Адресация Internet
Адресация Internet
Каждый интерфейс в объединенной сети должен иметь уникальный IP адрес. Эти адреса представляют из себя тридцатидвухбитовые числа. Cуществует определенная структура адреса Internet. На рисунке 1.5 показано 5 классов адресов Internet.
Эти 32-битные адреса обычно записываются как 4 десятичных числа, по одному на каждый байт адреса. Такая форма записи называется "десятичной записью с точками" (dotted-decimal). Например, адрес сети класса B может быть записан как 140.252.13.33.
Определить класс адреса, или класс сети, можно по первому числу в адресе. На рисунке 1.6 показаны различные классы, причем первое число выделено.
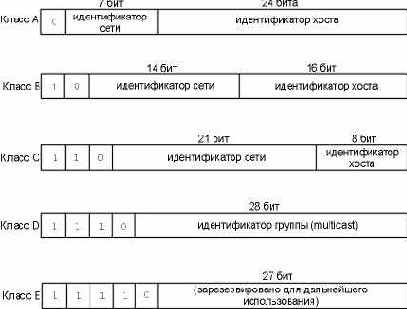
Рисунок 1.5 Пять классов адресов Internet.
| Класс | Диапазон |
| A | 0.0.0.0 - 127.255.255.255 |
| B | 128.0.0.0 - 191.255.255.255 |
| C | 192.0.0.0 - 223.255.255.255 |
| D | 224.0.0.0 - 239.255.255.255 |
| E | 240.0.0.0 - 247.255.255.255 |
Здесь хотелось бы отметить, что хосты с несколькими интерфейсами имеют несколько IP адресов: по одному на каждый интерфейс.
Так как каждый интерфейс, подключенный к сети, должен иметь уникальный адрес, встает вопрос распределения IP адресов в глобальной сети Internet. Этим занимается сетевой информационный центр (Internet Network Information Center или InterNIC). InterNIC назначает только сетевые идентификаторы (ID). Назначением идентификаторов хостов в сети занимаются системные администраторы.
Регистрация сервисов Internet (IP адреса и имена доменов DNS) осуществляется в NIC, nic.ddn.mil. InterNIC была создана 1 апреля 1993 года. В настоящее время NIC регистрирует сервисы только для сети министерства обороны (DDN - Defence Data Network). Все другие пользователи Internet в настоящее время используют регистрационный сервис InterNIC в rs.internic.net.
Реально существует три части InterNIC: регистрационный сервис (rs.internic.net), сервис баз данных (ds.internic.net) и информационный сервис (is.internic.net). См. Упражнение 8 главы 1.
Существует три типа IP адресов: персональный адрес (unicast) - указывает на один хост, широковещательный адрес (broadcast) - указывает на все хосты в указанной сети, и групповой адрес (multicast) - указывает на группу хостов, принадлежащей к группе адресации. В главе 12 и главе 13 мы рассмотрим широковещательные и групповые запросы более подробно.
В разделе "Адресация подсетей" главы 3 мы продолжим описание IP адресации, включая подсети, после того как опишем IP маршрутизацию. На рисунке 3.9 показаны особые случаи IP адресов: идентификатор хоста и идентификатор сети, установленные во все нули или во все единицы.
Демультиплексирование (Demultiplexing)
Демультиплексирование (Demultiplexing)
Когда фрейм Ethernet принимается компьютером приемником, он начинает свой путь вверх по стеку протоколов, при этом все заголовки удаляются в соответствующих уровнях. Каждый протокол просматривает определенные идентификаторы в заголовке, чтобы определить, какой следующий верхний уровень должен получить данные. Этот процесс называется демультиплексированием (demultiplexing), он проиллюстрирован на рисунке 1.8.
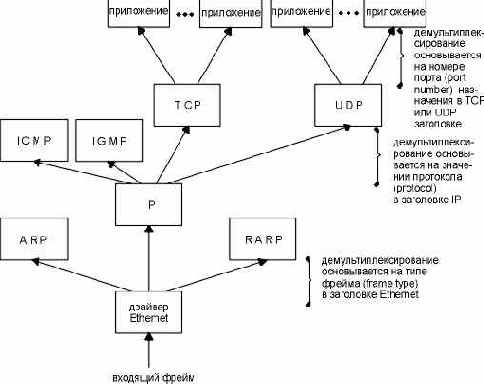
Рисунок 1.8 Демультиплексирование полученного Ethernet фрейма.
Местоположение квадратиков, помеченных именами протоколов "ICMP" и "IGMP", всегда различно. На рисунке 1.4 мы показали их на том же уровне, что и IP, потому что в действительности они являются дополнением к протоколу IP. Однако здесь мы показали их выше чем IP, чтобы подчеркнуть то, что сообщения ICMP и IGMP инкапсулируются в IP датаграммы.
Тот же самый подход был использован с квадратиками, помеченными "ARP" и "RARP". Здесь мы показали их выше чем драйвер устройства Ethernet, потому что оба они имеют свой собственный тип фреймов Ethernet, как IP датаграммы. Однако на рисунке 2.4 мы покажем ARP как часть драйвера устройства Ethernet, что будет более логично.
Естественно, что рисунки, иллюстрирующие протоколы и их взаимодействия, всегда несовершенны.
Когда мы будем рассматривать TCP более подробно, мы увидим, что в действительности демультиплексирование входящих сегментов использует номер порта назначения, IP адрес источника и номер порта источника.
Глава 1 Введение
Глава 1 Введение
Инкапсуляция
Инкапсуляция
Когда приложение посылает данные с использованием TCP, данные опускаются вниз по стеку протоколов, проходя через каждый уровень, до тех пор пока они не будут отправлены в виде потока битов по сети. Каждый уровень добавляет свою информацию к данным путем пристыковки заголовков (а иногда завершителей). На рисунке 1.7 показан этот процесс. Блок данных, который TCP посылает в IP, называется TCP сегментом. Блок данных, который IP посылает в сетевой интерфейс, называется IP датаграммой. Поток битов, который передается по Ethernet, называется фреймом (frame).
Числа, стоящие под заголовком и завершителем Ethernet фрейма на рисунке 1.7, показывают стандартный размер заголовков в байтах. В следующих разделах мы расскажем о заголовках более подробно.
Одной из физических характеристик фрейма Ethernet является та, что размер данных должен быть в диапазоне между 46 и 1500 байт. Минимальный размер мы обсудим в разделе "Примеры ARP" главы 4, а максимальный в разделе "MTU" главы 2.
Все стандарты Internet и большинство книг про TCP/IP используют термин октет (octet) вместо слова байт. Такая терминология сложилась исторически, однако мы будем использовать именно слово байт (byte).
Чтобы быть максимально точными, рассматривая рисунок 1.7, мы должны сказать, что блок данных, передаваемый между IP и сетевым интерфейсом, называется пакетом (packet). Этот пакет может быть как IP датаграммой, так и фрагментом IP датаграммы. Мы рассмотрим фрагментацию более подробно в разделе "Фрагментация IP" главы 11.
Что касается UDP данных, то картина там практически идентичная. Единственное различие заключается в том, что блок информации, который UDP передает в IP, называется UDP датаграммой, а размер UDP заголовка составляет 8 байт.
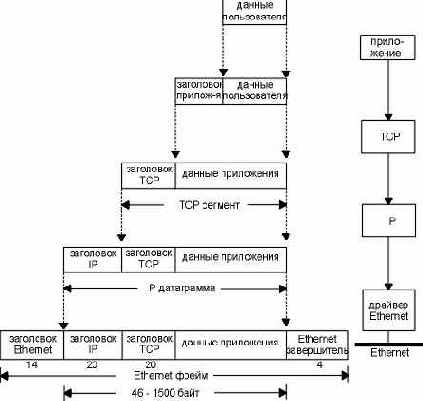
Рисунок 1.7 Инкапсуляция данных, осуществляемая по мере того, как они проходят по стеку протоколов.
Снова обратимся к рисунку 1.4, на котором показано как TCP, UDP, ICMP и IGMP посылают данные в IP. IP должен добавить какой-либо идентификатор к IP заголовку, который он генерирует, чтобы указать какому уровню принадлежат данные. IP делает это путем сохранения восьмибитного значения в своем заголовке, которое называется полем протокола. Это значение равно 1 для ICMP, 2 для IGMP, 6 для TCP и 17 для UDP.
Точно так же различные приложения могут использовать TCP или UDP в одно и то же время. Протоколы транспортного уровня сохраняют в заголовке идентификатор приложения, которое их использует. TCP и UDP оба используют шестнадцатибитный номер порта (port number), чтобы указать на приложения. TCP и UDP сохраняют номер порта источника и номер порта назначения в своих заголовках.
Сетевой интерфейс посылает и принимает фреймы, принадлежащие IP, ARP и RARP. Должна существовать форма идентификации в заголовке Ethernet, которая бы указывала, какой сетевой уровень сгенерировал данные. Для этого существует шестнадцатибитное поле типа фрейма в заголовке Ethernet.
Интерфейсы прикладного программирования
Интерфейсы прикладного программирования
Два популярных интерфейса прикладного программирования (API - application programming interface) для приложений, использующих протоколы TCP/IP, называются сокетами (sockets) и интерфейсом транспортного уровня (TLI - Transport Layer Interface) . Первый иногда называется "Berkeley sockets", что указывает на то где он был разработан. Последний, исходно разработанный в AT&T, иногда называется XTI (X/Open Transport Interface), это работа, произведенная X/Open, международной группой поставщиков компьютеров, которые создали свой собственный набор стандартов. XTI в действительности является расширением TLI.
При написании этой книги мы не задавались целью подробно рассматривать низкий уровень программирования, однако, где это возможно, будем ссылаться на отдельные характеристики TCP/IP, в частности на большинство популярных API. Все детали программирования, как для сокет так и для TLI, можно найти в [Stevens 1990].
Internet
Internet
На рисунке 1.3 показано соединение двух сетей - Ethernet и Token ring. В разделах "Адресация Internet" и "Номера портов" главы 1 мы говорили о глобальной сети Internet и о необходимости централизованного распределения IP адресов (InterNIC), а также о заранее известных номерах портов (IANA) . Само слово internet имеет различный смысл, в зависимости от того, начинается ли оно с большой буквы или с маленькой.
Слово internet означает несколько сетей, соединенных вместе, использующих общее семейство протоколов. Слово Internet, начинающееся с большой буквы, обозначает определенное количество компьютеров (более миллиона), находящихся по всему миру, которые могут общаться друг с другом с использованием TCP/IP. Поэтому Internet это internet, а не наоборот.
