаются внутри полученного сообщения. Из возвращенного заголовка хост А определяет, что он должен сделать перенаправление для датаграмм, направленных в В, и вносит в свою таблицу маршрутов частный маршрут к хосту В через маршрутизатор, указанный в сообщении Redirect. Следует обратить внимание, что все сообщения Redirect обрабатываются одинаково независимо от кода сообщения — таким образом, посылка Redirect с кодом 0 («перенаправление для сети получателя») не вызовет изменения маршрута в сеть, в которой находится получатель, а приведет к установке частного маршрута к хосту В, как и в случае сообщения с кодом 1.
Сообщение Redirect должно быть отправлено маршрутизатором, который в таблице маршрутов хоста А является следующим маршрутизатором на пути в В, при этом хост В не должен находиться в той же IP-сети, что и А, а новый объявленный маршрутизатор Х, наоборот, обязан находиться в одной IP-сети с хостом А.
Таким образом, для создания ложного сообщения Redirect с целью перехвата трафика между хостами А и В злоумышленник должен находиться в одной IP-сети с А и знать адрес маршрутизатора, через который А отправляет датаграммы в В. Если в сети имеется единственный шлюз, то он и является искомым маршрутизатором. Далее злоумышленник формирует IP-датаграмму, где в качестве адреса отправителя указан IP-адрес шлюза, а получателем является хост А. В датаграмму помещается сообщение Redirect, где в поле Адрес нового маршрутизатора значится IP-адрес злоумышленника, а дальше приводится заголовок произвольной датаграммы, якобы ранее направленной из А в В. Совершенно необязательно приводить там заголовок реальной датаграммы, потому что модуль IP не хранит информацию о ранее отправленных датаграммах. Получившееся сообщение отправляется адресату — хосту А, который считает, что оно прибыло от шлюза и меняет свою таблицу маршрутов. Новый маршрут к хосту В будет действителен в течение нескольких минут, поэтому, чтобы поддерживать его постоянно, злоумышленник должен посылать сфабрикованные сообщения периодически.
Отметим, что трафик из В в А будет по- прежнему направляться маршрутизатором непосредственно хосту А, минуя злоумышленника (рис. 9.2), потому что маршрутизатор и хост А находятся в одной сети, следовательно, маршрутизатор в принципе не может использовать никаких промежуточных узлов для достижения хоста А.
Несмотря на такой «половинчатый» перехват, злоумышленник может просматривать и модифицировать данные, направляемые из А в В, а если он находится в одном сегменте с хостом А или маршрутизатором, то и наблюдать за ответами узла В, направляемыми в А. Более того, злоумышленник может вообще не пересылать датаграммы в узел В, а отвечать на них сам, фабрикуя датаграммы от имени узла В (см. также п. ).
Для устранения возможности описываемой атаки необходимо отключить на хосте обработку сообщений Redirect. Несмотря на то, что это действие противоречит требованиям к хостам, установленным в документе RFC-1122, оно выглядит совершенно разумным, особенно для хостов в сетях с единственным шлюзом, однако не все операционные системы могут поддерживать такое отключение.
Вообще говоря, для пользователя атакуемого узла не составит особого труда раскрыть замысел злоумышленника: полученное сообщение Redirect отобразится в виде неожиданно появившейся строки в таблице маршрутов, направляющей данные для хоста В через узел Х2. Кроме того, программа traceroute скорее всего покажет дополнительный промежуточный узел на пути к В. К сожалению пользователи обычно не заглядывают в таблицу маршрутов и не запускают traceroute, если поведение сетевых программ не вызывает у них подозрений, поэтому злоумышленник имеет хорошие шансы остаться незамеченным.
2Узел Х может и не быть узлом злоумышленника. Затратив определенные усилия на программирование, тот может создать узел-фантом, присвоив ему свободный IP-адрес Х и свободный MAC-адрес. Фабрикуя ARP-ответы от имени узла Х, злоумышленник обеспечит доставку кадров, предназначенных этому узлу, в свой сегмент Ethernet, откуда он может их получить, настроив свою сетевую карты на вымышленный MAC-адрес Х, или извлечь с помощью прослушивания. Использование такой схемы не может скрыть наличия Redirect-атаки, но весьма затрудняет обнаружение злоумышленника.
Атака при конфигурировании хоста
В некоторых случаях навязывание ложного маршрутизатора может быть произведено с помощью ICMP-сообщения Router Advertisement или через протокол DHCP.
Сообщения Router Advertisement могут использоваться хостами для установки маршрута по умолчанию, однако в реальной жизни такое происходит нечасто, так как для удаленного динамического конфигурирования стека TCP/IP хоста обычно используется протокол DHCP. Если же хост все-таки обрабатывает сообщения Router Advertisement, то сформировав подложное сообщение, злоумышленник может перенаправить на себя весь трафик хоста А, адресованный за пределы его сети, а не только трафик, адресованный узлу В. Как и в предыдущем случае, данные на обратном пути будут доставляться маршрутизатором на хост А непосредственно, минуя злоумышленника.
Фальсификация сообщений протокола DHCP будет успешна, если хост конфигурирует себя через этот протокол. В ответ на запрос DHCPDISCOVER злоумышленник оперативно возвращает хосту подложное сообщение DHCPOFFER, где в числе дополнительных параметров указывает себя в качестве маршрутизатора по умолчанию. Чтобы опередить предложение от легитимного сервера, злоумышленник может рассылать DHCPOFFER непрерывно, чтобы сделавший запрос хост получил предложение немедленно. В этом случае также происходит «половинчатый» перехват.
Отметим, что если хост принимает предложения только от определенных серверов, то злоумышленник может легко выдать себя за один из таких серверов, установив соответствующие обратные адреса в датаграммах с DHCP-сообщениями.
Атака на протоколы маршрутизации
Если злоумышленник хочет перехватить трафик между узлами сети Р и узлами сети Q, и при этом не находится ни в одной из сетей P или Q, но расположен на пути между ними, он может попытаться ввести в заблуждение маршрутизаторы. Маршрутизаторы не реагируют на сообщения ICMP Redirect, поэтому для успешной атаки необходимо, чтобы они использовали какой-либо протокол маршрутизации. В этом случае злоумышленник может сформировать подложные сообщения протокола маршрутизации с целью переключения требуемых маршрутов на себя. Например (рис. 9.3) узел Х, приняв широковещательные RIP-сообщения, рассылаемые узлами А (вектор P=3) и В (вектор Q=2), отправляет сообщение с вектором Q=1 на индивидуальный адрес маршрутизатора А, а сообщение P=2 — на индивидуальный адрес В.