Краткие выводы
Краткие выводы
В этой главе мы совершили короткое путешествие в огромный мир семейства протоколов TCP/IP, представили большинство терминов и протоколов, которые будут обсуждены более подробно в следующих главах.
Существует четыре уровня семейства протоколов TCP/IP - канальный уровень (link layer), сетевой уровень (network layer), транспортный уровень (transport layer) и прикладной уровень (application layer). Мы показали, за что отвечает каждый из этих уровней. В TCP/IP существуют серьезные различия между сетевым и транспортным уровнями: сетевой уровень (IP) предоставляет сервис, не ориентированный на соединение (пересылка за пересылкой - hop-by-hop), тогда как транспортный уровень предоставляет сервис с соединением (точка в точку - end-to-end) (TCP и UDP).
"internet" это несколько сетей. Основное средство, используемое для объединения сетей (internet) это маршрутизатор, который соединяет сети на IP уровне. Заглавная "I" в слове "Internet" обозначает сеть, которая охватывает весь земной шар.
В сети каждый интерфейс имеет уникальный IP адрес, однако пользователи могут использовать имена хостов вместо IP адресов. Система имен доменов (DNS) позволяет установить динамическое соответствие между именами хостов и IP адресами. Номера портов используются для идентификации приложений, общающихся друг с другом. При этом мы сказали, что сервера используют заранее-известные порты (well-known), тогда как клиенты используют динамически назначаемые порты (ephemeral port).
Модель Клиент-Сервер
Модель Клиент-Сервер
Большинство сетевых приложений написано таким образом, что с одной стороны присутствует клиент, а с другой - сервер. При этом сервер предоставляет определенные сервисы клиентам.
Можно подразделить серверы на два класса: последовательные (iterative) и конкурентные (concurrent). Последовательный сервер функционирует следующим образом.
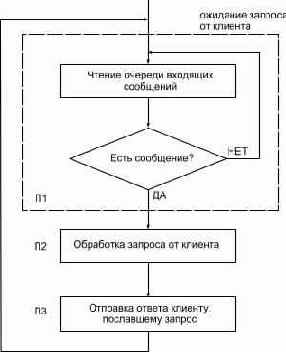
Рисунок 1.8.1 Алгоритм работы последоватеьного сервера
В процессе выполнения шага П2 могут возникнуть проблема. Она заключается в том, что в это время никакие другие клиенты не могут быть обслужены.
Конкурентный сервер, с другой стороны, работает следующим образом.
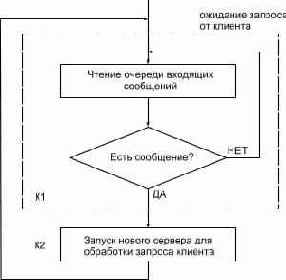
Рисунок 1.8.2 Алгоритм работы конкурентного сервера
Запуск нового сервера на шаге К2 для обработки запроса клиента может выглядеть как создание нового процесса, задачи, в зависимости от того какая операционная система лежит в основе этого сервера. Новый сервер обрабатывает поступивший запрос клиента целиком. По завершении сервер уничтожается.
Преимущество конкурентного сервера заключается в том, что он просто запускает другие сервера для обработки запросов от клиентов. В подобном случае каждый клиент имеет собственный сервер. Предполагается, что операционная система поддерживает многозадачность и обслуживание нескольких клиентов одновременно.
Мы подразделили именно сервера, а не клиентов, специально, потому что в обычных условиях клиент не может сказать, с каким сервером, последовательным или конкурирующим, он общается.
В общем случае, серверы TCP - конкурентные, а серверы UDP - последовательные. Однако из этого правила могут быть исключения. Более подробно мы рассмотрим UDP серверы в разделе "Сервер UDP" главы 11, а TCP серверы - в разделе "Реализация TCP сервера" главы 18.
Номера портов
Номера портов
Как мы уже сказали, TCP и UDP идентифицируют приложения с использованием 16-битных номеров порта. Рассмотрим, как выбираются эти номера портов.
Обычно серверы знают свои заранее известные (well-known) номера портов. Например, каждая реализация TCP/IP, предоставляющая FTP сервер, знает, что сервисный порт TCP номер 21 зарезервирован для FTP сервиса. Каждый Telnet сервер имеет порт номер 23. Каждая реализация TFTP (Trivial File Transfer Protocol) использует UDP порт 69. Подобные сервисы, предоставляемые в любой реализации TCP/IP, имеют заранее известные номера портов в диапазоне от 1 до 1023. Заранее известные порты обслуживаются Internet Assigned Numbers Authority (IANA).
До 1992 года номера заранее известных портов находились в диапазоне от 1 до 255. Порты между 256 и 1023 обычно использовались UNIX системами для специальных сервисов. Эти сервисы присутствовали в UNIX системах, однако могли не присутствовать в других операционных системах. В настоящее время IANA обслуживает порты в диапазоне от 1 до 1023.
В качестве примера различия между Internet сервисом и специализированным UNIX сервисом можно показать различие между Telnet и Rlogin. Оба позволяют осуществить терминальный заход по сети на удаленный компьютер. Telnet это стандарт TCP/IP с номером заранее известного порта 23. Он поддерживается практически во всех операционных системах. Rlogin, с другой стороны, исходно был разработан в UNIX системах (однако многие не UNIX системы в настоящее время также предоставляют этот сервис). Однако заранее известный порт был выбран в начале 80-годов и установлен в значение 513.
Клиент обычно не заботится о том, какой порт используется с его стороны. Все что ему необходимо, это быть уверенным, что данный номер порта уникален на его компьютере. Номер порта клиента называется динамически назначаемым портом (ephemeral port), то есть портом с коротким временем жизни. Это объясняется тем, что клиент обычно существует ровно столько времени, сколько пользователь нуждается в клиентском сервисе, тогда как сервера функционируют все время, пока запущен компьютер.
Большинство реализаций TCP/IP располагают номера динамически назначаемых портов в диапазоне значений между 1024 и 5000. Номера портов свыше 5000 предназначены для других серверов (не зарезервированных в сети Internet) . Далее по тексту мы встретим множество примеров того, как располагаются или назначаются динамически назначаемые порты.
Solaris 2.2 является исключением. По умолчанию, динамически назначаемые порты TCP и UDP начинаются с 32768. В разделе "Solaris 2.2" приложения E подробно рассматриваются опции конфигурирования, которые могут быть модифицированы системным администратором, чтобы изменить установки по умолчанию.
В большинстве UNIX систем номера заранее известных портов находятся в файле /etc/services. Чтобы найти номер порта для сервера Telnet и Domain Name System, можно исполнить следующую команду:
sun % grep telnet /etc/services
telnet 23/tcp используется порт TCP 23
sun % grep domain /etc/services
domain 53/udp используются порты UDP 53
domain 53/tcp и TCP порт 53
Процесс стандартизации
Процесс стандартизации
Кто контролирует семейство протоколов TCP/IP, добавляет новые стандарты и так далее? Существует 4 группы, которые несут ответственность за технологию Internet.
Internet Society (ISOC) это сообщество профессионалов, которое отвечает за настройку и поддержку роста Internet как мировой исследовательской коммуникационной инфраструктуры. Internet Architecture Board (IAB) занимается технической координацией. Состоит примерно из 15 добровольцев по всему миру, которые отвечают за различные дисциплины и являются последней инстанцией при принятии и оценке качества стандартов Internet. IAB находится под управлением ISOC. Internet Engineering Task Force (IETF) - группа, занимающаяся стандартами. Поделена на 9 зон (приложения, маршрутизация и адресация, безопасность, и так далее). IETF разрабатывает спецификации, которые становятся стандартами Internet. В помощь IETF была сформирована группа Internet Engineering Steering Group (IESG). Internet Research Task Force (IRTF) занимается долговременными проектами.
IRTF и IETF находятся под управлением IAB. [Crocker 1993] предоставляет дополнительную информацию о процессе стандартизации в рамках Internet.
Реализации
Реализации
Де факто стандарт для реализаций TCP/IP появился в группе компьютерных исследований Калифорнийского университета в Berkeley. Исторически он распространялся с 4.x BSD system (Berkeley Software Distribution), и с BSD Networking Releases. Исходные тексты этой реализации явились отправной точкой для множества последующих.
На рисунке 1.10 показана хронология появления различных релизов BSD и указаны важнейшие характеристики TCP/IP. BSD Networking Releases, показанный слева, свободно распространяемый исходный код, который содержит все исходные сетевые коды: как самих протоколов, так и большинства приложений и утилит (таких как Telnet и FTP).
Надо сказать, что довольно сложно вычислить, когда и как появился релиз Net/3.
По тексту мы используем термин "реализации, произошедшие от Berkeley" или "Berkeley реализации", чтобы указать на следующие реализации: SunOS 4.x, SVR4, и AIX 3.2, которые были разработаны с использованием исходных текстов Berkeley.
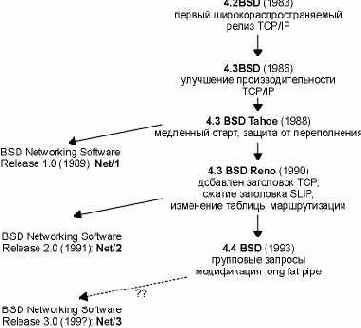
Рисунок 1.10 Различные релизы BSD и их важнейшие функции.
Эти реализации имеют очень много общего, включая одни и те же ошибки!
Большинство исследований в Internet до сих пор осуществляется с использованием системы Berkeley - новые алгоритмы предотвращения переполнения (глава 21, раздел "Быстрая повторная передача и алгоритм быстрого восстановления"), групповые запросы (глава 12, раздел "Рассылка групповых сообщений"), работа с каналами с повышенной пропускной способностью (глава 24, раздел "Каналы с повышенной пропускной способностью (Long Fat Pipes)") и так далее.
RFC
RFC
Все официальные стандарты сообщества internet публикуются в Request for Comment, или в RFC. В дополнение, существует множество RFC, которые не являются официальными стандартами, однако они публикуются с информационными целями. Диапазон размеров RFC колеблется от 1 до почти 200 страниц. Каждый из них имеет собственный номер.
Все RFC доступны бесплатно по электронной почте или с использованием FTP через Internet. Послать электронную почту можно следующим образом:
To: rfc-info@ISI.EDU
Subject: getting rfcs
help: ways_to_get_rfcs
после чего можно получить подробный список возможных путей получения RFC.