Рис. 9.3. Навязывание ложного RIP-маршрутизатора X для перехвата трафика между сетями P и Q
Возможна ситуация, когда значение вектора, объявляемого, например, маршрутизатором В: Q=1. В этом случае Х не может немедленно предложить лучшего маршрута, но он может применить следующий прием. Сначала, выбрав паузу в рассылке RIP-сообщений маршрутизатором В, Х от имени В отправляет в А вектор Q=16, что заставит маршрутизатор А удалить из своей таблицы маршрут в сеть Q, так как до этого А отправлял датаграммы в Q через В. Сразу же вслед за этим Х отправляет вектор Q=1 от своего имени, и А устанавливает маршрут в сеть Q через Х. Последующие векторы Q=1 от В будут проигнорированы, поскольку они не предлагают лучшего маршрута.
IBGP-соседи для пересылки датаграмм друг другу могут пользоваться результатами работы внутреннего протокола маршрутизации, злоумышленник может предварительно атаковать протокол внутренней маршрутизации, замкнув на себя трафик между сетями, в которых находятся BGP-маршрутизаторы (например, это сети P и Q на рис. 9.3) и модифицируя данные BGP-соединения в своих целях.
Конечно, атака на протокол BGP выглядит трудноосуществимой, но, тем не менее, такие атаки возможны. Аутентификация TCP-сегментов с помощью алгоритма MD5 поможет избежать неприятностей.
NBMA- и point-to-multipoint сети
В случае, когда несколько OSPF-маршрутизаторов подключены к сети множественного доступа, не поддерживающей широковещательную передачу (NBMA-сеть), они следуют той же процедуре, что и в случае широковещательной сети, поскольку каждый маршрутизатор также может непосредственно связаться с каждым, и, следовательно, существует та же проблема "N2" по числу отношений смежности и числу записей в базе данных состояния связей. В случае NBMA-сетей проблема даже усугубляется тем, что поддержка постоянных соединений между любыми двумя маршрутизаторами для обмена маршрутной информацией (отношения смежности) может потребовать значительных технических и финансовых затрат.
Отличие NBMA от широковещательных сетей состоит в том, что адреса всех соседей должны быть предварительно сконфигурированы на каждом маршрутизаторе, потому что возможности передавать мультикастинговые сообщения нет.
Если маршрутизатор, подключенный к нешироковещательной сети, может непосредственно связаться с несколькими, но не со всеми маршрутизаторами этой сети (неполный множественный доступ), такое соединение конфигурируется как point-to-multipoint и не рассматривается протоколом OSPF как сеть множественного доступа со всеми вышеописанными последствиями. Маршрутизатор, подключенный к соединению типа point-to-multipoint, устанавливает двухточечные связи с каждым своим соседом по соединению (см. также ).
Могут быть также причины, по которым администратор пожелает сконфигурировать сеть с полным множественным доступом как point-to-multipoint.
Несанкционированное подключение к сети
Для незаконного подключения к сети злоумышленник, разумеется, должен иметь физическую возможность такого подключения. В крупных корпоративных и особенно университетских сетях такая возможность часто имеется. Следующим шагом для злоумышленника является конфигурирование параметров стека TCP/IP его компьютера.
Прослушивание сети (сегмента сети) даст злоумышленнику много полезной информации. В частности, он может определить, какие IP-адреса имеют узлы сети, и с помощью ICMP Echo-запросов (программа ping) определить, какие адреса не используются (или компьютеры выключены). После этого злоумышленник может присвоить себе неиспользуемый адрес.
Найти IP-адрес маршрутизатора по умолчанию можно, подслушав кадры с датаграммами, направленными на IP-адреса, не принадлежащие сети. Эти кадры направлены на MAC-адрес маршрутизатора. Очевидно, что узлы сети время от времени генерируют ARP-запросы о MAC-адресе маршрутизатора; ответы на эти запросы, посылаемые маршрутизатором, содержат как его MAC-адрес, так и IP-адрес. Зная MAC-адрес маршрутизатора и подслушав такие ответы, злоумышленник определит искомый IP-адрес.
Для обнаружения маршрутизатора злоумышленник может использовать также сообщения ICMP Router Advertisement/Solicitation.
Для определения маски сети злоумышленник может послать на адрес маршрутизатора сообщение ICMP Address Mask Request. В ответ маршрутизатор должен выслать маску сети в сообщении Address Mask Reply.
Если маршрутизатор не поддерживает сообщения Address Mask Request/Reply, злоумышленник может применить следующий простой метод. Путем арифметических вычислений он определяет минимальную сеть, включающую его собственный адрес и найденный адрес маршрутизатора, и назначает себе маску этой сети. Например, пусть адрес, присвоенный злоумышленником, X=10.0.0.57, а адрес маршрутизатора G=10.0.0.1, то есть, расписывая последний октет в двоичном виде:
X=10.0.0.00111001 G=10.0.0.00000001
Максимальная общая часть обоих адресов (то есть, искомая минимальная сеть, включающая оба адреса): N=10.0.0.00XXXXXX
Значит, N=10.0.0.0/26, а маска — 255.255.255.192.
Все датаграммы, направленные за пределы этой минимальной сети, будут переданы маршрутизатору. Если маска определена неправильно, и на самом деле злоумышленник находится в сети, например, 10.0.0.0/16 и посылает датаграмму узлу 10.0.1.1, маршрутизатор примет эту датаграмму от злоумышленника и просто передаст ее узлу назначения в этой же самой сети.
Конечно, существует вероятность, что злоумышленник неправильно определит IP-адрес для присвоения и окажется за пределами сети. Кроме того, возможная конфигурация нескольких IP-сетей в одном сегменте Ethernet усложнит задачу злоумышленника. Однако после периода проб и ошибок злоумышленник имеет все шансы определить необходимые параметры для конфигурирования своего хоста.
Отметим, что если в сети имеется сервер DHCP, который предоставляет IP-адреса всем желающим, то он полностью сконфигурирует узел злоумышленника без всяких усилий со стороны последнего. Это событие будет зарегистрировано в журнале сервера.
Для предотвращения несанкционированного подключения к сети администратор должен использовать статическую ARP-таблицу на маршрутизаторе (и ключевых хостах-серверах) и программу arpwatch. Статическая ARP-таблица не позволит злоумышленнику получить ни одну датаграмму от узла, который ее использует, поскольку MAC-адрес злоумышленника, естественно, не значится в таблице. Программа arpwatch уведомит администратора о появлении узла с неизвестным MAC-адресом.
Однако, если злоумышленник, определив IP- и MAC-адреса какого-либо компьютера в своей сети, дождется его выключения (или проведет против него атаку «отказ в обслуживании», приводящую к неспособности атакуемого хоста работать в сети), а потом присвоит себе его MAC- и IP-адреса, то обнаружить такого злоумышленника будет невозможно и все его действия будут приписаны атакованному хосту.
Несанкционированный обмен данными
С целью обеспечения безопасности внутренней (корпоративной) сети на шлюзе могут использоваться фильтры, препятствующие прохождению определенных типов датаграмм. Датаграммы могут фильтроваться по IP-адресам отправителя или получателя, по протоколу (поле Protocol IP-датаграммы), по номеру порта TCP или UDP, по другим параметрам, а также по комбинации этих параметров.
В этом пункте мы рассмотрим два приема, которые может использовать злоумышленник для проникновения через некоторые фильтры.
NEXT_HOP
NEXT_HOP (тип 3) – обязательный атрибут, указывающий адрес следующего BGP-маршрутизатора на пути в заявленную сеть (см. обсуждение в п. ); может совпадать или не совпадать с адресом BGP-узла, анонсирующего маршрут. Указанный в NEXT_HOP маршрутизатор должен быть достижим для получателя данного маршрута. При передаче маршрута по IBGP NEXT_HOP не меняется.
Обеспечение достоверности
Модуль TCP обеспечивает защиту от повреждения, потери, дублирования и нарушения очередности получения данных.
Для выполнения этих задач все октеты в потоке данных сквозным образом пронумерованы в возрастающем порядке. Заголовок каждого сегмента содержит число октетов данных в сегменте и порядковый номер первого октета той части потока данных, которая пересылается в данном сегменте. Например, если в сегменте пересылаются октеты с номерами от 2001 до 3000, то номер первого октета в данном сегменте равен 2001, а число октетов равно 1000.
Номер первого байта в потоке определяется на этапе установления соединения и обозначается ISN+1 (подробнее см. ). Например, ISN+1=1.
Также для каждого сегмента вычисляется контрольная сумма, позволяющая обнаружить повреждение данных.
При удачном приеме октета данных принимающий модуль посылает отправителю подтверждение о приеме- номер удачно принятого октета. Если в течение некоторого времени отправитель не получит подтверждения, считается, что октет не дошел или был поврежден, и он посылается снова. Этот механизм контроля надежности называется PAR (Positive Acknowledgment with Retransmission). В действительности подтверждение посылается не для одного октета, а для некоторого числа последовательных октетов (подробнее см. ).
Нумерация октетов используется также для упорядочения данных в порядке очередности и обнаружения дубликатов (которые могут быть посланы из-за большой задержки при передаче подтверждения или потери подтверждения).
Обсуждение
Применение того или иного протокола групповой маршрутизации существенно зависит от того, плотно или разреженно расположены получатели группового трафика. Для плотного расположения годятся протоколы DVMRP, MOSPF и PIM DM; для разреженного подходят PIM SM и CBT.
Все перечисленные протоколы находятся в экспериментальной стадии. Протокол DVMRP, как указывалось выше, используется в ядре MBONE. Однако наиболее перспективными выглядят протоколы PIM DM и PIM SM; они также поддерживаются маршрутизаторами Cisco.
(С)
Протокол OSPF гораздо сложнее протокола RIP, но следует помнить, что маршрутизация является критически важной задачей для сетей TCP/IP. Благодаря использованию более совершенного алгоритма протокол OSPF работает в сетях любой сложности и не имеет ограничений и побочных эффектов протокола RIP. При этом время, используемое на построение таблицы маршрутов, и нагрузка на сеть для передачи служебной информации в среднем меньше по сравнению с тем, что потребовал бы RIP для такой же системы. (Например, при стабильной конфигурации системы маршрутная информация рассылается модулем OSPF каждые 30 минут, а модулем RIP - каждые 30 с.)
Кроме того, OSPF предлагает дополнительные возможности для оптимизации процесса построения маршрутов в системе. Во-первых, это специальная трактовка сетей множественного доступа, во-вторых, возможность разбить систему на области различного типа (обычные, тупиковые, не совсем тупиковые). Также разработаны и разрабатываются другие расширения протокола, не описанные выше.
Основная документация по протоколу OSPF содержится в следующих источниках:
RFC-2328 — стандарт протокола OSPF, версия 2 (RFC-1247, 1583, 2178 - предыдущие версии OSPF-2, RFC-1131 - описание OSPF-1);
RFC-1587 — работа с NSSA;
RFC-1584 — расширения OSPF для мультикастинговой маршрутизации (см. также RFC-1585);
RFC-1586 — рекомендации для работы OSPF поверх Frame Relay.
RFC-1793 — расширения OSPF для работы с соединениями, устанавливаемыми по требованию (demand circuits);
RFC-1850 — дополнения к MIB (Management Infomation Base) для объектов протокола OSPF.
Конфигурирование OSPF-маршрутизатора потребует, как минимум, следующих шагов:
указать связи, которые будут включены в OSPF-систему; если это широковещательные сети, то указать адреса этих сетей; в случае нешироковещательных сетей и двухточечных связей указать адреса возможных соседей;
если требуется, указать тип cоединения (двухточечный, point-to-multipoint);
если есть разбиение на области, для каждой связи указать номер области и ее тип;
если требуется, сконфигурировать виртуальные связи;
сконфигурировать внешние маршруты или организовать их получение от протоколов внешней маршрутизации, или установить маршрут по умолчанию - на пограничных маршрутизаторах системы.
Могут возникнуть также и другие задачи, связанные со спецификой системы.
(С)
Протокол RIP очень прост и до сих пор продолжает использоваться в системах с простой топологией, но обладает недостатками, которые не позволяют применять его в обширных и сложных системах.
Во-первых, малое значение бесконечности (из-за эффекта "счет до бесконечности") ограничивает размер RIP-системы четырнадцатью промежуточными маршрутизаторами в любом направлении. Кроме того, по той же причине весьма затруднительно использование сложных метрик, учитывающих не просто количество промежуточных маршрутизаторов, но и скорость и качество канала связи (чем хуже (медленнее) канал, тем больше метрика).
Во-вторых, само явление счета до бесконечности вызывает сбои в маршрутизации.
В-третьих, широковещательная рассылка векторов расстояний каждые 30 секунд ухудшает пропускную способность сети.
В-четвертых, время схождения алгоритма при создании маршрутных таблиц достаточно велико (по крайней мере, по сравнению с протоколами состояния связей).
В-пятых, несмотря на то, что каждый маршрутизатор начинает периодическую рассылку своих векторов, вообще говоря, в случайный момент времени (например, после включения), через некоторое время в системе наблюдается эффект синхронизации маршрутизаторов, сходный с эффектом синхронизации аплодисментов. Все маршрутизаторы рассылают свои вектора в один и тот же момент времени, что приводит к большим пикам трафика и отказам в маршрутизации дейтаграмм во время обработки большого количества одновременно полученных векторов.
Протокол RIP описан в RFC-1058 (версия 1) и RFC-1388 (версия 2).
(С)
Обсуждение фрагментации
Максимальное количество фрагментов равно 213=8192 при минимальном (8 октетов) размере каждого фрагмента. При большем размере фрагмента максимальное количество фрагментов соответственно уменьшается.
При фрагментации некоторые опции копируются в заголовок фрагмента, некоторые — нет. Все остальные поля заголовка дейтаграммы в заголовке фрагмента присутствуют. Следующие поля заголовка могут менять свое значение по сравнению с первоначальной дейтаграммой: поле опций, флаг “MF”, “Fragment Offset”, “Total Length”, “IHL”, контрольная сумма. Остальные поля копируются во фрагменты без изменений.
Каждый модуль IP должен быть способен передать дейтаграмму из 68 октетов без фрагментации (максимальный размер заголовка 60 октетов [IHL=15] + минимальный фрагмент 8 октетов).
Сборка фрагментов осуществляется только в узле назначения дейтаграммы, поскольку разные фрагменты могут следовать в пункт назначения по разным маршрутам.
Если фрагменты задерживаются или утрачены при передаче, то у остальных фрагментов, уже полученных в точке сборки, TTL уменьшается на единицу в секунду до тех пор, пока не прибудут недостающие фрагменты. Если TTL становится равным нулю, то все фрагменты уничтожаются и ресурсы, задействованные на сборку дейтаграммы, высвобождаются.
Максимальное количество идентификаторов дейтаграмм - 65536. Если использованы все идентификаторы, нужно ждать до истечения TTL, чтобы можно было вновь использовать тот же самый ID, поскольку за TTL секунд “старая” дейтаграмма будет либо доставлена и собрана, либо уничтожена.
Передача дейтаграмм с фрагментацией имеет определенные недостатки. Например, как следует из предыдущего абзаца, максимальная скорость такой передачи равна 65536/TTL дейтаграмм в секунду. Если учесть, что рекомендованная величина TTL равна 120, получаем максимальную скорость в 546 дейтаграмм в секунду. В среде FDDI MTU равен примерно 4100 октетам, откуда получаем максимальную скорость передачи данных в среде FDDI не более 18 Мбит/с, что существенно ниже возможностей этой среды.
Другим недостатком фрагментации является низкая эффективность: при потере одного фрагмента заново передается вся дейтаграмма; при одновременном ожидании отставших фрагментов нескольких дейтаграмм создается ощутимый дефицит ресурсов и замедляется работа узла сети.
Способом обойти процесс фрагментации является применение алгоритма “Path MTU Discovery” (“Выявление MTU на пути следования”), этот алгоритм поддерживается протоколом TCP. Задачей алгоритма является обнаружение минимального MTU на всем пути от отправителя к месту назначения. Для этого посылаются дейтаграммы с установленным битом DF (“фрагментация запрещена”). Если они не доходят до места назначения, размер дейтаграммы уменьшается, и так происходит до тех пор, пока передача не будет успешной. После этого при передаче полезных данных создаются дейтаграммы с размером, соответствующим обнаруженному минимальному MTU.
Опции IP
Опции определяют дополнительные услуги протокола IP по обработке дейтаграмм. Опция состоит, как минимум, из октета “Тип опции”, за которым могут следовать октет “Длина опции” и октеты с данными для опции.
Структура октета “Тип опции”:

Значения бита С:
1 - опция копируется во все фрагменты;
0 - опция копируется только в первый фрагмент.
Определены два класса опций: 0- “Управление” и 2 - “Измерение и отладка”. Внутри класса опция идентифицируется номером. Ниже приведены опции, описанные в стандарте протокола IP; знак “-” в столбце “Октет длины” означает, что опция состоит только из октета “Тип опции”, число рядом с плюсом означает, что опция имеет фиксированную длину (длина указывается в октетах).
Таблица 2.4.2
Опции IP
Класс
При обнаружении в списке опции “Конец списка опций” разбор опций прекращается, даже если длина заголовка (IHL) еще не исчерпана. Опция “Нет операции” обычно используется для выравнивания между опциями по границе 32 бит.
Большинство опций в настоящее время не используются. Опции “Stream ID” и “Безопасность” применялись в ограниченном круге экспериментов, функции опций “Запись маршрута” и “Internet Timestamp” выполняет программа traceroute. Определенный интерес представляют только опции “Loose/Strict Source Routing”, они рассмотрены в следующем пункте.
Применение опций в дейтаграммах замедляет их обработку. Поскольку большинство дейтаграмм не содержат опций, то есть имеют фиксированную длину заголовка, их обработка максимально оптимизирована именно для этого случая. Появление опции прерывает этот скоростной процесс и вызывает стандартный универсальный модуль IP, способный обработать любые стандартные опции, но за счет существенной потери в быстродействии.
Опции “Loose/Strict Source Routing”
Опции “Loose/Strict Source Routing” (класс 0, номера 3 и 9 соответственно) предназначены для указания дейтаграмме предопределенного отправителем маршрута следования.
Обе опции выглядят одинаково:
Тип опции
1 октет
Поле “Данные” содержит список IP-адресов требуемого маршрута в порядке следования. Поле “Указатель” служит для определения очередного пункта маршрута, оно содержит номер первого октета IP-адреса этого пункта в поле “Данные”. Номера считаются от начала опции с единицы, начальное значение указателя - 4.
Опции работают следующим образом.
Предположим, дейтаграмма, посланная из A в B, должна проследовать через маршрутизаторы G1 и G2. На выходе из А поле “Destination Address” заголовка дейтаграммы содержит адрес G1, а поле данных опции - адреса G2 и В (указатель=4). По прибытии дейтаграммы в G1 из поля данных опции, начиная с октета, указанного указателем (октет 4), извлекается адрес следующего пункта (G2) и помещается в поле “Destination Address”, при этом значение указателя увеличивается на 4, а на место адреса G2 в поле данных опции помещается адрес того интерфейса маршрутизатора G1, через который дейтаграмма будет отправлена по новому месту назначения (то есть в G2). По прибытии дейтаграммы в G2 процедура повторяется и дейтаграмма отсылается в В. При обработке дейтаграммы в В обнаруживается, что значение указателя (12) превышает длину опции, это значит, что конечный пункт маршрута достигнут.
Отличия опций “Loose Source Routing” и “Strict Source Routing” друг от друга заключаются в следующем:
“Loose”: очередной пункт требуемого маршрута может быть достигнут за любое количество шагов (хопов);
“Strict”: очередной пункт требуемого маршрута должен быть достигнут за 1 шаг, то есть непосредственно.
Рассмотренные опции копируются во все фрагменты. В дейтаграмме может быть только одна такая опция.
Опции “Loose/Strict Source Routing” могут быть использованы в целях несанкционированного проникновения через контролирующий (фильтрующий) узел (в поле “Destination Address” устанавливается разрешенный адрес, дейтаграмма пропускается контролирующим узлом, далее из поля данных опции подставляется запрещенный адрес и дейтаграмма перенаправляется по этому адресу уже за пределами досягаемости контролирующего узла), поэтому в целях безопасности рекомендуется вообще запретить пропуск контролирующим узлом дейтаграмм с рассматриваемыми опциями.
Быстродействующей альтернативой использованию опции “Loose Source Routing” является IP-IP инкапсуляция: вложение IP-дейтаграммы внутрь IP-дейтаграммы (поле “Protocol” внешней дейтаграммы имеет значение 4, см. ). Например, требуется отправить некоторый TCP-сегмент из А в В через С. Из А в С отправляется дейтаграмма вида:

При обработке дейтаграммы в С обнаруживается, что данные дейтаграммы должны быть переданы для обработки протоколу IP и представляют собой, разумеется, также IP-дейтаграмму. Эта внутренняя дейтаграмма извлекается и отправляется в В.
При этом дополнительное время на обработку дейтаграммы потребовалось только в узле С (обработка двух заголовков вместо одного), но во всех остальных узлах маршрута никакой дополнительной обработки не потребовалось, в отличие от случая использования опций.
Применение IP-IP инкапсуляции также может вызвать описанные выше проблемы с безопасностью.
ORIGIN
ORIGIN (тип 1) – обязательный атрибут, указывающий источник информации о маршруте:
0 – IGP (информация о достижимости сети получена от протокола внутренней маршрутизации или введена администратором),
1 – EGP (информация о достижимости сети импортирована из устаревшего протокола EGP),
2 – INCOMPLETE (информация получена другим образом, например, RIP->OSPF->BGP или BGP->OSPF->BGP).
Атрибут ORIGIN вставляется маршрутизатором, который генерирует информацию о маршруте, и при последующем анонсировании маршрута другими маршрутизаторами не изменяется. Атрибут фактически определяет надежность источника информации о маршруте (наиболее надежный ORIGIN=0).
Основные сведения о мультикастинге
Мультикастингом (multicasting) называется рассылка дейтаграмм группе получателей. Для идентификации групп используются специальные адреса получателя; эти адреса назначаются из класса D в диапазоне 224.0.0.0– 239.255.255.255. Дейтаграмма, направленная на групповой адрес, должна быть доставлена всем участникам группы. В дальнейшем в этой главе такие дейтаграммы мы будем называть групповыми.
Некоторые из групповых адресов зарезервированы для специальных групп (см. RFC-1700 или ). Например:
224.0.0.1 – все узлы в данной сети; 224.0.0.2 – все маршрутизаторы в данной сети; 224.0.0.5 – все OSPF-маршрутизаторы; 224.0.0.6 – выделенные OSPF-маршрутизаторы; 224.0.0.9 – маршрутизаторы RIP-2; 224.0.0.10 – IGRP-маршрутизаторы; 224.0.1.1 – получатели информации по протоколу точного времени NTP;
и так далее.
Все адреса в диапазоне 224.0.0.0 – 238.255.255.255 предназначены для использования в масштабе Интернет. Адреса вида 239.Х.Х.Х зарезервированы для внутреннего использования в частных сетях.
Приложения групповой рассылки дейтаграмм достаточно очевидны и перспективны: это рассылка новостей, трансляция радио- или видеопрограмм, дистанционное обучение, и т.п. Мультикастинг активно используется также и для передачи служебного трафика (маршрутной информации, сообщений службы точного времени и др.).
Групповая рассылка, по сравнению с индивидуальной, уменьшает нагрузку на сеть. Предположим, дейтаграмму следует отправить 500 получателям. Используя индивидуальную рассылку, отправитель должен сгенерировать 500 дейтаграмм, каждая из которых будет отправлена одному узлу. При мультикастинге отправитель создает одну дейтаграмму с групповым адресом назначения; по мере продвижения через сеть дейтаграмма будет дублироваться только на "развилках" маршрутов от отправителя к получателям. В лучшем случае – если таких развилок не будет, то есть, например, все получатели находятся в одной сети Ethernet, – экономия трафика будет 500-кратной. При этом сохраняются также вычислительные ресурсы промежуточных узлов.
Получателей дейтаграмм с определенным групповым адресом мы будем называть членами данной группы. Отметим, что отправитель групповой дейтаграммы не обязан знать индивидуальные IP-адреса получателей и не обязан быть членом группы.
Недостатком групповой рассылки является очевидная невозможность использования на транспортном уровне протокола TCP. Использование же протокола UDP влечет за собой все его недостатки: ненадежность доставки, отсутствие средств реагирования на заторы в сети и т.д. Кроме того, в отдельных случаях при изменении маршрутов рассылки групповые дейтаграммы могут не только теряться, но и дублироваться, и это должно учитываться приложениями.
Для организации IP-сети с поддержкой мультикастинга необходимо следующее (RFC-1112):
поддержка мультикастинга в стеке TCP/IP расположенных в сети хостов;
поддержка групповой или широковещательной рассылки на уровне доступа к сети.
Мультикастинг поддерживается в реализациях TCP/IP всех современных операционных систем Что касается второго требования, то, например, в Ethernet существует специальный диапазон адресов для групповой рассылки IP-дейтаграмм: 01:00:5e:X:Y:Z, где ХYZ – младшие 23 бита IP-адреса. То есть, групповому IP-адресу 224.255.0.1 на уровне Ethernet будет соответствовать MAC-адрес 01:00:5e:7f:00:01. Необходимо отметить, что это соответствие не является однозначным: в тот же MAC-адрес будут преобразованы IP-адреса 225.255.0.1, ..., 239.255.0.1, 225.127.0.1, ..., 239.127.0.1.
Построение системы сетей с поддержкой мультикастинга является гораздо более сложной задачей, чем организация групповой рассылки в пределах одной IP-сети. Для продвижения групповых дейтаграмм от отправителя к получателям через систему сетей необходимо осуществлять маршрутизацию дейтаграмм. Однако по групповой дейтаграмме нельзя определить индивидуальные IP-адреса ее получателей, следовательно, использование обычной IP-маршрутизации и даже ее принципов не имеет смысла. Поэтому для маршрутизации групповых дейтаграмм были разработаны специальные методы и протоколы, которые будут рассмотрены ниже в этой главе.
Основным предположением, которое при этом делается, является то, что маршрутизатор знает, члены каких групп находятся в непосредственно подсоединенных к нему сетях. Таким образом, прежде чем перейти к вопросам маршрутизации групповых дейтаграмм, требуется разработать механизм регистрации членов групп на маршрутизаторе, к которому подключена их сеть. Этот механизм (протокол IGMP) рассмотрен в п. .
В настоящее время для использования групповой рассылки в масштабе глобальных сетей создается экспериментальная сеть MBONE. Точнее, это "надсеть" (overlay network), построенная поверх существующих сегментов Интернет. MBONE состоит из областей, маршрутизаторы которых используют различные протоколы маршрутизации, и ядра, в котором используется протокол DVMRP (см. п. ). Если между областями MBONE находятся маршрутизаторы, не поддерживающие мультикастинг, то для соединения таких областей применяется туннелирование: групповые дейтаграммы инкапсулируются в дейтаграммы индивидуальной адресации, передаваемые между пограничными маршрутизаторами рассматриваемых областей.
OSPF-заголовок
Протокол OSPF в стеке протоколов TCP/IP находится непосредственно над протоколом IP, код OSPF равен 89. То есть если значение поля "Protocol" IP-дейтаграммы равно 89, то данные дейтаграммы являются сообщением OSPF и передаются OSPF-модулю для обработки. Соответственно размер OSPF-сообщения ограничен максимальным размером дейтаграммы.
Все сообщения OSPF имеют общий заголовок (следующий в дейтаграмме непосредственно за IP-заголовком):

Значения полей:
Version (1 октет) - версия протокола (=2);
Type (1 октет) - тип сообщения:
1 - Hello;
2 - описание базы данных (Database Description);
3 - запрос состояния связей (Link State Request);
4 - обновление состояния связей (Link State Update);
5 - подтверждение приема сообщения о состоянии связей (Link State Acknowledgment).
Packet length (2 октета) - длина сообщения в октетах, включая заголовок.
Router ID (4 октета) - идентификатор маршрутизатора, отправившего сообщение. Router ID равен адресу одного из IP-интерфейсов маршрутизатора. У маршрутизаторов Cisco это наибольший из адресов локальных интерфейсов, а если таковых нет, то наибольший из адресов внешних интерфейсов.
Area ID (4 октета) - номер области, к которой относится данное сообщение; номер 0 зарезервирован для магистрали. Часто номер области полагают равным адресу IP-сети (одной из IP-сетей) этой области.
Checksum (2 октета) - контрольная сумма, охватывает все OSPF-сообщение, включая заголовок, но исключая поле "Authentication"; вычисляется по тому же алгоритму, что и в IP-заголовке.
Authentication Type (2 октета) - тип аутентификации сообщения. Стандарт определяет несколько возможных типов, самые простые из них: 0 - нет аутентификации, 1 - аутентификация с помощью пароля.
Authentication (8 октетов) - аутентификационные данные; например, восьмисимвольный пароль.
Далее при рассмотрении формата сообщений вышеописанный заголовок будет изображаться в виде поля "OSPF-заголовок", помещенного в начало сообщения.
Остовые деревья (Spanning Trees)
В системе сетей выбирается корневой маршрутизатор, после этого из графа системы выделяется подграф-дерево, соединяющий корневой маршрутизатор со всеми остальными маршрутизаторами системы ("остовое дерево", рис. 8.3.1). Эта процедура производится на этапе инициализации системы – в процессе работы дерево не изменяется.
После построения остового дерева каждый маршрутизатор должен хранить для каждого из своих интерфейсов только флаг "этот интерфейс принадлежит/не принадлежит дереву". Групповая дейтаграмма от любого узла распространяется следующим образом: полученная маршрутизатором дейтаграмма ретранслируется через все интерфейсы, принадлежащие остовому дереву, кроме того интерфейса, с которого она была получена.