Начиная изучать какую-либо проблему, наиболее полезным является просмотреть последние RFC. Для отслеживания новых публикаций существует индекс RFC, который содержит подробную информацию о том когда были заменены RFC на более новые и какая информация появилась во вновь вышедших RFC.
Существует несколько важных RFC. Assigned Numbers RFC содержит в себе все числа и константы, которые используются в протоколах Internet. В настоящее время самая последняя версия этого RFC имеет номер 1340 [Reynolds and Postel 1992]. Также здесь описаны все заранее известные порты глобальной сети Internet.
Когда RFC обновляется (обычно это происходит ежегодно), список индексов для 1340 указывает, какой RFC заменил его. Официальные стандарты протоколов Internet (Internet Official Protocol Standards), в настоящее время RFC 1600 [Postel 1994]. Этот RFC содержит информацию о состоянии стандартизации различных протоколов Internet. Каждый протокол имеет одно из следующих состояний стандартизации: стандарт, необязательный стандарт, рекомендованный стандарт, экспериментальный, информационный, или исторический. В дополнение, каждый протокол имеет уровень необходимости: необходим, рекомендуется, на выбор, с ограниченным использованием, или не рекомендуется.
Как и Assigned Numbers RFC, этот RFC регулярно переиздается. При чтении этого RFC убедитесь, что Вы используете последнюю копию. Требования к хостам Host Requirements RFC, 1122 и 1123 [Braden 1989a, 1989b]. RFC 1122 описывает канальный уровень, сетевой уровень и транспортный уровень, тогда как RFC 1123 описывает прикладной уровень. Эти два RFC корректируют и интерпретируют различные важные RFC, вышедшие раньше, и часто являются исходной точкой при изучении деталей того или иного протокола. Список характеристик и конкретных подробностей протоколов следующий: "должен", "следует", "может", "не следует" или "не должен".
[Borman 1993b] приводит практический взгляд на эти два RFC, а RFC 1127 [Braden 1989c] содержит краткий информационный справочник дискуссий и выводов в рабочих группах, которые разрабатывали Host Requirements RFC. Требования к маршрутизаторам Router Requirements RFC. Официальная версия этого RFC - RFC 1009 [Braden and Postel 1987], однако новая версия близка к завершению [Almquist 1993]. Это RFC напоминает RFC требования к компьютерам, однако содержит уникальные требования к маршрутизаторам.
Система имен доменов (DNS - Domain Name System)
Система имен доменов (DNS - Domain Name System)
Несмотря на то что каждый сетевой интерфейс компьютера имеет свой собственный IP адрес, пользователи привыкли работать с именами хостов. Существует распределенная мировая база данных TCP/IP, называемая системой имен доменов (DNS - Domain Name System), которая позволяет установить соответствие между IP адресами и именами хостов. В главе 14 мы рассмотрим DNS более подробно.
А теперь мы должны быть уверены, что любое приложение может вызвать функцию из стандартной библиотеки, для того чтобы определить IP адрес (или адреса, соответствующие данному имени хоста). Точно так же эта функция предоставляет возможность осуществить и обратную процедуру, то есть по заданному IP адресу определить соответствующее имя хоста.
Большинство приложений, которые воспринимают имя хоста в качестве аргумента, также воспринимают и IP адреса. Когда мы используем Telnet, в главе 4, например, в одном случае мы указываем имя хоста, а в другом случае - IP адрес.
Стандартные простые сервисы
Стандартные простые сервисы
Существует несколько стандартных простых сервисов, которые присутствуют практически в каждой реализации. Мы используем некоторые из этих сервисов по тексту, обычно с клиентом Telnet. Эти сервисы описываются на рисунке 1.9. Можно заметить, что когда один и тот же сервис предоставляется с использованием и TCP и UDP, оба номера порта обычно выбираются одинаковыми.
Если повнимательнее посмотреть на номера портов этих и других стандартных сервисов TCP/IP (Telnet, FTP, SMTP, и так далее), то можно заметить, что большинство из них имеют нечетные номера. Так сложилось исторически, так как номера портов были заимствованы от номеров портов NCP. Протокол управления сетью (NCP - Network Control Protocol) предшествовал TCP в качестве транспортного уровня для ARPANET. NCP был симплексный, не полнодуплексный, каждое приложение требовало двух соединений, поэтому пара четных-нечетных чисел в качестве номеров портов, была зарезервирована для каждого приложения. Когда TCP и UDP стали стандартными транспортными уровнями, на каждое приложение потребовался один номер порта, поэтому в качестве номеров порта были использованы нечетные номера портов NCP.
| Имя | порт TCP | порт UDP | RFC | Описание |
| echo | 7 | 7 | 862 | Сервер возвращает все посланное клиентом |
| discard | 9 | 9 | 863 | Сервер игнорирует все посланное клиентом |
| daytime | 13 | 13 | 867 | Сервер выдает время и дату в читаемом формате |
| chargen | 19 | 19 | 864 | TCP сервер посылает продолжающийся поток символов, до тех пор пока соединение не будет разорвано клиентом. UDP сервер посылает датаграммы с произвольным количеством каждый раз когда пользователь посылает датаграмму |
| time | 37 | 37 | 868 | Сервер выдает время как 32-х битовое бинарное число. Это число означает количество секунд с полуночи 1- го Января 1900, UTC. |
Рисунок 1.9 Стандартные сервисы, предоставляемые большинством реализаций.
Тестируемая сеть
Тестируемая сеть
На рисунке 1.11 показана тестируемая сеть, которая используется для всех примеров в тексте этой книги.
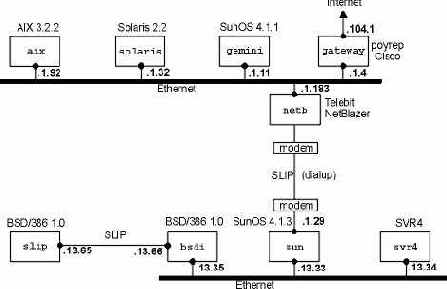
Рисунок 1.11 Сеть, используемая для всех примеров в тексте. Все IP адреса начинаются с 140.252.
Большинство примеров запускаются на четырех системах, которые показаны в нижней части рисунка. Все IP адреса на этом рисунке принадлежат сети класса B 140.252. Все имена хостов принадлежат домену .tuc.noao.edu (noao это "National Optical Astronomy Observatories", а tuc это Tuscon). Например, нижняя правая система имеет полное имя хоста svr4.tuc.noao.edu с IP адресом 140.252.13.34. Над каждым квадратиком указана операционная система, под управлением которой работает данный компьютер. Подобный набор систем и сетей, компьютеров и маршрутизаторов позволяет подробно рассмотреть различные реализации TCP/IP.
Необходимо отметить, что в действительности, в домене noao.edu значительно больше сетей и хостов, нежели тех, что показаны на рисунке 1.11. Однако здесь показаны те системы, которые использовались в качестве примеров в книге.
В разделе "Адресация подсетей" главы 3 мы опишем способ деления этой сети на подсети, а в разделе "Уполномоченный агент ARP" главы 4 подробно рассмотрим dialup SLIP (IP по последовательной линии с дозвоном) соединения между sun и netb. В разделе "SLIP: IP по последовательной линии" главы 2 SLIP описан более подробно.
Упражнения
Упражнения
Вычислите максимально возможное количество компьютеров в сетях класса A, B и C. Воспользовавшись анонимным FTP (глава 27, раздел "Примеры FTP"), получите файл nfsnet/statistics/history.netcount с хоста ftp://nic.merit.edu. В этом файле содержится количество местных и иностранных сетей, объявленных в инфраструктуре NFSNET. Распределите полное количество сетей по годам (по оси ОХ - годы, по OY - количество сетей). Максимальное значение по оси OY должно совпадать со значением, рассчитанным в предыдущем упражнении. Если данные примерно совпадут, экстраполируйте значения, чтобы оценить, когда текущая схема адресации переполнится сетевыми идентификаторами (раздел "Будущее IP" главы 3 рассказывает о том, как можно решить подобную проблему). Достаньте копию Host Requirements RFC [Braden 1989a] и рассмотрите принцип непотопляемости (robustness principle) , который применяется к каждому уровню семейства протоколов TCP/IP. Какое применение можно найти для этого принципа? Получите копию последнего Assigned Numbers RFC. Каков зарезервированный порт протокола "quote of the day"? Какой RFC определяет этот протокол? Имеете ли Вы компьютер, который подключен к сети TCP/IP, какой его основной IP адрес? Подключен ли этот компьютер к мировой сети Internet? Имеет ли он несколько интерфейсов? Получите копию RFC 1000, чтобы понять, откуда появился термин RFC. Установите контакт с сообществом Internet, isoc@isoc.org или + 1 703 648 9888, чтобы получить информацию о вступлении. Получите файл about-internic/information-about-the-internic, используя анонимный FTP с хоста ftp://is.internic.net.
Назад
Компания | Услуги | Для клиентов | Библиотека | Галерея | Cофт | Линки
На главную
Уровни
Уровни
Сетевые протоколы обычно разрабатываются по уровням, причем каждый уровень отвечает за собственную фазу коммуникаций. Семейства протоколов, такие как TCP/IP, это комбинации различных протоколов на различных уровнях. TCP/IP состоит из четырех уровней, как показано на рисунке 1.1.
| Прикладной | Telnet, FTP, e-mail и т.д. |
| Транспортный | TCP,UDP |
| Сетевой | IP, ICMP, IGMP |
| Канальный | драйвер устройства и интерфейсная плата |
Рисунок 1.1 Четыре уровня протоколов TCP/IP.