Рис. 8.3.1. Рассылка групповой дейтаграммы по остовому дереву
S – источник, A-F – маршрутизаторы;
ветви дерева обозначены сплошными линиями; метрики всех сетей, кроме явно указанных, равны 1
Метод остовых деревьев несколько лучше веерной рассылки – в том смысле, что теперь дейтаграммы распространяются по строго определенным маршрутам и в каждую сеть попадает только один экземпляр дейтаграммы. Также существенно уменьшена нагрузка на маршрутизаторы, которым больше не требуется хранить "исторические" таблицы дейтаграмм.
Однако групповые дейтаграммы по-прежнему рассылаются во все сети независимо от наличия в них получателей, кроме того:
требуется реализация механизма (протокола) выбора корневого узла и построения дерева;
весь групповой трафик ложится на одни и те же связи (сети), составляющие, возможно, небольшое подмножество всей системы сетей;
для некоторых пар отправитель-получатель путь по установленному дереву будет неоптимальным (например для источника S и получателей, подсоединенных к маршрутизатору Е на рис. 8.3.1).
Отказ в обслуживании
Атаки типа «отказ в обслуживании» (DoS, denial of service), по-видимому, являются наиболее распространенными [] и простыми в исполнении. Целью атаки является приведение атакуемого узла или сети в такое состояние, когда передача данных другому узлу (или передача данных вообще) становится невозможна или крайне затруднена. Вследствие этого пользователи сетевых приложений, работающих на атакуемом узле, не могут быть обслужены — отсюда название этого типа атак. Атаки DoS используются как в комплексе с другими (имперсонация, п. ), так и сами по себе.
DoS-атаки можно условно поделить на три группы:
атаки большим числом формально корректных, но, возможно, сфальсифицированных пакетов, направленные на истощение ресурсов узла или сети; атаки специально сконструированными пакетами, вызывающие общий сбой системы из-за ошибок в программах; атаки сфальсифицированными пакетами, вызывающими изменения в конфигурации или состоянии системы, что приводит к невозможности передачи данных, сбросу соединения или резкому снижению его эффективности.
Перехват данных
Простейшей формой перехвата данных является прослушивание сети. В этом случае злоумышленник может получить массу полезной информации: имена пользователей и пароли (многие приложения передают их в открытом виде), адреса компьютеров в сети, в том числе адреса серверов и запущенные на них приложения, адрес маршрутизатора, собственно передаваемые данные, которые могут быть конфиденциальными (например, тексты электронных писем) и т. п. Прослушивание сети и меры по обнаружению узлов, находящихся в режиме прослушивания, обсуждались в п. .
Однако если сеть разбита на сегменты с помощью коммутаторов, то злоумышленник может перехватить только кадры, получаемые или отправляемые узлами сегмента, к которому он подключен. Простое прослушивание также не позволяет злоумышленнику модифицировать передаваемые между двумя другими узлами данные. Для решения этих задач злоумышленник должен перейти к активным действиям, чтобы внедрить себя в тракт передачи данных в качестве промежуточного узла. (Такие атаки в англоязычной литературе называют man-in-the-middle attack.)
PIM SM
Протокол PIM SM (Protocol Independent Multicast, Sparse mode, RFC-2362) применяется для маршрутизации дейтаграмм для малочисленных групп, члены которых находятся далеко друг от друга (в этом случае недостатки метода RPF с усечением становятся существенными).
Функционирование протокола можно кратко описать как метод CBT, переходящий в RPF. Для группы назначается точка рандеву (RP), адрес которой известен всем потенциальным членам группы. Маршрутизатор, в сети которого зарегистрировались члены группы, посылает в RP сообщение Join, которое обрабатывается промежуточными маршрутизаторами как в технологии CBT – таким образом формируется первоначальное дерево рассылки.
Отправитель дейтаграмм (точнее, маршрутизатор отправителя), посылает в RP сообщения Register, в которых инкапсулируются групповые дейтаграммы. RP извлекает дейтаграммы из этих сообщений и рассылает их по сформированному дереву рассылки. Если отправитель работает достаточно интенсивно, то RP посылает в его сторону сообщение Join – то есть, отправитель становится членом группы и может рассылать групповые дейтаграммы по дереву непосредственно, минуя стадию туннелирования в точку рандеву.
Распространение групповых дейтаграмм по дереву рассылки осуществляется аналогично методу CBT: дейтаграмма рассылается через все интерфейсы, принадлежащие дереву, кроме того, с которого она была получена.
Далее, получая дейтаграммы, адресованные группе, маршрутизатор может заметить, что интенсивность этого потока превышает некоторый установленный лимит. В этом случае маршрутизатор решает оптимизировать дерево рассылки. Он посылает сообщение Join к источнику следующей полученной им дейтаграммы, адресованной данной группе, а в точку рандеву посылается сообщение Prune. Таким образом, дерево, изначально созданное вокруг точки рандеву, оптимизируется для данного источника. (Только "конечные" маршрутизаторы дерева рассылки могут инициировать этот процесс.)
Следует отметить, что переход к дереву, оптимизированному для источника, приводит к необходимости хранить и обрабатывать на маршрутизаторах большее количество служебной информации, что не всегда приемлемо, поэтому существует возможность отключения такого перехода.
Предусмотрен также обратный переход к дереву с корнем в точке рандеву. Он производится, если оптимизация дерева оказалась неоправданной.
Поддержка множественных маршрутов
Если между двумя узлами сети существует несколько маршрутов с одинаковыми или близкими по значению метриками, протокол OSPF позволяет направлять части трафика по этим маршрутам в пропорции, соответствующей значениям метрик. Например, если существует два альтернативных маршрута с метриками 1 и 2, то две трети трафика будет направлено по первому из них, а оставшаяся треть- по второму.
Положительный эффект такого механизма заключается в уменьшении средней задержки прохождения дейтаграмм между отправителем и получателем, а также в уменьшении колебаний значения средней задержки.
Менее очевидное преимущество поддержки множественных маршрутов состоит в следующем. Если при использовании только одного из возможных маршрутов этот маршрут внезапно выходит из строя, весь трафик будет разом перемаршрутизирован на альтернативный маршрут, при этом во время процесса массового переключения больших объемов трафика с одного маршрута на другой весьма велика вероятность образования затора на новом маршруте. Если же до аварии использовалось разделение трафика по нескольким маршрутам, отказ одного из них вызовет перемаршрутизацию лишь части трафика, что существенно сгладит нежелательные эффекты.
Рассмотрим теперь следующий пример.
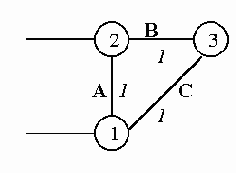
Рис. 5.1.5. Пример особой ситуации при поддержке множественных маршрутов
Узел ?
отправляет данные в ?
, используя поддержку множественных маршрутов, по маршрутам С (2/3 трафика) и АВ (1/3 трафика). Однако узел ?
тоже поддерживает механизм множественных путей, и когда к нему пребывают дейтаграммы, адресованные в ?
(в том числе, и отправленные из ?
), он применяет к ним ту же логику, то есть 2/3 из них отправляются в ?
по маршруту В, а одна треть - по маршруту АС. Следовательно, 1/9 дейтаграмм, отправленных узлом ?
в узел ?
, возвращаются опять в узел ?
, и тот 1/3 из них опять отправляет в ?
по маршруту С, а 2/3 - по маршруту АВ через узел ?
и так далее. В итоге сформировался "частичный цикл" при посылке дейтаграмм из ?
в ?
, который, помимо частичного зацикливания дейтаграмм, ведет к быстрой перегрузке линии А.
Избежать этого явления позволяет следующее правило.
Если узел Х отправляет данные в узел Y, он может пересылать их через узел Q только в том случае, если Q ближе к Y, чем Х.
В разобранном выше примере, следуя этому правилу, ?
не может посылать данные в ?
через ?
, поскольку ?
не ближе к ?
, чем ?
. Однако такая посылка возможна, если связи между узлами имеют метрики, например, как изображено на следующем рисунке.

Рис. 5.1.6. Пример корректной ситуации при поддержке множественных маршрутов
Для реализации построения дополнительных альтернативных маршрутов с учетом вышеприведенного правила в алгоритме SPF требуется внести изменения в шаг 3 и добавить шаг 3А. Ниже приводится новая версия алгоритма SPF, в которой изменение и дополнение показаны курсивом.
Алгоритм SPF с поддержкой множественных маршрутов
1. Инициализировать E={S}, R={все вершины графа, кроме S}. Поместить в О все односегментные (длиной в одно ребро) пути, начинающиеся из S, отсортировав их в порядке возрастания метрик.
2. Если О пуст или первый путь в О имеет бесконечную метрику, то отметить все вершины в R как недостижимые и закончить работу алгоритма.
3. Рассмотрим P - кратчайший путь в списке О. Удалить P из О. Пусть V - последний узел в P.
Если V принадлежит E, перейти на шаг 3А;
иначе P является кратчайшим путем из S в V; перенести V из R в E. Перейти на шаг 4.
3А. Рассмотрим W, узел, предшествующий V в пути Р. Если расстояние от S до W меньше расстояния от S до V, обозначить Р как приемлемый альтернативный путь к V. В любом случае перейти на шаг 2.
4. Построить набор новых путей, подлежащих рассмотрению, путем добавления к пути P всех односегментных путей, начинающихся из V. Метрика каждого нового пути равна сумме метрики P и метрики соответствующего односегментного отрезка, начинающегося из V. Добавить новые пути в упорядоченный список О, поместив их на места в соответствии со значениями метрик. Перейти на шаг 2.
Построение маршрутов
Рассмотрим работу алгоритма SPF и построение маршрутов на примере системы, изображенной на рис. 5.1.1. Для простоты будем рассматривать OSPF-систему, состоящую только из маршрутизаторов, соединенных линиями связи типа "точка-точка".

Рис. 5.1.1. Пример OSPF-системы
Обозначения на рисунке: ?
,?
,?
,?
- маршрутизаторы; A,B,C,D - линии связи (или просто связи), цифры означают метрику каждой связи.
Превентивное сканирование
Администратор сети должен знать и использовать методы и инструменты злоумышленника и проводить превентивное сканирование сети организации для обнаружения слабых мест в безопасности до того, как это сделает злоумышленник. Для этой цели имеется также специальное программное обеспечение — сканеры безопасности, network security scanners, типа .
Преждевременные подтверждения
Еще одна разновидность атаки строится на том, что получатель может заранее высылать подтверждения еще не принятых им, находящихся в пути сегментов, заставляя отправителя поверить, что данные уже доставлены, результатом чего будет увеличение cwnd и преждевременная отправка новых данных.
Отметим, что хотя получатель и может предсказать границы сегментов отправителя (при передаче большого объема данных отправитель, как правило, помещает данные в полноразмерные сегменты, имеющие одинаковый объем) и соответственно формировать преждевременные подтверждения, большая точность при этом не требуется. Подтверждение любого блока данных, как мы уже замечали выше, приводит к увеличению окна cwnd и отправке новых полноразмерных сегментов.
Более того, если получатель «перестарается» и подтвердит то, что еще не выслано, подтверждение будет просто проигнорировано отправителем и не приведет ни к каким неприятным последствиям.
В отличие от двух предыдущих атак атака преждевременными подтверждениями разрушает механизм обеспечения надежности передачи данных: если какой-либо из сегментов с данными, отправленный из А в В, потеряется в пути, повторной передачи этого сегмента не будет, поскольку он был уже заранее подтвержден получателем. Однако прикладные протоколы HTTP и FTP, с помощью которых и передается большинство данных в Интернете, предоставляют возможность запрашивать у сервера не весь файл, а его определенные части (большинство серверов поддерживают эту возможность). Поэтому, применив описанную атаку и получив основной объем данных с HTTP- или FTP-сервера на завышенной скорости, злоумышленник может впоследствии с помощью запросов на частичную передачу «залатать дыры», образовавшиеся из-за потерянных сегментов.
Описанные атаки особенно эффективны при передаче сравнительно небольших объемов данных (файлов), когда весь файл может быть передан взрывным образом за одно время обращения. Эксперименты [] показали, что скорость загрузки файла увеличивается в несколько раз. Работа конкурирующих TCP-соединений (имеющихся в том же коммуникационном канале) практически блокируется, поскольку из-за резко возросшей интенсивности трафика другие соединения диагностируют состояние затора и принимают соответствующие меры по уменьшению скорости передачи данных, фактически освобождая канал для злоумышленника.
Для реализации описанных атак требуется сравнительно небольшая (несколько десятков строк) модификация модуля TCP на компьютере В. Для защиты от расщепления подтверждений достаточно доработать реализацию модуля TCP: разрешить увеличивать cwnd только после получения подтверждения, охватывающего целый сегмент. Адекватной защиты от двух других атак не существует. Чтобы решить эту проблему, авторы работы [] предлагают внести в заголовок TCP дополнительное поле cumulative nonce, которое будет играть роль идентификатора сегмента; используя это поле, легитимные подтверждения должны ссылаться на сегмент (сегменты), получение которых вызвало отправку данного подтверждения. Это должно предотвратить отправку ложных дубликатов и подтверждений еще не полученных сегментов. За деталями мы отсылаем читателя к первоисточнику, однако маловероятно, чтобы дизайн протокола TCP был изменен.
В заключение упомянем о достаточно простом способе ускоренного получения файлов от отправителя по протоколам HTTP и FTP. Для этого получатель использует программу, способную получать файл по частям (сервер также должен поддерживать соответствующие расширения протоколов HTTP и FTP); пример такой программы для ОС Windows — Flashget. Для загрузки файла с сервера программа одновременно открывает несколько соединений, каждое из которых запрашивает свой фрагмент файла. Фрагменты впоследствии будут состыкованы на локальном диске получателя.
Предположим, что в коммуникационном канале одновременно передают данные 10 TCP-соединений. В результате работы алгоритмов реагирования на заторы они примерно поровну делят между собой полосу пропускания канала, и каждое получает 1/10 его часть. Но если программа загрузки файла открывает не одно, а, например, 5 соединений, то общее число соединений равно 14, из них получением частей одного файла занято 5 соединений, то есть, на получение файла отведено 5/14 = 36% канала, а не 10%, как было раньше.
физическая структура которой приведена на
Рассмотрим пример. Пусть имеется OSPF-система, физическая структура которой приведена на рис. 5.3.1 (значком с изображением компьютера обозначены хосты).