Каждый уровень несет собственную функциональную нагрузку. Канальный уровень (link layer). Еще его называют уровнем сетевого интефейса. Обычно включает в себя драйвер устройства в операционной системе и соответствующую сетевую интерфейсную плату в компьютере. Вместе они обеспечивают аппаратную поддержку физического соединения с сетью (с кабелем или с другой используемой средой передачи). Сетевой уровень (network layer), иногда называемый уровнем межсетевого взаимодействия, отвечает за передачу пакетов по сети. Маршрутизация пакетов осуществляется именно на этом уровне. IP (Internet Protocol - протокол Internet), ICMP (Internet Control Message Protocol - протокол управления сообщениями Internet) и IGMP (Internet Group Management Protocol - протокол управления группами Internet) обеспечивают сетевой уровень в семействе протоколов TCP/IP. Транспортный уровень (transport layer) отвечает за передачу потока данных между двумя компьютерами и обеспечивает работу прикладного уровня, который находится выше. В семействе протоколов TCP/IP существует два транспортных протокола: TCP (Transmission Control Protocol) и UDP (User Datagram Protocol). TCP осуществляет надежную передачу данных между двумя компьютерами. Он обеспечивает деление данных, передающихся от одного приложения к другому, на пакеты подходящего для сетевого уровня размера, подтверждение принятых пакетов, установку тайм-аутов, в течение которых должно прийти подтверждение на пакет, и так далее. Так как надежность передачи данных гарантируется на транспортном уровне, на прикладном уровне эти детали игнорируются. UDP предоставляет более простой сервис для прикладного уровня. Он просто отсылает пакеты, которые называются датаграммами (datagram) от одного компьютера к другому. При этом нет никакой гарантии, что датаграмма дойдет до пункта назначения. За надежность передачи данных, при использовании датаграмм отвечает прикладной уровень. Для каждого транспортного протокола существуют различные приложения, которые их используют. Прикладной уровень (application layer) определяет детали каждого конкретного приложения. Существует несколько распространенных приложений TCP/IP, которые присутствуют практически в каждой реализации: Telnet - удаленный терминал FTP, File Transfer Protocol - протокол передачи файлов SMTP, Simple Mail Transfer Protocol - простой протокол передачи электронной почты SNMP, Simple Network Management Protocol - простой протокол управления сетью. Если у нас есть два компьютера в локальной сети, (например, Ethernet) и на обоих запущен FTP, то данные протоколы будут работать так, как показано на рисунке 1.2.
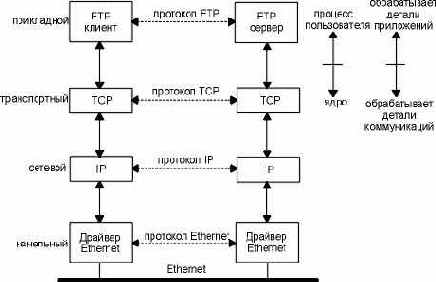
Рисунок 1.2 Два хоста в локальной сети с работающим FTP.
Мы пометили один квадратик на прикладном уровне как FTP клиент, а другой как FTP сервер. Большинство сетевых приложений работают именно таким образом, то есть, на одном конце клиент, а на другом сервер. Сервер предоставляет некоторые типы сервиса клиентам. В данном случае это доступ к файлам на сервере. Telnet предоставляет сервис, позволяющий клиенту зайти на сервер удаленным терминалом.
Каждый уровень имеет один или несколько протоколов, который позволяет общаться с удаленным узлом на том же уровне. Один протокол, например, позволяет общаться двум TCP уровням, а другой протокол обеспечивает коммуникации между двумя IP уровнями.
С правой стороны на рисунке 1.2 мы видим, что прикладной уровень обеспечивается пользовательским процессом, тогда как три нижних уровня обычно встроены в ядро операционной системы. Несмотря на то, что возможны и другие способы реализации, во всех UNIX системах все построено именно по такому принципу.
Существует еще одно отличие между верхним уровнем и тремя нижними уровнями, приведенными на рисунке 1.2. Прикладной уровень обычно является приложением и взаимодействует с пользователем, а не занимается передачей данных по сети. Три нижних уровня ничего не знают о работающих над ними приложениях, однако отвечают за все детали коммуникаций.
На рисунке 1.2 мы показали четыре протокола, каждый на своем уровне. FTP это протокол прикладного уровня, TCP - протокол транспортного уровня, IP - протокол сетевого уровня, а протоколы Ethernet обеспечивают канальный уровень. Семейство протоколов TCP/IP объединяет в себе множество протоколов, однако наиболее часто используемые названия для данного семейства это TCP/IP, TCP и IP (иногда семейство называют Семейство Протоколов Internet).
Цели, решаемые сетевым и прикладным уровнями, различны - первый обеспечивает взаимодействие с различными средами передачи (Ethernet, Token ring, и т.д.), второй работает с конкретными пользовательскими приложениями (FTP, Telnet, и т.д.). На первый взгляд, разница между сетевым и транспортным уровнями достаточно туманна. На основании чего между ними проводится разграничение? Чтобы понять это, мы рассмотрим не одну отдельно взятую сеть, а несколько сетей.
Одной из причин феноменального роста сетевых технологий в течение 80-х годов явилось понимание того, что отдельно стоящий компьютер практически бесполезен. Несколько отдельных систем были объединены вместе в сеть. Однако, как выяснилось позже, а именно в 90-х годах, отдельно стоящая сеть также практически бесполезна. Поэтому люди начали объединять сети вместе. Именно результат такого объединения получил название internet (межсетевое взаимодействие). internet это несколько объединенных сетей, которые используют одно и то же семейство протоколов.
Наиболее простой путь осуществить межсетевое взаимодействие - это объединить две или более сетей с помощью маршрутизатора. Как правило, маршрутизатор представляет из себя аппаратное устройство. Огромное достоинство маршрутизаторов заключается в том, что они могут объединить сети, построенные на различных физических принципах: Ethernet, Token ring, point-to-point, FDDI (Fiber Distributed Data Interface), и так далее.
Эти устройства также иногда называются IP маршрутизаторами (IP router), однако мы будем использовать термин маршрутизатор (router).
Исторически эти устройства назывались шлюзами (gateway), и этот термин до сих пор широко используется в литературе о TCP/IP. Сегодня чаще всего термин шлюз используется для обозначения шлюза между приложениями: процесс, который объединяет два различных семейства протоколов (скажем, TCP/IP и IBM SNA) в одном конкретном приложении (чаще всего это электронная почта или передача файлов).
На рисунке 1.3 показано объединение двух сетей: Ethernet и Token ring с помощью маршрутизатора. Несмотря на то что мы показали связь только между двумя компьютерами, подсоединенными к маршрутизатору из разных сетей, любой компьютер в Ethernet может общаться с любым компьютером в Token ring.
На рисунке 1.3 мы также можем проследить разницу между конечной системой (end system), в данном случае это два компьютера на каждой стороне, и промежуточной системой (intermediate system), в данном случае это маршрутизатор в середине. Прикладной и транспортный уровни используют протоколы, ориентированные на соединение (end-to-end). На рисунке эти два уровня используются только конечными системами. Сетевой уровень, однако, использует протокол, не требующий соединения (пересылка-за-пересылкой - hop-by-hop), он используется в данном случае двумя конечными системами и каждой промежуточной системой.
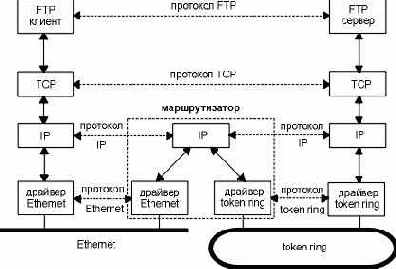
Рисунок 1.3 Две сети, соединенные через маршрутизатор.
В семействе протоколов TCP/IP сетевой уровень - IP. Он предоставляет ненадежный сервис. Это означает, что в процессе своей работы протокол передает пакет от источника к пункту назначения, однако не предоставляет никаких гарантий того, что пакет дойдет по назначению. TCP, с другой стороны, предоставляет надежный транспортный уровень, который пользуется ненадежным сервисом IP. Чтобы обеспечить подобный сервис, TCP выставляет тайм-ауты и осуществляет повторные передачи, отсылает и принимает подтверждения и так далее. Транспортный уровень и сетевой уровень несут различную ответственность за передачу данных.
Маршрутизатор, по определению, имеет два или несколько интерфейсов сетевого уровня (если он объединяет две или более сетей). Любая система с несколькими интерфейсами называется многоинтерфейсной (multihomed). Компьютер, имеющий несколько интерфейсов, но не перенаправляющий пакеты с одного интерфейса на другой, не может называться маршрутизатором. Большинство реализаций TCP/IP позволяют компьютерам с несколькими интерфейсами функционировать в качестве маршрутизаторов. Однако компьютеры должны быть специально сконфигурированы, чтобы решать задачи маршрутизации. Таким образом, мы можем называть систему хостом, когда на нем работают такие приложения как FTP или Telnet, или маршрутизатором, когда он осуществляет передачу пакетов из одной сети в другую. В зависимости от того какие функции выполняются компьютером, мы будем использовать тот или иной термин.
Одна из основных задач объединения сетей заключается в том, чтобы скрыть все детали физического процесса передачи информации между приложениями, находящимися в разных сетях. Поэтому нет ничего удивительного в том, что в объединенных сетях, как, например, на рисунке 1.3, прикладные уровни не заботятся (и не должны заботиться) о том, что один компьютер находится в сети Ethernet, а другой в сети Token ring с маршрутизатором между ними. Даже если бы между сетями было 20 маршрутизаторов и различные типы физического соединения, приложения работали бы точно так же. Подобная концепция, при которой детали физического объединения сетей скрыты от приложений, определяет мощность и гибкость такой технологии объединения сетей.
Существует еще один метод объединения сетей - с помощью мостов (bridge). В этом случае сети объединяются на канальном уровне, тогда как маршрутизаторы объединяют сети на сетевом уровне.
Стоит отметить, что объединение TCP/IP сетей осуществляется в основном с помощью маршрутизаторов, а не с помощью мостов. Поэтому мы более подробно рассмотрим маршрутизаторы. В главе 12 [Perlman 1992] сравниваются маршрутизаторы и мосты.
Уровни TCP/IP
Уровни TCP/IP
В действительности, семейство протоколов TCP/IP объединяет значительно больше протоколов. На рисунке 1.4 показаны некоторые дополнительные протоколы, которые мы рассмотрим в книге.
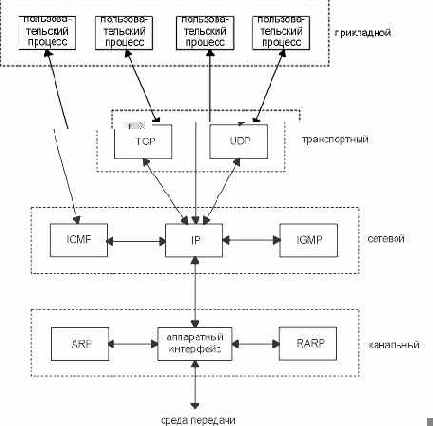
Рисунок 1.4 Различные протоколы на разных уровнях семейства протоколов TCP/IP.
TCP и UDP - два основных протокола транспортного уровня. Оба используют IP в качестве сетевого уровня.