Рис. 5.3.1. Пример физической структуры OSPF-системы
Граф этой системы выглядит следующим образом (вершины в виде кружков обозначают маршрутизаторы, в виде прямоугольников- тупиковые сети, в виде треугольника - транзитную сеть; ребра графа ориентированные, числа рядом с ребрами - метрики).

Рис. 5.3.2. Граф системы, изображенной на рис. 5.3.1
Если выделенным маршрутизатором сети Т является узел ?
, то отношения смежности в системе установлены между следующими парами маршрутизаторов: (?
,?
), (?
,?
), (?
,?
), (?
,?
), (?
,?
). Эти пары обмениваются между собой сообщениями OSPF для синхронизации копий баз данных.
Маршрутизаторы ?
и ?
не являются смежными, однако они соседи, то есть обмениваются сообщениями "Hello", принимают участие в выборах выделенного маршрутизатора и, разумеется, могут отправлять дейтаграммы непосредственно друг другу. Например, дейтаграмма из ?
в ?
проследует по маршруту ?
a
?
a
?
, но информацию о том, что такой маршрут возможен, маршрутизатор ?
получил не от ?
(так как они не смежны), а от выделенного маршрутизатора ?
после того как тот, в свою очередь, получил ее от ?
.
Каждый маршрутизатор вставляет в базу данных и контролирует состояние связей, идущих от него к другим маршрутизаторам (двухточечные связи), тупиковым и транзитным сетям. Связи, идущие из транзитной сети (вершина Т), вставляются в базу данных выделенным маршрутизатром ?
. Связей, идущих из тупиковой сети, существовать не может.
Вершина "транзитная сеть Т" представляет также и хосты, находящиеся в IP-сети Т.
Пример маршрутизации
Рассмотрим процесс маршрутизации на примере.
Допустим (см. рис. 2.3.1), хосты А и В находятся в сети 1, сеть 1 соединяется с сетью 2 с помощью маршрутизатора G1. К сети 2 подключен маршрутизатор G2, соединяющий ее с сетью 3, в которой находится хост С.

Рис. 2.3.1. Пример маршрутизации
Таблица маршрутов хоста А выглядит, например, так:
Сеть 1 А Прочие сети G1
Это означает, что дейтаграммы, адресованные узлам сети 1, отправляет сам хост А (так как это его локальная сеть), а дейтаграммы, адресованные в любую другую сеть (это называется маршрут по умолчанию), хост А отправляет маршрутизатору G1, чтобы тот занялся их дальнейшей судьбой.
Предположим, хост А посылает дейтаграмму хосту В. В этом случае, поскольку адрес В принадлежит той же сети, что и А, из таблицы маршрутов хоста А определяется, что доставка осуществляется непосредственно самим хостом А.
Если хост А отправляет дейтаграмму хосту С, то он определяет по IP-адреcу C, что хост С не принадлежит к сети 1. Согласно таблице маршрутов А, все дейтаграммы с пунктами назначения, не принадлежащими сети 1, отправляются на маршрутизатор G1 (это называется маршрут по умолчанию). При этом хост А не знает, что маршрутизатор G1 будет делать с его дейтаграммой и каков будет ее дальнейший маршрут- это забота исключительно G1. G1 в свою очередь по своей таблице маршрутов определяет, что все дейтаграммы, адресованные в сеть 3, должны быть пересланы на маршрутизатор G2. Это может быть как явно указано в таблице, находящейся на G1, в виде
Сеть 3 G2,
так и указано в виде маршрута по умолчанию.
На этом функции G1 заканчиваются, дальнейший путь дейтаграммы ему неизвестен и его не интересует. Маршрутизатор G2, получив дейтаграмму, определяет, что она адресована в одну из сетей (№3), к которым он присоединен непосредственно, и доставляет дейтаграмму на хост С.
Пример подключения локальной сети организации к Интернет
Рассмотрим реальный пример подключения к Интернет локальной сети организации (рис. 2.3.2). IP-адрес локальной сети - 194.84.124.0/24 (сеть класса С). В эту сеть включен маршрутизатор G1. IP-интерфейс этого маршрутизатора, подключенный к локальной сети Ethernet, имеет адрес 194.84.124.1. Второй IP-интерфейс маршрутизатора подключен к выделенной линии (синхронный последовательный канал), ведущей к провайдеру Интернет. К другому концу этой линии подключен IP-интерфейс маршрутизатора G2, принадлежащего провайдеру. Эти два интерфейса образуют отдельную сеть 194.84.0.116/30. В этой сети на номер интерфейса отведено всего 2 бита — 4 варианта адресов, из которых один (00) обозначает саму сеть, один (11) — широковещательный; таким образом, в подобной сети может находиться всего 2 узла — это минимальная возможная сеть. Интерфейс маршрутизатора G1 в сети 194.84.0.116/30 имеет адрес 194.84.0.117, а маршрутизатора G2 — 194.84.0.118. Маршрутизатор G2 имеет еще некоторое количество интерфейсов, к части которых подключены выделенные линии от других клиентов, к части — локальные сети коммуникационного центра, другие маршрутизаторы и магистральные линии дальней связи.

Рис. 2.3.2. Подключение локальной сети к Интернет
Пример построения таблицы маршрутов
Рассмотрим этот процесс на примере следующей сети.

Рис. 4.1.1. Пример RIP-системы
Здесь ?
, ?
, ?
, ?
- маршрутизаторы, A, B, C, D, E - сети. Хосты в сетях не показаны за ненадобностью. Мы будем следить за формированием таблицы маршрутов в узле ?.
В начальный момент времени (например, после подачи питания на маршрутизаторы) таблица маршрутов в узле ?
выглядит следующим образом (т.к. узел ?
знает только о тех сетях, к которым подключен непосредственно):
A=1a
?
B=1a
?
Следовательно, узел ?
рассылает в сети А и В вектор расстояний (А=1,В=1).
Аналогично узел ?
рассылает в сети A, C, D вектор (A=1,C=1,D=1). Узел ?
получает этот вектор из сети А, увеличивает расстояния на 1 (A=2,C=2,D=2) и сравнивает с данными в своей таблице маршрутов. Новое расстояние до сети А оказывается больше, чем уже внесенное в таблицу (А=1), следовательно, новое значение игнорируется. Поскольку сети C и D вовсе не фигурируют в его таблице маршрутов, они туда вносятся. В узле ?
имеем:
A=1a
?
B=1a
?
C=2a
?
D=2a
?
Узел ?
в свою очередь рассылает вектор (D=1,E=1) в сети D и E. Узел ?
получает этот вектор из сети D, увеличивает расстояния на 1, после чего добавляет себе в таблицу данные о сети Е (Е=2a
?
). Ранее из узла ?
он получил информацию о сети В и добавил себе в таблицу строку В=2a
?
. Узел ?
рассылает в сети A, C, D свой обновленный вектор расстояний (A=1,B=2,C=1,D=1,E=2).
Узел ?
получает этот вектор от ?
из сети А, увеличивает расстояния на 1: (A=2,B=3,C=2,D=2,E=3) и замечает, что все указанные расстояния, кроме расстояния до сети Е, больше либо равны значениям, имеющимся в его таблице. Сеть Е в таблице узла ?
отсутствует, следовательно, она туда вносится, и в узле ?
мы получаем:
A=1a
?
B=1a
?
C=2a
?
D=2a
?
Е=3a
?
Далее маршрутизатор ?
, ранее не работавший по каким-либо причинам, рассылает в сети В, С, Е свой вектор (В=1,С=1,Е=1). Узел ?
получает этот вектор из сети В, увеличивает расстояния на 1 и обнаруживает, что расстояние Е=2 меньше имеющегося в таблице Е=3, следовательно запись о сети Е в таблице заменяется на Е=2a
?. Остальные элементы полученного от ?
вектора не вызывают обновления таблицы.
Итоговая таблица маршрутов маршрутизатора ?
:
A=1a
?
B=1a
?
C=2a
?
D=2a
?
Е=2a
?
На этом алгоритм сходится, то есть при неизменной топологии системы никакие векторы расстояний, получаемые маршрутизатором ?
, больше не внесут изменений в таблицу маршрутов. Аналогичным образом алгоритм составления таблицы маршрутов работает и сходится на других маршрутизаторах. Отметим, что несмотря на то, что таблицы маршрутов построены, векторы расстояний продолжают периодически широковещательно рассылаться каждым маршрутизатором. Это требуется для оперативного реагирования на внезапные изменения топологии системы (см. п. 4.1.2).
Очевидно, что вид построенной таблицы маршрутов может зависеть от порядка получения маршрутизатором векторов расстояний. Например, если бы узел ?
получил вектор от узла ?
раньше, чем от узла ?
, то дейтаграммы в сеть С посылались бы от ?
через ?.
Пример работы алгоритма SPF
Рассмотрим работу алгоритма на примере базы данных состояния связей рассматриваемой системы.

Рис. 5.1.2. OSPF-система и ее база данных состояния связей
Возьмем в качестве вершины S маршрутизатор ?.
Инициализация
S=?
, E={?
}, R={?
,?
,?
}, O={D,C} (из вершины ?
согласно базе данных выходят только связи D (к ?
) и С (к ?
), причем метрика D меньше).
Итерация 1
P=D. Поскольку D ведет от ?
к ?
, то V=?
. Так как V не находится в Е, то кратчайший путь ?
a
?
есть P. Добавляем этот факт в таблицу результатов, изымаем P из O, переносим V из R в Е.
Строим новые пути (шаг 4 алгоритма): согласно базе данных из вершины V=?
существует два односегментных пути: B и D. Добавив их к P=D, получим пути DD и DB с метрикой 2 каждый. Эти пути добавляются в упорядоченный список О.
E={?
,?
}, R={?
,?
}, O={DD,DB,C}.
Результаты: (?
: D)
Итерация 2
P=DD. Двигаясь по этому пути из ?
, мы попадем опять в ?
, то есть V=?
. Так как V находится в Е, то исключаем P из О и переходим к следующей итерации.
E={?
,?
}, R={?
,?
}, O={DB,C}.
Результаты: (?
: D)
Итерация 3
P=DB. Двигаясь по этому пути из ?
, мы попадем в ?
, то есть V=?
. Так как V не находится в Е, то кратчайший путь ?
a
?
есть P. Добавляем этот факт в таблицу результатов, изымаем P из O, переносим V из R в Е.
Строим новые пути: согласно базе данных из V=?
существует три односегментных пути: A,В и C. Добавив их к P=DB, получим пути DBA, DBB и DBC с метриками 4,3 и 5 соответственно. Эти пути добавляются в упорядоченный список О.
E={?
,?
,?
}, R={?
}, O={C, DBB, DBA, DBC}.
Результаты: (?
: D;?
:DB)
Итерация 4
P=С. V=?
. Так как V находится в Е, то исключаем P из О и переходим к следующей итерации.
E={?
,?
,?
}, R={?
}, O={DBB, DBA, DBC}.
Результаты: (?
: D;?
:DB)
Итерация 5
P=DBB. V=?
. Так как V находится в Е, то исключаем P из О и переходим к следующей итерации.
E={?
,?
,?
}, R={?
}, O={DBA, DBC}.
Результаты: (?
: D;?
:DB)
Итерация 6
P=DBA, следовательно V=?
. Так как V не находится в Е, то кратчайший путь ?
a
?
есть P. Добавляем этот факт в таблицу результатов, изымаем P из O, переносим V из R в Е.
Строим новые пути: согласно базе данных из V=?
существует один односегментный путь A. Добавив его к P=DBА, получим путь DBAА с метрикой 6. Этот путь добавляется в упорядоченный список О.
E={?
,?
,?
,?
}, R={}, O={DBC,DBAA}.
Результаты: (?
: D;?
:DB,?
:DBA)
Итерации 7 и 8
На этих итерациях из списка О будут удалены оставшиеся пути, так как они ведут к вершинам, уже находящимся в множестве Е, больше никаких изменений не произойдет.
Итерация 9
Так как список О пуст и множество R пусто, то кратчайшие пути из S до всех вершин графа построены, недостижимых вершин нет. Работа алгоритма закончена.
Результатом работы является таблица кратчайших путей от маршрутизатора ?
до всех остальных маршрутизаторов:
?
a
?
:DB
?
a
?
:DBA
?
a
?
:D
На основе этой информации в узле ?
строится таблица маршрутов, ведущих ко всем узлам OSPF-системы. Для этого из вышеприведенной таблицы нужно взять первую связь каждого пути. Маршрутизатор, к которому ведет эта связь, будет являться следующим маршрутизатором для данного маршрута. При этом алгоритм SPF гарантирует, что и следующий маршрутизатор построил кратчайшие пути, соответствующие путям маршрутизатора ?
, т.е. если кратчайший путь из ?
в ?
(DBA) лежит через узел ?
, в который ведет связь D, то кратчайший путь из ?
в ?
будет ВА.
Таким образом, таблица маршрутов в узле ?
будет выглядеть:
?
a
?
: через ?
, линия D
?
a
?
: через ?
, линия D
?
a
?
: через линию D
Пример разбиения на области
Рассмотрим автономную систему, изображенную на рис. 5.4.1. Кружками обозначены маршрутизаторы, буквами- IP-сети, к которым они подключены.

Рис. 5.4.1. Пример разбиения OSPF-системы на области
Система поделена на три области, из которых область номер 0 (area 0) является магистралью (backbone). Маршрутизаторы ?
и ?
являются пограничными маршрутизаторами автономной системы. Маршрутизаторы ?
, ?
, ?
, ?
- областные пограничные маршрутизаторы. Сети A, B, C, G, K, H принадлежат магистрали. Метрики связей с каждой сетью равны 1.
Рассмотрим содержимое базы данных состояния связей в области 1. В этой базе данных находятся:
1. Записи о связях маршрутизаторов ?
, ?
, ?
, ?
с сетями D, F, J, источниками которых являются эти маршрутизаторы; на основании этих записей рассчитываются маршруты внутри области 1 (см. также ).
2. Записи о достижимости сетей магистрали (A, B, C, G, K, H); вносятся маршрутизаторами ?
и ?
на основании вычислений по базе данных магистрали, копию которой каждый из них имеет, так как подключен к магистрали непосредственно. При этом каждый из них объявляет только кратчайшее расстояние от себя каждой сети магистрали для того, чтобы внутренние маршрутизаторы области могли строить маршруты до сетей магистрали в соответствии с этими значениями через тот или иной ABR.
Например, для сети А ABR ?
объявит маршрутизаторам области 1 метрику 2, а ?
- метрику 3. Маршрутизатор ?
не знает, каким маршрутом ?
или ?
будут отправлять дейтаграммы в сеть А, однако он знает, что от него до узла ?
кратчайший маршрут - D c метрикой 1, а до узла ?
- маршрут FJ с метрикой 2 (не маршрут DG, потому что G не принадлежит области 1). Следовательно, ?
делает вывод, что кратчайший путь в сеть А имеет метрику 3 и проходит через ?
, а как достичь маршрутизатора ?
, ему известно.
3. Записи о достижимости сетей области 2 (E, I, L); вносятся маршрутизаторами ?
и ?
на основании метрик расстояний до этих сетей, объявленных в магистраль ABR-маршрутизаторами ?
и ?
. При этом каждый из узлов ?
и ?
добавляет к этим метрикам длину кратчайшего пути по магистрали от себя до ?
и ?
, после чего для каждой сети области 2 выбирает наименьшее значение и объявляет его в область 1.
Например, ?
объявляет в магистраль, что сеть Е достижима через него с метрикой 1, а ?
- что та же сеть достижима через него с метрикой 3 (маршрут "НЕ" находится за пределами области 2). Маршрутизатор ?
получает эти сообщения и вычисляет по своей копии базы данных магистрали, что метрика кратчайшего пути от него до ?
равна 2, а до ?
- 1. Следовательно, расстояние до сети Е от узла ?
равно 3, если следовать через ?
, и 4, если следовать через ?
. На основании этого результата ?
объявляет в область 1, что сеть Е достижима через него с метрикой 3.
Для внутренних маршрутизаторов области 1 объявления областных пограничных маршрутизаторов о достижимости сетей магистрали и о достижимости сетей области 2 неотличимы по своему виду. И то и другое суть объявления о достижимости сетей автономной системы, не входящих в данную область (см. ).
4. Записи о достижимости сетей за пределами автономной системы; вносятся маршрутизаторами ?
и ?
и представляют собой просто ретрансляцию сообщений о внешних маршрутах, распространяемых пограничными маршрутизаторами системы (?
и ?
) (см. также ).
5. Записи о достижимости пограничных маршрутизаторов автономной системы (?
и ?
); вносятся маршрутизаторами ?
и ?
на основании вычислений по базе данных магистрали, к которой подключены ?
и ?
(см. также ). Каждый ABR объявляет кратчайшее расстояние от себя до каждого ASBR, которого он может достичь. Такие объявления необходимы, так как внутрь области не распространяется информация о маршрутах к маршрутизаторам других областей.
Аналогичным образом строятся базы данных состояния связей в области 2 и в магистрали.
Принуждение к ускоренной передаче данных
Механизм реагирования на заторы сети (congestion control), реализуемый протоколом TCP (RFC-2581), позволяет злоумышленнику-получателю данных принудить отправителя высылать данные с многократно увеличенной скоростью []. В результате злоумышленник отбирает для своих нужд ресурсы сервера-отправителя и компьютерной сети, замедляя или блокируя соединения прочих участников сетевого взаимодействия.
Атаки выполняются путем специально организованной посылки злоумышленником подтверждений приема данных (ACK-сегментов). Все описываемые в этом пункте атаки эксплуатируют следующее неявное допущение, заложенное в протокол TCP: один участник TCP-соединения полностью доверяет другому участнику в том, что тот действует в строгом соответствии с теми же спецификациями протокола, что и первый.
В следующих подпунктах мы будем считать, что узел А отправляет данные узлу В, а последний пытается принудить узел А передавать данные на завышенной скорости.
Проблемы безопасности протоколов TCP/IP
В данной главе рассматривается безопасность сетевого взаимодействия только на уровнях от доступа к сети до транспортного включительно, то есть охватываются аспекты безопасности собственно передачи данных через сети IP (Интернет). Здесь мы не останавливаемся на содержании этих данных и возможности их использования в неблаговидных целях. Последнее относится к безопасности прикладных протоколов и приложений Интернета.
Прежде чем перейти к разбору конкретных приемов, классифицируем действия злоумышленника — атаки, направленные против какого-либо узла (или, возможно, целой сети). Злоумышленник ставит перед собой определенную цель, как-то:
перехват (и, возможно, модификация) данных, передаваемых через сеть от одного узла другому; имперсонация (обезличивание, spoofing) (узел злоумышленника выдает себя за другой узел, чтобы воспользоваться какими-либо привилегиями имитируемого узла); несанкционированное подключение к сети; несанкционированная передача данных (обход правил фильтрации IP-трафика в сетях, защищенных брандмауэрами); принуждение узла к передаче данных на завышенной скорости; приведение узла в состояние, когда он не может нормально функционировать, передавать и принимать данные (так называемый DoS — denial of service, отказ в обслуживании).
Промежуточные состояния соединения
TCP-соединение во время функционирования проходит через ряд промежуточных состояний. Это состояния LISTEN, SYN-SENT, SYN-RECEIVED, ESTABLISHED, FIN-WAIT-1, FIN-WAIT-2, CLOSE-WAIT, CLOSING, LAST-ACK, TIME-WAIT, а также фиктивное состояние CLOSED. (Состояние CLOSED является фиктивным, поскольку оно представляет отсутствие соединения.) Переход из одного состояния в другое происходит в ответ на события, как то: запросы клиента, приход сегментов, истечение контрольного времени.
Определены следующие запросы процесса-клиента модулю TCP (с каждым запросом, кроме OPEN, передается имя соединения):
ACTIVE-OPEN - активное открытие соединения;
PASSIVE-OPEN - пассивное открытие соединения (см. выше );
SEND - отправка данных (передается указатель на буфер данных, размер буфера, значения флагов URG и PSH);
RECEIVE - получение данных (передается указатель на буфер данных, размер буфера; возвращается счетчик полученных октетов, значения флагов URG и PSH);
STATUS - запрос состояния соединения;
CLOSE - закрытие соединения (производится досылка всех неотправленных данных и обмен сегментами с битом FIN);
ABORT - ликвидация соединения (уничтожаются блок TCB и все неотправленные данные, посылается сегмент с битом RST).
Деятельность программы протокола TCP можно рассматривать как реагирование на события в зависимости от состояния соединения.
Ниже описаны состояния соединения и приведены диаграммы переходов. Под термином "процесс" здесь понимается процесс TCP-модуля, работающий с данным соединением на локальном узле; термин "чужой" относится к процессу, работающему с данным TCP-соединением на удаленном узле.
LISTEN - процесс пассивно ждет запроса со стороны чужих сокетов.
SYN-SENT - процесс отправил свой SYN и ждет чужого SYN.
SYN-RECEIVED - процесс получил чужой SYN, отправил (раньше или только что) свой SYN и ждет ACK на свой SYN.
ESTABLISHED - процесс отправил ACK на чужой SYN, получил ACK на свой SYN; соединение установлено.
FIN-WAIT-1 - процесс первый отправил свой FIN и ждет реакцию той стороны; при этом он, возможно, продолжает получать данные.
FIN-WAIT-2 - процесс получил ACK на свой ранее отправленный FIN, но не получил чужой FIN; ждет чужой FIN; при этом, возможно, продолжает получать данные.
CLOSE-WAIT - процесс, не отправив свой FIN (возможно, не собираясь прекращать соединение), получает чужой FIN; он отправляет ACK на чужой FIN, но при этом, возможно, продолжает отправлять данные.
LAST-ACK - процесс отправил свой FIN, но ранее он уже получил FIN с той стороны и отправил на него ACK; поэтому процесс ожидает чужой ACK на свой FIN для окончательного закрытия соединения.
CLOSING - процесс ранее отправил свой FIN и еще не получил не него подтверждение, но получил чужой FIN (и отправил на него ACK); ждет ACK на свой FIN.
TIME-WAIT - процесс ранее отправил свой FIN и получил на него подтверждение, получил чужой FIN и только что отправил на него ACK; теперь процесс ждет некоторое время (два времени жизни сегмента, обычно 4 минуты) для гарантии того, что та сторона получит его ACK на свой FIN, после чего соединение будет окончательно закрыто.
CLOSED - соединение отсутствует.
В диаграммах пп. 3.3.1 и 3.3.2 состояния соединения заключены в прямоугольники, переходы между ними показаны стрелками, с каждой стрелкой соотносится овал, поясняющий причину перехода. В овале над горизонтальной чертой указывается событие, вызвавшее переход (курсивом обозначено поступление запросов от локального процесса-клиента); под горизонтальной чертой - действие, сопутствующее переходу.
Прослушивание сети
Прослушивание сети Ethernet (а подавляющее большинство локальных сетей используют именно эту технологию) является тривиальной задачей: для этого нужно просто перевести интерфейс в режим прослушивания (promiscuous mode). Легко доступны программы, не только записывающие весь трафик в сегменте Ethernet, но и выполняющие его отбор по установленным критериям: например, программа или входящая в поставку ОС Solaris программа snoop.
Среди других сетевых технологий подвержены прослушиванию сети FDDI и радиосети (например Radio Еthernet). Несколько сложнее для злоумышленника извлечь трафик из телефонных выделенных и коммутируемых линий — главным образом, из-за сложности физического доступа и подключения к таким линиям. Однако следует помнить, что злоумышленник может оккупировать промежуточный маршрутизатор и таким образом получить доступ ко всему транзитному трафику, независимо от используемых технологий на уровне доступа к сети.
Ограничить область прослушивания в сети Ethernet можно разбиением сети на сегменты с помощью коммутаторов. В этом случае злоумышленник, не прибегая к активным действиям, описанным в п. , может перехватить только кадры, получаемые или отправляемые узлами сегмента, к которому он подключен. Единственным способом борьбы с прослушиванием сегмента Ethernet является шифрование данных.
Злоумышленник, прослушивающий сеть, может быть обнаружен с помощью утилиты , которая выявляет в сети узлы, чьи интерфейсы переведены в режим прослушивания.
AntiSniff выполняет три вида тестов узлов сегмента Ethernet. Первый тест основан на особенностях обработки разными операционными системами кадров Ethernet, содержащих IP-датаграммы, направленные в адрес тестируемого узла. Например, некоторые ОС, находясь в режиме прослушивания, передают датаграмму уровню IP, независимо от адреса назначения кадра Ethernet (в то время как в обычном режиме кадры, не направленные на MAC-адрес узла, системой вообще не рассматриваются). Другие системы имеют особенность при обработке кадров с широковещательным адресом: в режиме прослушивания MAC-адрес ff:00:00:00:00:00 воспринимается драйвером интерфейса как широковещательный. Таким образом, послав сообщение ICMP Echo внутри «неверного» кадра, который при нормальных обстоятельствах должен быть проигнорирован, и получив на него ответ, AntiSniff заключает, что интерфейс тестируемого узла находится в режиме прослушивания.
Второй тест основан на предположении, что программа прослушивания на хосте злоумышленника выполняет обратные DNS-преобразования для IP-адресов подслушанных датаграмм (поскольку часто по доменному имени можно определить назначение и важность того или иного узла). AntiSniff фабрикует датаграммы с фиктивными IP-адресами (то есть не предназначенные ни одному из узлов тестируемой сети), после чего прослушивает сеть на предмет DNS-запросов о доменных именах для этих фиктивных адресов. Узлы, отправившие такие запросы, находятся в режиме прослушивания.
Тесты третьей группы, наиболее универсальные, с одной стороны, так как не зависят ни от типа операционной системы, ни от предполагаемого поведения прослушивающих программ. С другой стороны, эти тесты требуют определенного анализа от оператора, то есть — не выдают однозначный результат, как в двух предыдущих случаях кроме того, они сильно загружают сеть. Тесты основаны на том, что интерфейс, находящийся в обычном режиме, отфильтровывает кадры, направленные не на его адрес, с помощью программно-аппаратного обеспечения сетевой карты, и не задействует при этом ресурсы операционной системы. Однако в режиме прослушивания обработка всех кадров ложится на программное обеспечение злоумышленника, то есть, в конечном счете, на операционную систему. AntiSniff производит пробное тестирование узлов сети на предмет времени отклика на сообщения ICMP Echo, после чего порождает в сегменте шквал кадров, направленных на несуществующие MAC-адреса, при этом продолжая измерение времени отклика. У систем, находящихся в обычном режиме, это время растет, но незначительно, в то время как узлы, переведенные в режим прослушивания, демонстрируют многократный (до 4 раз) рост задержки отклика.
В связи с вышеизложенным отметим, что представление о прослушивании как о безопасной деятельности, которую нельзя обнаружить, не соответствует действительности.
Протокол ARP
Протокол ARP (Address Resolution Protocol, Протокол распознавания адреса) предназначен для преобразования IP-адресов в MAC-адреса, часто называемые также физическими адресами.
MAC расшифровывается как Media Access Control, контроль доступа к среде передачи. МАС-адреса идентифицируют устройства, подключенные к физическому каналу, пример MAC-адреса - адрес Ethernet.
Для передачи IP-дейтаграммы по физическому каналу (будем рассматривать Ethernet) требуется инкапсулировать эту дейтаграмму в кадр Ethernet и в заголовке кадра указать адрес Ethernet-карты, на которую будет доставлена эта дейтаграмма для ее последующей обработки вышестоящим по стеку протоколом IP. IP-адрес, включенный в заголовок дейтаграммы, адресует IP-интерфейс какого-либо узла сети и не заключает в себе никаких указаний ни на физическую среду передачи, к которой подключен этот интерфейс, ни тем более на физический адрес устройства (если таковой имеется), с помощью которого этот интерфейс сообщается со средой.
Поиск по данному IP-адресу соответствующего Ethernet-адреса производится протоколом ARP, функционирующим на уровне доступа к среде передачи. Протокол поддерживает в оперативной памяти динамическую arp-таблицу в целях кэширования полученной информации. Порядок функционирования протокола следующий.
С межсетевого уровня поступает IP-дейтаграмма для передачи в физический канал (Ethernet), вместе с дейтаграммой передается, среди прочих параметров, IP-адрес узла назначения. Если в arp-таблице не содержится записи об Ethernet-адресе, соответствующем нужному IP-адресу, модуль arp ставит дейтаграмму в очередь и формирует широковещательный запрос. Запрос получают все узлы, подключенные к данной сети; узел, опознавший свой IP-адрес, отправляет arp-ответ (arp-response) со значением своего адреса Ethernet. Полученные данные заносятся в таблицу, ждущая дейтаграмма извлекается из очереди и передается на инкапсуляцию в кадр Ethernet для последующей отправки по физическому каналу.
ARP-запрос или ответ включается в кадр Ethernet непосредственно после заголовка кадра.
Форматы запроса и ответа одинаковы и отличаются только кодом операции (Operation code, 1 и 2 соответственно).