TCP предоставляет надежный транспортный уровень, даже несмотря на то что он использует ненадежный сервис IP. В главах 17, 18, 19, 20, 21 и 22 мы подробно рассмотрим функционирование TCP. Затем мы рассмотрим некоторые приложения TCP: Telnet и Rlogin в главе 26, FTP в главе 27 и SMTP в главе 28. Приложения - это, как правило, пользовательские процессы.
UDP отправляет и принимает датаграммы (datagram). Датаграмма это блок информации (определенное количество байт информации, которое указывается отправителем), который отправляется от отправителя к приемнику. В отличие от TCP, UDP является ненадежным протоколом. Не существует гарантий, что датаграмма достигнет конечной точки назначения. В главе 11 мы рассмотрим UDP, а затем в главе 14 - систему имен доменов (Domain Name System), в главе 15 - простой протокол передачи файлов (Trivial File Transfer Protocol) и в главе 16 - протокол загрузки (Bootstrap Protocol). Это приложения, которые используют UDP. SNMP (Простой протокол управления сетью - Simple Network Management Protocol) также использует UDP, однако он работает с некоторыми другими протоколами, которые мы будем рассматривать вплоть до главы 25.
IP это основной протокол сетевого уровня. Он используется как TCP, так и UDP. Каждый блок информации TCP и UDP, который передается по объединенным сетям, проходит через IP уровень в каждой конечной системе и в каждом промежуточном маршрутизаторе. На рисунке 1.4 показаны приложения, которые имеют прямой доступ к IP. Такой доступ используется довольно редко, но существует возможность его осуществить (некоторые ранние протоколы маршрутизации были разработаны именно подобным образом). Также в процессе экспериментов при создании новых транспортных уровней используется возможность доступа к протоколу IP. В главе 3 рассматривается протокол IP, более подробно IP рассматривается в последующих главах. В главе 9 и главе 10 рассказывают о том как осуществляется IP маршрутизация.
ICMP является дополнением к протоколу IP. Он используется IP уровнем для обмена сообщениями об ошибках и другой жизненно важной информацией уровня IP. Глава 6 рассказывает об ICMP более подробно. Несмотря на то, что ICMP используется в основном IP уровнем, приложения также могут получить доступ к ICMP. Мы рассмотрим два наиболее популярных диагностических средства, Ping и Traceroute (глава 7 и глава 8), использующих ICMP.
Протокол управления группами Internet (IGMP - Internet Groupe Management Protocol), используется при групповой адресации: при этом UDP датаграммы рассылаются нескольким получателям. Мы опишем основные особенности широковещательной адресации (рассылка UDP датаграмм каждому компьютеру в указанной сети) и групповой адресации в главе 12, а затем опишем сам IGMP в главе 13.
Протокол определения адреса (ARP - Address Resolution Protocol) и обратный протокол определения адреса (RARP - Reverse Address Resolution Protocol) это специализированные протоколы, используемые только с определенным типом сетевых интерфейсов (такие как Ethernet и Token ring). Они применяются для преобразования формата адресов, используемого IP уровнем в формат адресов, используемый сетевым интерфейсом. Мы рассмотрим эти протоколы в главе 4 и главе 5 соответственно.
Введение
Введение
Семейство протоколов TCP/IP работает на любых моделях компьютеров, произведенных различными производителями компьютерной техники и работающих под управлением различных операционных систем. С помощью протоколов TCP/IP можно объединить практически любые компьютеры. И что самое удивительное, сегодняшние реализации протокола TCP/IP очень далеки от того, как он задумывался исходно. В конце 60-х годов начался исследовательский проект, финансируемый правительством США, по разработке сети пакетной коммутации, а в 90-х годах результаты этих исследований превратились в наиболее широко используемую форму сетевого взаимодействия между компьютерами. В настоящее время это действительно открытая система, а именно, семейство протоколов и большое количество бесплатных реализаций (либо достаточно дешевых). Они составляют основу того, что в настоящее время называется словом Internet.
В этой главе мы познакомимся с семейством протоколов TCP/IP, для того чтобы подойти к чтению следующих глав более или менее подготовленными. Чтобы познакомиться с ранней историей разработки TCP/IP, можно обратиться к [Lynch 1993].
Зарезервированные порты
Зарезервированные порты
В Unix системах реализуется концепция зарезервированных портов. Только процесс с привилегиями суперпользователя может назначить себе зарезервированный порт.
Эти номера портов находятся в диапазоне от 1 до 1023 и используются некоторыми приложениями (например, Rlogin, глава 26, раздел "Протокол Rlogin") для разграничения прав доступа при общении клиент-сервер.
Ethernet и IEEE 802 инкапсуляция
Ethernet и IEEE 802 инкапсуляция
Термин Ethernet обычно означает стандарт, опубликованный в 1982 году компаниями Digital Equipment Corp., Intel Corp., и Xerox Corp. В настоящее время это основная технология применяемая в локальных сетях использующих TCP/IP. В Ethernet используется метод доступа, называемый CSMA/CD, что обозначает наличие несущей (Carrier Sense), множественный доступ (Multiple Access) с определением коллизий (Collision Detection). Обмен осуществляется со скоростью 10 Мбит/сек, с использованием 48-битных адресов.
Несколько лет спустя Комитет 802 Института инженеров по электротехнике и радиоэлектронике (IEEE - Institute of Electrical and Electronics Engineers) опубликовал отличающийся набор стандартов. 802.3 описывает полный набор сетей CSMA/CD, 802.4 описывает сети с передачей маркера и 802.5 описывает сети Token ring. Общим для всех них является стандарт 802.2, который определяет управление логическим каналом (LLC - Logical link control) и который является общим для большинства сетей 802. К сожалению, комбинация 802.2 и 802.3 определяет форматы фрейма отличные от Ethernet ([Stallings 1987] описывает все детали стандартов IEEE 802).
В мире TCP/IP инкапсуляция IP датаграмм определена в RFC 894 [Hornig 1984] для сетей Ethernet и в RFC 1042 [Postel and Reynolds 1988] для сетей IEEE 802. В Host Requirements RFC к каждому компьютеру, подключенному к Internet через кабель Ethernet 10 Мбит/сек, предъявляются следующие требования: Компьютер должен иметь возможность посылать и получать пакеты, инкапсулированные с использованием RFC 894 (Ethernet). У компьютера должна быть возможность получать пакеты RFC 1042 (IEEE 802), перемешанные с пакетами RFC 894. Компьютер должен иметь возможность посылать пакеты с использованием инкапсуляции RFC 1042. Если компьютер может посылать оба типа пакетов, то тип пакета должен быть конфигурируемым, а конфигурация по умолчанию должна быть настроена на пакеты RFC 894.
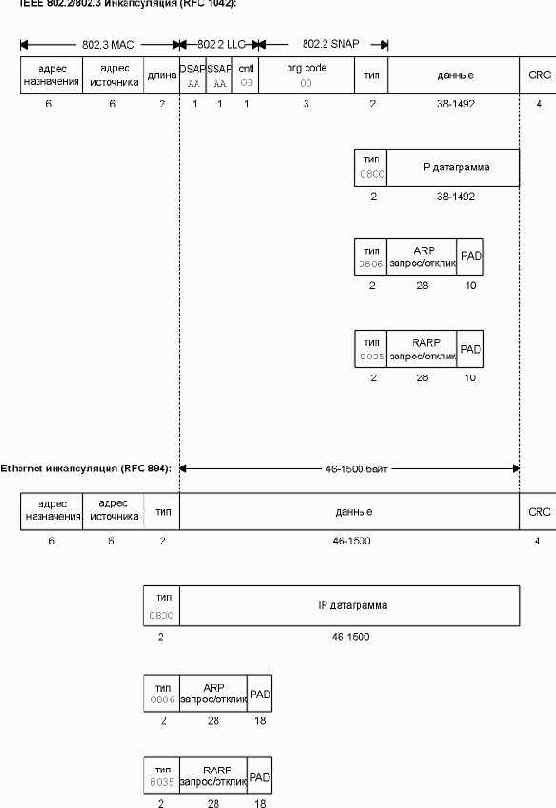
Наиболее широко используется инкапсуляция RFC 894. На рисунке 2.1 показаны два различных метода инкапсуляции. Цифры под каждым квадратиком на рисунке это размер в байтах.
В обоих форматах фрейма используется 48-битовый (6-байтовый) формат представления адресов источника и назначения (802.3 позволяет использование 16-битных адресов, однако обычно используются 48-битные). Это как раз то, что мы называем по тексту аппаратными адресами (hardware addresses). Протоколы ARP и RARP (см. главу 4 и главу 5) устанавливают соответствие между 32-битными IP адресами и 48-битными аппаратными адресами.
Следующие 2 байта в этих форматах фрейма различаются. Поле длины (length) 802 содержит количество следующих за ним байтов, однако не содержит в конце контрольной суммы. Поле тип (type) в Ethernet определяет тип данных, которые следуют за ним. Во фрейме 802 то же поле типа (type) появляется позже в заголовке протокола доступа к подсети (SNAP - Sub-Network Access Protocol). К счастью, величины, находящиеся в поле длины (length) 802, никогда не совпадают с величинами, находящимися в поле типа (type) Ethernet, поэтому эти два формата фрейма легко различимы.
Во фрейме Ethernet данные следуют сразу после поля тип (type), тогда как во фрейме 802 за ним следуют 3 байта LLC 802.2 и 5 байт SNAP 802.2. Поля DSAP (точка доступа к сервису назначения - Destination Service Access Point) и SSAP (точка доступа к сервису источника - Source Service Access Point) оба установлены в 0xAA. Поле ctrl установлено в 3. Следующие 3 байта, org code установлены в 0. Затем идет 2-байтовое поле тип (type), такое же, как мы видели в формате фрейма Ethernet (дополнительные значения, которые могут появиться в поле типа, описаны в RFC 1340 [Reynolds and Postel 1992]).
Поле контрольной суммы (CRC) определяет ошибки, возникшие при транспортировке фрейма (также оно иногда называется FCS или последовательность контроля фрейма - frame check sequence).
Минимальный размер фреймов 802.3 и Ethernet требует, чтобы размер данных был хотя бы 38 байт для 802.3 или 46 байт для Ethernet. Чтобы удовлетворить этому требованию, иногда вставляются байты заполнения, для того чтобы фрейм был соответствующей длины.
Мы еще столкнемся с минимальным размером, когда будем рассматривать движение пакетов по кабелям. Также мы еще не раз обратимся к инкапсуляции Ethernet, потому что это, пожалуй, самая широко распространенная форма инкапсуляции.
Инкапсуляция IEEE 802.2/802.3
Рисунок 2.1 Инкапсуляция IEEE 802.2/802.3 (RFC 1042) и инкапсуляция Ethernet (RFC 894).
Инкапсуляция завершителей
Инкапсуляция завершителей
RFC 893 [Leffler and Karels 1984] описывает другую форму инкапсуляции, которая используется в Ethernet и называется инкапсуляция завершителей (trailer encapsulation). С ранними версиями системы BSD на DEC VAX проводился эксперимент, который должен был увеличить производительность путем изменения порядка полей в IP датаграмме. Поля с переменной длиной, которые находились в начале данных фрейма Ethernet (IP заголовок и TCP заголовок), переносились в конец, сразу после контрольной суммы. Это позволяет данным, находящимся во фрейме, быть спланированными в аппаратную страницу с сохранением копии в памяти, когда данные копируются в ядро. Данные TCP, которые кратны 512 байтам, могут быть перемещены путем манипулирования страницами таблиц ядра. Два компьютера договариваются об использовании инкапсуляции завершителей, пользуясь расширением ARP. Для этих фреймов определены различные значения типа фрейма Ethernet.
В настоящее время инкапсуляция завершителей не применяется, поэтому мы не будем приводить примеров. Читатели, которые интересуются этой темой, могут обратиться к RFC 893 или разделу 11.8 [Leffler et al. 1989] за более подробной информацией.
Интерфейс Loopback
Интерфейс Loopback
Большинство реализаций поддерживают интерфейс loopback, который позволяет клиенту и серверу на одном и том же компьютере общаться друг с другом используя TCP/IP. Для интерфейса loopback зарезервирована сеть класса А с идентификатором 127. По договоренности большинство систем добавляют IP адрес 127.0.0.1 для этого интерфейса и дают ему имя localhost. IP датаграмма, посылаемая в интерфейс loopback, не попадает в сеть.
Мы можем решить, что транспортный уровень распознает, что удаленный адрес - это адрес loopback и каким-либо образом сокращает процесс обработки датаграммы. Однако этого не происходит. Осуществляется полная обработка данных на транспортном и сетевом уровнях, после чего IP датаграмма направляется по петле назад, когда выходит вниз из сетевого уровня. На рисунке 2.4 показана упрощенная диаграмма того, как loopback интерфейс обрабатывает IP датаграммы.
Краткие выводы
Краткие выводы
В этой главе рассматривался самый нижний уровень из семейства протоколов Internet, канальный уровень. Мы рассмотрели различие между Ethernet и IEEE 802.2/802.3 инкапсуляциями, и инкапсуляцию, которая используется в SLIP и PPP. Так как оба SLIP и PPP часто используются на медленных каналах, они предоставляют методы, для сжатия общих полей (которые практически всегда неизменны). При этом улучшается время отклика.
Интерфейс loopback существует в большинстве разработок. Доступ к этому интерфейсу может быть получен через специальный адрес, обычно 127.0.0.1, или путем посылки IP датаграмм на один из собственных IP адресов хоста. Данные, отправленные в loopback интерфейс, полностью обрабатываются транспортным уровнем и IP, когда они проходят по петле по стеку протоколов.
Мы описали важную характеристику большинства канальных уровней, MTU и соответствующую концепцию транспортного MTU. Используя стандартный MTU для последовательных линий, мы вычислили временную задержку, которая существует в каналах SLIP и CSLIP.
В этой главе рассматривается только несколько общих канальных технологий, используемых сегодня в TCP/IP. Одна из причин, по которой TCP/IP успешно используется, это возможность работать поверх практически любых канальных технологий.
MTU
MTU
Как мы видели на рисунке 2.1, существуют ограничения, накладываемые на размер фрейма для Ethernet инкапсуляции и инкапсуляции 802.3. Ограничение накладывается на количество байтов данных в 1500 и 1492 соответственно. Эта характеристика канального уровня называется максимальный блок передачи (MTU - maximum transmission unit). Большинство типов сетей определяют верхний предел.
Если IP хочет отослать датаграмму, которая больше чем MTU канального уровня, осуществляется фрагментация (fragmentation), при этом датаграмма разбивается на меньшие части (фрагменты). Каждый фрагмент должен быть меньше чем MTU. Мы обсудим IP фрагментацию в разделе "Фрагментация IP" главы 11.
На рисунке 2.5 приведен список некоторых типичных значений MTU, взятых из RFC 1191 [Mogul and Deering 1990]. Здесь приведены MTU для каналов точка-точка (таких как SLIP или PPP), однако они не являются физической характеристикой среды передачи. Это логическое ограничение, при соблюдении которого обеспечивается адекватное время отклика при диалоговом использовании. В разделе "Вычисление загруженности последовательной линии" главы 2 мы рассмотрим, откуда берется это ограничение.
В разделе "Команда netstat" главы 3 мы воспользуемся командой netstat, чтобы определить MTU для определенного интерфейса.
| Network | MTU (байты) |
| Hyperchannel | 65535 |
| 16 Мбит/сек Token ring (IBM) | 17914 |
| 4 Мбит/сек Token ring (IEEE 802.5) | 4464 |
| FDDI | 4352 |
| Ethernet | 1500 |
| IEEE 802.3/802.2 | 1492 |
| X.25 | 576 |
| Точка-точка (с маленькой задержкой) | 296 |
Обработка IP датаграмм интерфейсом loopback.
Рисунок 2.4 Обработка IP датаграмм интерфейсом loopback.
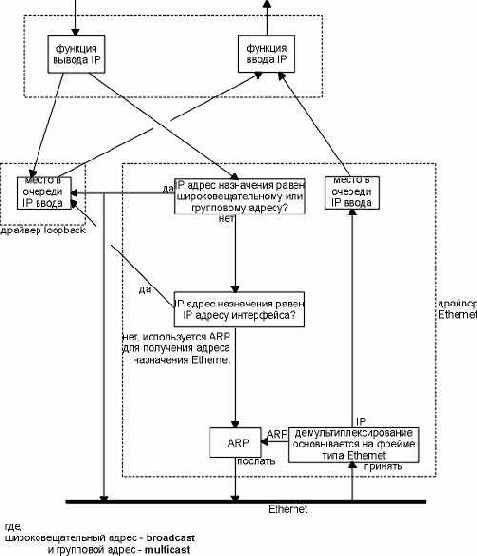
На этом рисунке необходимо обратить внимание на следующее: Все что отправляется на адрес loopback (обычно 127.0.0.1), попадает на вход IP. Датаграммы, отправляемые на широковещательный или групповой адреса, копируются в интерфейс loopback и отправляются в Ethernet. Это осуществляется исходя из определения широковещательной или групповой рассылки (глава 12), которая включает в себя посылающий хост. Все что отправляется на любой из собственных IP адресов хоста, посылается на интерфейс loopback.
Может показаться неэффективным то что транспортный и IP уровни обрабатывают данные, которые посылаются по петле. Однако это упрощает разработку, потому что интерфейс loopback для сетевого уровня выглядит просто как еще один канальный уровень. Сетевой уровень направляет датаграммы в интерфейс loopback как в любой другой канальный уровень, а затем интерфейс loopback помещает датаграммы обратно во входную очередь IP.
Другой интересный момент, который можно увидеть на рисунке 2.4, заключается в том, что IP датаграммы, посланные на один из собственных адресов хоста, обычно не попадают в соответствующую сеть. В комментариях к некоторым BSD драйверам Ethernet устройств указывается, что большинство интерфейсных плат Ethernet не способны читать свою собственную передачу. Так как хост должен обрабатывать IP датаграммы, которые он посылает самому себе, такая обработка пакетов, как показано на рисунке 2.4, это простейший путь добиться этого.
4.4BSD имеет переменную useloopback (по умолчанию устанавливается ее в 1). Если эта переменная установлена в 0, драйвера Ethernet посылают локальные пакеты в сеть, вместо того чтобы посылать их в драйвер loopback. Это может работать, а может и не работать, в зависимости от того, какая установлена интерфейсная плата Ethernet и какой драйвер.
PPP: протокол точка-точка (Point-to-Point)
PPP: протокол точка-точка (Point-to-Point)
PPP, протокол точка-точка, устраняет все недостатки SLIP. PPP состоит из трех компонентов. Способ инкапсуляции IP датаграмм в последовательный канал. PPP поддерживает как асинхронный канал с 8 битами данных без контроля четности (последовательный интерфейс, который присутствует на большинстве компьютеров), так и бит-ориентированный синхронный канал. Протокол управления каналом (LCP - link control protocol) используется для установления конфигурации и тестирования соединения. С его помощью оконечные системы договариваются об использовании различных опций. Семейство протоколов управления сетью (NCP - network control protocol) указывает на различные протоколы сетевого уровня. В настоящее время существует RFC для IP, сетевого уровня OSI, DECnet и Apple Talk. Например, IP NCP позволяет каждой оконечной системе указать, будет ли он использовать сжатие заголовков, такое же как в CSLIP.
RFC 1548 [Simpson 1993] описывает метод инкапсуляции, который будет использоваться в протоколе управления каналом. RFC 1332 [McGregor 1992] описывает протокол управления сетью для IP.
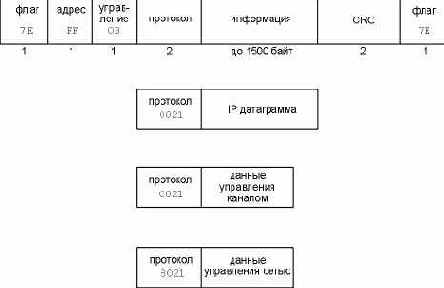
Формат PPP фреймов был выбран таким образом, чтобы напоминать стандарт ISO HDLC (high-level data link control) . На рисунке 2.3 показан формат фреймов PPP.
SLIP: IP по последовательной линии
SLIP: IP по последовательной линии
SLIP - это простая форма инкапсуляции IP датаграмм для последовательной линии, которая описана в RFC 1055 [Romkey 1988]. SLIP стал широко использоваться для подключения домашних систем к Internet с того момента, когда практически на каждом компьютере появился последовательный порт RS-232, а также появились высокоскоростные модемы.