Несмотря на то, что ARP создавался специально для Ethernet, этот протокол может поддерживать различные типы физических сред (поле “Hardware type (Тип физической среды)”, значение 1 соответствует Ethernet), а также различные типы обслуживаемых протоколов (поле “Protocol type (Тип протокола)”, значение 2048 соответствует IP). Поля H-len и P-len содержат длины физического и “протокольного” адресов соответственно, в октетах. Для Ethernet H-len=6, для IP P-len=4.
Поля “Source hardware address” и “Source protocol address” содержат физический (Ethernet) и “протокольный” (IP) адреса отправителя. Поля “Target hardware address” и “Target protocol address” содержат соответствующие адреса получателя. При посылке запроса поле “Target hardware address” инициализируется нулями, а в поле “Destination (Адрес назначения)” заголовка Ethernet-кадра ставится широковещательный адрес.
Протокол EIGRP
EIGRP (Enhanced Interior Gateway Routing Protocol) – дистанционно векторный протокол маршрутизации, разработанный фирмой Cisco на основе протокола IGRP той же фирмы. Протокол IGRP был создан как альтернатива протоколу RIP (до того, как был разработан OSPF). После появления OSPF Cisco представила EIGRP – переработанный и улучшенный вариант IGRP, свободный от основного недостатка дистанционно-векторных протоколов – особых ситуаций с зацикливанием маршрутов – благодаря специальному алгоритму распространения информации об изменениях в топологии сети. Несмотря на то, что в общем случае протоколы состояния связей (OSPF) отрабатывают изменения в топологии сети быстрее, чем EIGRP, а также OSPF имеет ряд дополнительных возможностей, EIGRP более прост в реализации и менее требователен к вычислительным ресурсам маршрутизатора.
Ознакомиться с описанием протокола EIGRP можно на Интернет-сайте фирмы Cisco . Ниже мы рассмотрим основные особенности EIGRP.
EIGRP-маршрутизатор обнаруживает своих соседей путем периодической рассылки сообщений "Hello". Эти же сообщения используются для мониторинга состояния связи с соседом (рассылаются каждые 5 секунд в сетях с большой пропускной способностью – например, Ethernet – и каждые 60 секунд в "медленных" сетях). Такой мониторинг позволяет рассылать в сети векторы расстояний не периодически, а только при изменении топологии сети.
EIGRP использует комплексное значение метрики, вычисляемое на основании показателей пропускной способности и задержки при передаче данных в сети. Также в расчет метрики могут быть включены показатели загрузки и надежности сети. В отличие от протокола RIP метрика в EIGRP не является фактором, ограничивающим размер системы.
При получении от соседей векторов расстояний, маршрутизатор для каждой сети назначения не только выбирает соседа, через которого лежит кратчайший путь в эту сеть, но также запоминает и вероятных заместителей (feasible successors). Вероятным заместителем становится маршрутизатор, объявивший метрику маршрута от себя до данной сети меньшую, чем полная метрика установленного маршрута. Рассмотрим пример на рис. 6.1 (для простоты метрики всех связей, кроме (4)-(5), считаем равными единице; метрика связи (4)-(5) равна 0,5).
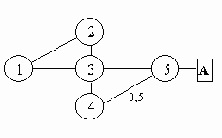
Рис 6.1. Пример EIGRP-системы
Кружками обозначены маршрутизаторы, прямоугольником – сеть назначения А. Маршрутизатор (3) получает от (5) элемент вектора расстояний (А=1), а от (4) – (А=1,5). В таблице маршрутизатора (3) узел (5) становится следующим маршрутизатором на пути в сеть А, а узел (4) – вероятным заместителем, так как заявленное им расстояние до А (1,5) меньше полной метрики установленного маршрута (3)-(5)-А, которая равна 2.
Обратим внимание на маршрутизаторы (1) и (2). Они присылают узлу (3) элемент (А=3) и, следовательно, не являются вероятными заместителями маршрута из (3) в А, что, безусловно, разумно.
Если связь между узлами (3) и (5) обрывается, то (3) ищет в своей EIGRP-таблице вероятного заместителя ((4)) и немедленно устанавливает маршрут в сеть А через него. Таким образом время, в течение которого маршрут в сеть А отсутствовал, существенно сокращается по сравнению с протоколом RIP, где требуется ждать, когда соседи пришлют очередные векторы расстояний.
Если же ни одного вероятного заместителя не найдено (допустим, связь (3)-(4) тоже обрывается), то маршрутизатор переходит в активное состояние и начинает опрос всех своих соседей на предмет наличия маршрута в сеть А, сообщая при этом что его собственное расстояние до А равно бесконечности. Здесь вступает в работу алгоритм DUAL (Diffusing Update Algorithm). Следуя этому алгоритму, сосед отвечает на запрос только тогда, когда у него есть либо готовый маршрут в А, либо вероятный заместитель – в любом из этих случаев сосед присылает в узел (3) свое расстояние до А. Иначе сосед сам переходит в активное состояние и процесс повторяется (разумеется с той разницей, что к маршрутизатору (3) запрос не посылается; кроме того, маршрутизатор, находящийся в активном состоянии, сам может отвечать на запросы, посылая в ответ свое текущее значение расстояния до А). Таким образом область "активизированных" маршрутизаторов расширяется до тех пор, пока не будет обнаружен маршрут в сеть А или доказано его отсутствие, после чего волна сходится в обратном направлении к инициировавшему процесс узлу, при этом все маршрутизаторы вносят в свои таблицы надлежащие изменения.
В нашем простом примере, после того как (3) переходит в активное состояние, узлы (1) и (2) получают от него запрос о маршруте в сеть А с пометкой, что расстояние от (3) до А теперь равно бесконечности. Каждый из них, поскольку ранее он добирался в А через (3), помечает этот маршрут как недостижимый, и, не найдя вероятного заместителя, активизируется и опрашивает своего соседа. Получив эти запросы, (1) и (2) отвечают друг другу, что сеть А недостижима, переходят в пассивное состояние и возвращают узлу (3) информацию о недостижимости сети А.
Естественно, что подобная процедура (поиск вероятного заместителя, а при отсутствии такого – запуск алгоритма DUAL) происходит не только при обрыве связи, а также и в общем случае: если следующий маршрутизатор на пути в А прислал вектор, в котором расстояние до сети А увеличилось по сравнению с предыдущим сообщением от того же маршрутизатора.
В протоколе EIGRP также реализованы процедуры Split Horizon и Poison Reverse (см. п. ), которые выполняются не всегда, а в зависимости от состояния маршрутизатора и его соседей.
Из-за того, что EIGRP-маршрутизатор не просто принимает от соседей векторы расстояний, а строит на их основе некоторое представление от топологии сети ("вероятные заместители"), контролирует состояние связи с соседями и использует алгоритм DUAL, что всё вместе напоминает протоколы состояния связей, Cisco классифицирует EIGRP как "гибридный" протокол.
(С)
Протокол Hello
После инициализации модуля OSPF (например, после подачи питания на маршрутизатор) через все интерфейсы, включенные в OSPF-систему, начинают рассылаться Hello-сообщения (формат сообщений см. в п. ). Задача Hello-протокола- обнаружение соседей и установление с ними отношений смежности.
Соседями называются OSPF-маршрутизаторы, подключенные к одной сети (к одной линии связи) и обменивающиеся Hello-сообщениями.
Смежными называются соседние OSPF маршрутизаторы, которые приняли решение обмениваться друг с другом информацией, необходимой для синхронизации базы данных состояния связей и построения маршрутов. Не все соседи становятся смежными (этот вопрос будет рассмотрен в пп. , ).
Другая задача протокола Hello - выбор выделенного маршрутизатора в сети с множественным доступом, к которой подключено несколько маршрутизаторов (см. пп. , ).
Hello-пакеты продолжают периодически рассылаться и после того, как соседи были обнаружены. Таким образом маршрутизатор контролирует состояние своих связей с соседями и может своевременно обнаружить изменение этого состояние (например, обрыв связи или отключение одного из соседей). Обрыв связи может быть также обнаружен и с помощью протокола канального уровня, который просигнализирует о недоступности канала.
В сетях с возможностью широковещательной рассылки (broadcast networks) Hello-пакеты рассылаются по мультикастинговому адресу 224.0.0.5 ("Всем ОSPF-маршрутизаторам"). В других сетях все возможные адреса соседей должны быть введены администратором.
Протокол ICMP
Протокол ICMP (Internet Control Message Protocol, Протокол Управляющих Сообщений Интернет) является неотъемлемой частью IP-модуля. Он обеспечивает обратную связь в виде диагностических сообщений, посылаемых отправителю при невозможности доставки его дейтаграммы и в других случаях. ICMP стандартизован в RFC-792, дополнения — в RCF-950,1256.
ICMP-сообщения не порождаются при невозможности доставки:
дейтаграмм, содержащих ICMP-сообщения; не первых фрагментов дейтаграмм; дейтаграмм, направленных по групповому адресу (широковещание, мультикастинг); дейтаграмм, адрес отправителя которых нулевой или групповой.
Все ICMP-сообщения имеют IP-заголовок, значение поля “Protocol” равно 1. Данные дейтаграммы с ICMP-сообщением не передаются вверх по стеку протоколов для обработки, а обрабатываются IP-модулем.
После IP-заголовка следует 32-битное слово с полями “Тип”, “Код” и “Контрольная сумма”. Поля типа и кода определяют содержание ICMP-сообщения. Формат остальной части дейтаграммы зависит от вида сообщения. Контрольная сумма считается так же, как и в IP-заголовке, но в этом случае суммируется содержимое ICMP-сообщения, включая поля “Тип” и “Код”.