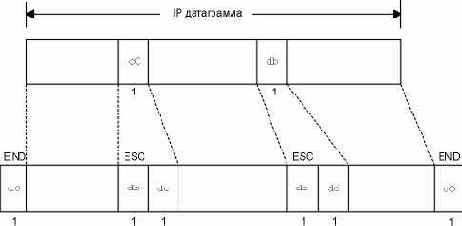
Формирование фреймов с использованием SLIP подчиняется следующим правилам. IP датаграмма завершается специальным символом, который называется END (0xc0). Для того чтобы предотвратить шум в линии, перед тем как датаграмма будет интерпретирована как часть датаграммы, большинство реализаций передают символ END также и в начале датаграммы. (Если на линии есть шум, этот END прекращает передачу ошибочной датаграммы и позволяет текущей датаграмме быть переданной. Ошибочная датаграмма будет отброшена верхним уровнем, когда он определит, что ее содержимое повреждено.) Если байт, находящийся в IP датаграмме, эквивалентен символу END, вместо него передается 2-байтовая последовательность 0xdb, 0xdc. Специальный символ 0xdb называется SLIP ESC символ, однако его значение отличается от символа ASCII ESC (0xlb). Если байт IP датаграммы равен символу SLIP ESC, вместо него передается 2-байтовая последовательность 0xdb, 0xdd.
На рисунке 2.2 показан пример создания подобных фреймов, при этом в исходной IP датаграмме появляются один END символ и один ESC символ. В этом примере количество байт, переданных по последовательной линии, равно длине IP датаграммы плюс 4. SLIP использует довольно простой метод организации фрейма.
Существуют несколько правил, соблюдая которые можно работать со SLIP. Каждая конечная система должна знать противоположный IP адрес. Метода, с помощью которого одна оконечная система может сообщить удаленной системе свой IP адрес, не существует. Не существует поля типа (напоминающего поля типа фрейма в Ethernet). Если последовательная линия используется для SLIP, она не может быть одновременно использована для какого-либо другого протокола. SLIP не добавляет контрольную сумму (как, например, поле контрольной суммы - CRC во фреймах Ethernet). Если из-за шума в телефонной линии датаграмма будет повреждена, это повреждение определяется верхним уровнем. (Однако новые модели модемов могут определять и исправлять испорченные фреймы). Это аналогично тому, как если бы верхние уровни предоставляли некоторую форму контрольной суммы. В главе 3 и главе 17 мы увидим, что контрольная сумма всегда присутствует в IP заголовке, в TCP заголовке и в TCP данных. А в главе 11 мы увидим, что контрольная сумма для заголовка UDP и для данных UDP необязательна.
SLIP с компрессией (CSLIP)
SLIP с компрессией (CSLIP)
Так как линии SLIP как правило медленные (19200 бит/сек или меньше) и часто используют для диалогового трафика (как, например, Telnet и Rlogin, оба из которых используют TCP), возникает необходимость уменьшить TCP пакеты, проходящие по SLIP каналу. Для того чтобы перенести один байт данных, требуется 20 байт IP заголовков и 20 байт TCP заголовков, то есть вместе 40 байт (в разделе "Интерактивный ввод" главы 19 показывается поток этих маленьких пакетов при вводе простых команд в течение сессии Rlogin).
После того как было определено, что с меньшими пакетами достигается большая производительность, новые версии SLIP стали называться CSLIP, что означает сжатый SLIP, который описан в RFC 1044 [Jacobson 1990a]. CSLIP обычно уменьшает 40-байтовый заголовок до 3-5 байт. CSLIP поддерживает до 16 TCP соединений на каждом конце канала и знает, что каждое поле в двух заголовках для данного соединения обычно не изменяется. Для тех полей, которые все же изменяются, изменения заключаются в небольшом увеличении. Подобные уменьшенные заголовки значительно улучшают время отклика при диалоговой работе.
Большинство разработок SLIP в настоящее время поддерживают CSLIP. Оба SLIP канала в подсети, приведенной на рисунке 1.11, являются каналами CSLIP.
Типичные значения максимальных блоков передачи (MTU).
Рисунок 2.5 Типичные значения максимальных блоков передачи (MTU).
Транспортный MTU
Транспортный MTU
Когда общаются два компьютера в одной и той же сети, важным является MTU для этой сети. Однако, когда общаются два компьютера в разных сетях, каждый промежуточный канал может иметь различные MTU. В данном случае важным является не MTU двух сетей, к которым подключены компьютеры, а наименьший MTU любого канала данных, находящегося между двумя компьютерами. Он называется транспортным MTU (path MTU).
Транспортный MTU между любыми двумя хостами может быть не постоянным. MTU зависит от загруженности канала на настоящий момент. Также он зависит от маршрута. Маршрут может быть несимметричным (маршрут от A до B может быть совсем не тем, что маршрут от B к A), поэтому MTU может быть неодинаков для этих двух направлений.
RFC 1191 [Mogul and Deering 1990] описывает механизм определения транспортного MTU (path MTU discovery mechanism). Мы рассмотрим как функционирует этот механизм после того, как опишем фрагментацию ICMP и IP. В разделе "ICMP ошибки о недоступности" главы 11 мы подробно рассмотрим ошибку недоступности ICMP, которая используется в этом механизме, а в разделе "Определение транспортного MTU с использованием Traceroute" главы 11 мы покажем версию программы traceroute, которая использует механизм определения транспортного MTU до пункта назначения. В разделах "Определение транспортного MTU при использовании UDP" главы 11 и "Определение транспортного MTU" главы 24 показано, как функционируют UDP и TCP, когда реализация поддерживает определение MTU.
Упражнения
Упражнения
Если Ваша система поддерживает команду netstat(1) (см. главу 3, раздел "Команда netstat"), используйте ее, чтобы определить интерфейсы в Вашей системе и их MTU. Назад
Компания | Услуги | Для клиентов | Библиотека | Галерея | Cофт | Линки
На главную
Введение
Введение
Из рисунка 1.4 видно, что основная задача канального уровня в семействе протоколов TCP/IP - посылать и принимать (1) IP датаграммы для IP модуля, (2) ARP запросы и отклики для ARP модуля, и (3) RARP запросы и отклики для RARP модуля. TCP/IP поддерживает различные канальные уровни, в зависимости от того какой тип сетевого аппаратного обеспечения используется: Ethernet, Token ring, FDDI (Fiber Distributed Data Interface), последовательные линии RS-232, и так далее.
В этой главе мы подробно рассмотрим канальный уровень Ethernet, два специализированных канальных уровня для последовательных интерфейсов (SLIP и PPP) и драйвер loopback, который присутствует практически во всех реализациях. Ethernet и SLIP это канальные уровни, используемые для большинства примеров в данной книге. Также мы рассмотрим максимальный блок передачи (MTU - Maximum Transmission Unit), который является характеристикой канального уровня и к которой мы обращаемся много раз в этой главе и в следующих. Также мы покажем некоторые расчеты, с помощью которых можно выбрать MTU для последовательной линии.
Вычисление загруженности последовательной линии
Вычисление загруженности последовательной линии
Если скорость в линии составляет 9600 бит/сек, при этом 1 байт составляет 8 бит плюс 1 старт-бит и 1 стоп-бит, скорость линии будет 960 байт/сек. Передача пакета размером 1024 байта с этой скоростью займет 1066 мс. Если мы используем SLIP канал для диалогового приложения и одновременно с ним работает такое приложение как FTP, которое посылает или принимает пакеты по 1024 байт, мы должны ждать, так как среднее время задержки нашего интерактивного пакета составит 533 мс.
Это означает, что наш диалоговый пакет будет послан по каналу перед любым другим "большим" пакетом. Большинство SLIP приложений предоставляют разделение пакетов по типу сервиса, отправляя диалоговый трафик перед трафиком передачи данных. Диалоговый трафик это, как правило, Telnet, Rlogin и управляющая часть (пользовательские команды, но не данные) FTP.
Естественно, что такое разделение по сервисам несовершенно. Оно не оказывает никакого воздействия на неинтерактивный трафик, который уже поставлен в очередь на передачу (например, последовательным драйвером). Новые модели модемов, которые имеют большие буферы и позволяют сбуферизировать неинтерактивный трафик в буфере модема, что также сказывается на задержке диалогового трафика.
Ожидание в 533 мс неприемлемо для диалогового ответа. С точки зрения человеческого фактора мы знаем, что неприемлемой является задержка дольше чем 100-200 мс [Jacobson 1990a]. Под задержкой подразумевается время между отправкой пакета и возвращением отклика (как правило, эхо символа).
Уменьшение MTU в канале SLIP до 256 означает, что максимальное время, в течение которого канал может быть занят одним фреймом, составляет 266 мс, и половина от этого (наше среднее время ожидания) составляет 133 мс. Это лучше, однако до сих пор не идеально. Причина, по которой мы выбрали это значение (как сравниваются 64 и 128), заключается в том, чтобы обеспечить лучшее использование канала для передачи данных (как, например, при передаче большого файла). В случае CSLIP фрейма размером 261 байт с заголовком размером в 5 байт (256 байт данных), 98,1% линии используются для передачи данных и 1,9% на заголовки. Уменьшение MTU меньше чем 256 уменьшает максимальное значение пропускной способности линии, которую мы можем получить при передаче данных.
Значение MTU равное 296 для канала точка-точка (рисунок 2.5), подразумевает 256 байт данных и 40 байт TCP и IP заголовков. Так как MTU это величина, о которой IP узнает от канального уровня, это значение должно включать в себя стандартные заголовки TCP и IP. Именно таким образом IP принимает решение о фрагментации. IP ничего не знает о сжатии заголовков, которое осуществляются CSLIP.
Наш расчет средней задержки (половина того времени, которое требуется на передачу фрейма максимального размера) имеет отношение только к каналу SLIP (или каналу PPP), который используется для передачи интерактивного трафика и трафика данных. Когда идет обмен только интерактивным трафиком, время передачи одного байта данных в каждом направлении (в случае сжатого 5-байтового заголовка) составляет примерно 12,5 мс, при скорости 9600 бит/сек. Это хорошо укладывается в диапазон 100-200 мс, о котором мы упоминали ранее. Также заметьте, что сжатие заголовков с 40 до 5 байт уменьшает время задержки для одного байта с 85 до 12,5 мс.
К сожалению, эти расчеты становятся не совсем верными, когда используется коррекция ошибок и сжатие в модемах. Сжатие в модемах уменьшает количество байт, которые посылаются по линии, однако исправление ошибок может увеличить время передачи этих байт. Однако эти расчеты дают нам исходную точку, для того чтобы принять разумное решение.