Таблица 2.5.1
Виды ICMP-сообщений
Тип



Тип 9

Сообщения типа 9 ( объявление маршрутизатора) периодически рассылаются маршрутизаторами хостам сети для того, чтобы хосты могли автоматически сконфигурировать свои маршрутные таблицы. Обычно такие сообщения рассылаются по мультикастинговому адресу 224.0.0.1 (“всем хостам”) или по широковещательному адресу.
Сообщение содержит адреса одного или нескольких маршрутизаторов, снабженных значениями приоритета для каждого маршрутизатора. Приоритет является числом со знаком, записанным в дополнительном коде; чем больше число, тем выше приоритет.
Поле “NumAddr” содержит количество адресов маршрутизаторов в данном сообщении; значение поля “AddrEntrySize” равно двум (размер поля, отведенного на информацию об одном маршрутизаторе, в 32-битных словах). “Время жизни” определяет срок годности информации, содержащейся в данном сообщении, в секундах.
Тип 10
Сообщения типа 10 (запрос объявления маршрутизатора) состоит из двух 32-битных слов, первое из которых содержит поля “Тип”, “Код” и “Контрольная сумма”, а второе зарезервировано (заполняется нулями).
Типы 17 и 18

Сообщения типов 17 и 18 (запрос и ответ на запрос значения маски сети) используются в случае, когда хост желает узнать маску сети, в которой он находится. Для этого в адрес маршрутизатора (или широковещательно, если адрес маршрутизатора неизвестен) отправляется запрос. Маршрутизатор отправляет в ответ сообщение с записанным в нем значением маски той сети, из которой пришел запрос. В том случае, когда отправитель запроса еще не знает своего IP-адреса, ответ отправляется широковещательно.
Поля “Идентификатор” и “Номер по порядку” могут использоваться для контроля соответствий запросов и ответов, но в большинстве случаев игнорируются.
Протокол IGMP
Протокол IGMP (Internet Group Memebership Protocol) предназначен для регистрации на маршрутизаторе членов групп, находящихся в непосредственно присоединенных к нему сетях. Имея эту информацию, маршрутизатор может сообщать другим маршрутизаторам (с помощью протоколов групповой маршрутизации) о необходимости пересылки ему дейтаграмм для тех или иных групп. Современная версия протокола IGMP – версия 2 – документирована в RFC-2236.
IGMP работает непосредственно поверх протокола IP, и идентифицируется значением 2 в поле "Protocol" заголовка IP-дейтаграммы. За IP-заголовком в дейтаграмме следует сообщение IGMP:

Значения полей:
Type (8 бит) – тип сообщения.
Max Response Time (8 бит) – максимальное время отклика, задествовано только в сообщениях типа Membership Query.
Checksum (16 бит) – контрольная сумма.
Group Address (32 бита) – групповой IP-адрес.
Существуют следующие типы сообщений:
Membership Query (Type=17) – запрос о наличии в сети членов групп (отправляется маршрутизатором). Запросы обо всех имеющихся группах – общие запросы – отправляются по адресу 224.0.0.1 ("всем узлам"); запросы о наличии членов определенной группы – частные запросы – отправляются по адресу этой группы.
Membership Report (Type=22) – уведомление о наличии в сети члена группы (отправляется хостом – членом группы по адресу группы).
Leave Group (Type=23) – уведомление об отсоединении хоста от группы (отправляется отсоединившимся хостом по адресу 224.0.0.2 – "всем маршрутизаторам").
Протокол функционирует следующим образом.
Маршрутизатор при своем включении и далее периодически рассылает по адресу 224.0.0.1 общий запрос Membership Query, при этом поле "Group Address" обнулено. Период этих рассылок может меняться администратором; значение по умолчанию – 125 с. Приняв такой запрос, каждый получатель групповых дейтаграмм выжидает случайное время. Если за это время кто-то другой уже ответил сообщением Membership Report, то данный хост не отвечает, иначе он сам посылает такое сообщение. Значение поля "Max Response Time" в Membership Query указывает максимальное время, на которое хост может задержать Membership Report (обычно 10 с). Описанный подход используется, чтобы избежать посылки многочисленных ответов с адресом одной и той же группы: маршрутизатору не нужно знать, сколько именно членов данной группы есть у него в сети, ему требуется лишь сам факт их наличия.
Сообщение Membership Report посылается по адресу группы, и этот же адрес помещается в поле "Group Address". Следует отметить, что маршрутизатор является членом всех групп, то есть получает сообщения, направленные на любой групповой адрес.
Если хост является членом нескольких групп, то вышеописанная процедура с выжиданием и отправкой ответа выполняется независимо для каждой группы.
При подключении хоста к новой группе он самостоятельно отправляет сообщение типа Membership Report, не дожидаясь очередного запроса от маршрутизатора.
Для каждой группы, члены которой обнаружились в сети, маршрутизатор ведет отсчет времени неактивности. Если ни одного Membership Report для этой группы не было получено за определенный период (по умолчанию – 260 с), то маршрутизатор считает, что членов этой группы в сети больше нет.
Когда хост отсоединяется от группы, он может послать сообщение Leave Group по групповому адресу 224.0.0.2 ("всем маршрутизаторам"); адрес группы содержится в поле "Group Address". Хосту следует сделать это, если на последний запрос Membership Query от имени данной группы отвечал именно этот хост. Получив сообщение Leave Group, маршрутизатор генерирует частный запрос Membership Query для членов только этой группы. Если за время, указанное в поле "Max Response Time" запроса (по умолчанию – 1 с), маршрутизатор не получил ни одного ответа Membership Report, он считает, что членов данной группы в сети больше нет. Для надежности запрос посылается 2 раза.
Если к одной сети подключены несколько маршрутизаторов, поддерживающих протокол IGMP, то запросы рассылает только маршрутизатор с наименьшим IP-адресом (то есть, если маршрутизатор получил из сети Membership Query с IP-адресом отправителя меньшим, чем его собственный адрес, он должен перестать посылать запросы и перейти в режим прослушивания обмена IGMP-сообщениями).
Для обратной совместимости с первой версией протокола IGMP предусмотрено сообщение Membership Report version 1 (Type=18), а также некоторые специальные действия при работе протокола. Подробнее об этом можно узнать в документе RFC-2236.
Протокол обмена
После установления отношений смежности для каждой пары смежных маршрутизаторов происходит синхронизация их баз данных. Эта же операция происходит при восстановлении ранее разорванного соединения, поскольку в образовавшихся после аварии двух изолированных подсистемах базы данных развивались независимо друг от друга. Синхронизация баз данных происходит с помощью протокола обмена (Exchange protocol).
Сначала маршрутизаторы обмениваются только описаниями своих баз данных (Database Description), содержащими идентификаторы записей и номера их версий, это позволяет избежать пересылки всего содержимого базы данных, если требуется синхронизировать только несколько записей (подробнее алгоритм обмена и формат сообщений описан в ).
Во время этого обмена каждый маршрутизатор формирует список записей, содержимое которых он должен запросить (то есть эти записи в его базе данных устарели либо отсутствуют), и соответственно отправляет пакеты запросов о состоянии связей (Link State Request, см. также ). В ответ он получает содержимое последних версий нужных ему записей в пакетах типа "Обновление состояния связей (Link State Update)" (см. также ).
После синхронизации баз данных производится построение маршрутов, как описано в .
Протокол OSPF
Протокол маршрутизации OSFP (Open Shortest Path First) представляет собой протокол состояния связей, использующий алгоритм SPF поиска кратчайшего пути в графе. OSPF применяется для внутренней маршрутизации в системах сетей любой сложности.
Протокол RIP
Протокол RIP является дистанционно-векторным протоколом внутренней маршрутизации. Процесс работы протокола состоит в рассылке, получении и обработке векторов расстояний до IP-сетей, находящихся в области действия протокола, то есть в данной RIP-системе. Результатом работы протокола на конкретном маршрутизаторе является таблица, где для каждой сети данной RIP-системы указано расстояние до этой сети (в хопах) и адрес следующего маршрутизатора. Информация о номере сети и адресе следующего маршрутизатора из этой таблицы вносится в таблицу маршрутов, информация о расстоянии до сети используется при обработке векторов расстояний.