В следующих главах мы будем использовать эти расчеты для последовательных линий, чтобы определить некоторые величины таймеров, которые используются при передаче пакетов по последовательным линиям.
Адресация подсетей
Адресация подсетей
В настоящее время существует требование, чтобы все хосты поддерживали адресацию подсетей (RFC 950 [Mogul and Postel 1985]). Теперь IP адрес не делится просто на идентификатор сети и идентификатор хоста: идентификатор хоста делится на идентификатор подсети и идентификатор хоста.
В сетях класса A и в сетях класса B адреса отводится слишком много бит на идентификатор хоста: 224 - 2 и 216 - 2 соответственно. Как правило, такое количество хостов не подключается к одной сети. (На рисунке 1.5 показан формат IP адресов сетей различных классов сетей.) В данном случае вычитается 2, потому что идентификатор хоста из всех нулевых битов или всех единичных битов не используется.
После получения от InterNIC идентификатора сети определенного класса, системный администратор решает, делить ли сеть на подсети или нет, а если делить, то сколько бит будет отведено на идентификатор подсети и сколько на идентификатор хоста. Например, сети, описываемые в этом тексте, имеют адреса класса В (140.252), а из оставшихся 16 бит 8 отводятся под идентификатор подсети, а 8 на идентификатор хоста. Это показано на рисунке 3.5.
Будущее IP
Будущее IP
У IP существуют три проблемы. Все они явились результатом феноменального роста сети Internet за последние несколько лет. (Обратитесь к упражнению 2 главы 1.) Почти половина всех адресов класса В уже распределена. Если адреса класса В будут распространяться с такой же скоростью как сейчас, то их запас будет исчерпан где-то в 1995 году. 32-битные адреса в общем случае непригодны для долговременного роста Internet. Текущая структура маршрутизации не иерархическая, а плоская, при этом на каждую сеть требуется запись в таблицы маршрутизации. По мере роста количества сетей все более распространяются адреса класса С, а также узлы, в которых сосредоточено несколько сетей (вместо адреса класса В), при этом заметен рост таблиц маршрутизации.
Бесклассовая маршрутизация между доменами (CIDR - Classless Interdomain Routing) призвана разрешить третью проблему, при этом к текущей версии IP будут добавлены некоторые расширения (IP версия 4). Мы обсудим это более подробно в разделе "CIDR: бесклассовая маршрутизация между доменами" главы 10.
Что касается новой версии IP, которую часто называют IPng, было сделано четыре предложения для следующих поколений IP. В майском выпуске IEEE Network (vol.7, no.3) за 1993 год содержится обзор первых трех предложений вместе с CIDR. RFC 1454 [Dixon 1993] также сравнивает первые три предложения. Простой протокол Internet (SIP - Simple Internet Protocol) . Предлагается минимальный набор изменений к IP, после чего IP будет использовать 64-битные адреса и другой формат заголовка. (Первые 4 бита заголовка также содержат номер версии, которые устанавливается в 4.) PIP. Здесь также используются большие, переменной длины, иерархические адреса с другим форматом заголовка. TUBA, что означает TCP и UDP с увеличенными адресами (TCP and UDP with bigger Addresses), основан на OSI CLNP (сетевой протокол без соединения - Connectionless Network Protocol), протокол OSI похожий на IP. Он предлагает еще большие адреса: переменной длины, до 20 байт. Однако, СLNP это существующий протокол, тогда как SIP и PIP это всего лишь предложения, более того, CLNP уже документирован. RFC 1347 [Callon 1992] описывает детали TUBA. Глава 7 [Perlman 1992] содержит сравнение IPv4 и CLNP. Множество маршрутизаторов уже поддерживают CLNP, однако большинство хостов не поддерживают. TP/IX, который описан в RFC 1475 [Ullmann 1993]. Как и в случае с SIP, он использует 64-битные IP адреса, также изменяя TCP и UDP заголовки: 32-битный номер порта для обоих протоколов, 64-битный номер последовательности, 64-битный номер подтверждения и 32-битные окна для TCP.
Первые три предложения используют в основном те же версии TCP и UDP в качестве транспортных уровней. Однако только одно из этих четырех предложений было выбрано в качестве основы для IPv4. Вполне возможно, что в тот момент, когда Вы читаете эти строки, решение принимается или уже принято, поэтому мы ничего не будем говорить об этом более. Однако, надо сказать, что пройдет еще много времени, прежде чем IPv4 станет действительно реальным протоколом.
Доставка IP датаграммы от bsdi к sun.
Рисунок 3.3 Доставка IP датаграммы от bsdi к sun.
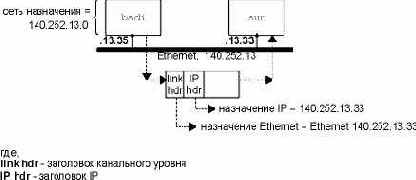
Рассмотрим еще один пример: bsdi имеет IP датаграмму, которую необходимо послать на хост ftp.uu.net, IP адрес которого 192.48.96.9. На рисунке 3.4 показан путь датаграммы через первые три маршрутизатора. bsdi просматривает свою таблицу маршрутизации, однако не находит совпадающий хост или совпадающую сеть. Он использует пункт таблицы маршрутизации по умолчанию, в соответствии с которым необходимо послать датаграмму на sun, который является маршрутизатором следующей пересылки. Когда датаграмма передается от bsdi к sun, IP адрес для нее это конечный адрес назначения (192.48.96.9), однако адрес канального уровня - это 48-битный Ethernet адрес интерфейса Ethernet машины sun. Сравните эту датаграмму с одной из показанных на рисунке 3.3, где IP адрес назначения и адрес назначения канального уровня указывают на один и тот же хост (sun).
Когда sun получает датаграмму, он понимает, что IP адрес назначения этой датаграммы не его собственный, и если sun сконфигурирован для того чтобы выполнять функции маршрутизатора, он перенаправляет датаграмму. Происходит просмотр его таблицы маршрутизации, в результате чего выбирается пункт по умолчанию. Из этого пункта следует, что sun должен перенаправить датаграмму на маршрутизатор следующей пересылки - netb, IP адрес которого 140.252.1.183. Датаграмма пересылается по SLIP каналу точка-точка с использованием минимальной инкапсуляции, показанной на рисунке 2.2. Мы не показываем заголовок канального уровня, как в случае с Ethernet, потому что его нет в случае SLIP канала.
Когда netb получает датаграмму, он осуществляет те же самые шаги, которые только что осуществил sun: датаграмма не предназначается какому-либо из его IP адресов, а так как netb сконфигурирован так, чтобы выполнять функции маршрутизатора, он перенаправляет датаграмму. В данном случае также используется пункт таблицы маршрутизации по умолчанию, при этом датаграмма посылается на маршрутизатор следующей пересылки gateway (140.252.1.4). С использованием ARP в сети Ethernet 140.252.1, netb получает 48-битный Ethernet адрес соответствующий адресу 140.252.1.4. Именно этот Ethernet адрес становится адресом назначения в заголовке канального уровня.
gateway осуществляет те же шаги, как и два предыдущих маршрутизатора, в его таблице маршрутизации пункт по умолчанию указывает на адрес 140.252.104.2 как на адрес маршрутизатора следующей пересылки (мы убедимся, что этот маршрутизатор является маршрутизатором следующей пересылки для gateway с использованием Traceroute на рисунке 8.4).
Из приведенного примера можно сделать несколько важных выводов. Все хосты и маршрутизаторы в данном примере используют маршрут по умолчанию. IP адрес назначения датаграммы никогда не меняется. (В разделе "Опция IP маршрутизации от источника" главы 8 мы увидим, что это не всегда верно, если используется маршрутизация от источника, что бывает довольно редко.) Все решения о маршрутизации основываются на этом адресе назначения. Для каждого канала могут быть использованы различные заголовки канального уровня, а адрес назначения канального уровня (если присутствует) всегда содержит адрес маршрутизатора следующей пересылки. В нашем примере датаграммы, инкапсулированные во фреймы канального уровня, содержали Ethernet адрес следующей пересылки, однако SLIP не содержал. Адреса Ethernet обычно получаются с использованием ARP.
IP адреса описываемой подсети.
Рисунок 3.12 IP адреса описываемой подсети.
Первая колонка помечена как "хост" ("Host"), однако и sun и bsdi также функционируют как маршрутизаторы, так как они имеют несколько интерфейсов и перенаправляют пакеты с одного интерфейса на другой.
В последней строке таблицы показано, что широковещательный адрес сети Ethernet на рисунке 3.10 установлен 140.252.13.63: он формируется из идентификатора подсети Ethernet (140.252.13.32) и младших 5 бит на рисунке 3.11, установленных в единицу (16+8+4+2+1=31). (В главе 12 мы увидим, что этот адрес называется широковещательным адресом подсети.)
IP маршрутизация
IP маршрутизация
IP маршрутизация это довольно простой процесс, особенно с точки зрения хоста. Если пункт назначения напрямую подключен к хосту (например канал точка-точка) или хост включен между несколькими сетями (Ethernet или Token ring), IP датаграмма направляется непосредственно в пункт назначения, иначе хост посылает датаграмму на маршрутизатор по умолчанию, тем самым предоставляя маршрутизатору решать как доставить датаграмму в пункт назначения. Эту простую схему реализуют практически все хосты.
В этом разделе и в главе 9 мы рассмотрим наиболее общие случаи, когда IP уровень может быть сконфигурирован таким образом, чтобы выполнять функции маршрутизации, в дополнение к тому, что он работает в качестве сетевого интерфейса. Большинство многопользовательских систем в настоящее время, включая практически каждую UNIX систему, могут быть сконфигурированы таким образом, чтобы выступать в роли маршрутизатора. Существует возможность указать простой алгоритм маршрутизации, который будет использоваться как хостом, так и маршрутизатором. Основная и фундаментальная разница между хостом и маршрутизатором заключается в том, что хост никогда не перенаправляет датаграммы с одного своего интерфейса на другой, тогда как маршрутизатор перенаправляет. Мы рассмотрим более подробно опции конфигурирования в разделе "Перенаправлять или не перенаправлять" главы 9.
В соответствии с общей схемой, IP может получать датаграммы от собственных уровней TCP, UDP, ICMP и IGMP (это датаграммы, формирующиеся здесь же), которые необходимо отправить, однако датаграммы могут быть приняты с какого-либо сетевого интерфейса (эти датаграммы должны быть перенаправлены). IP уровень имеет в памяти таблицу маршрутизации, которую он просматривает каждый раз при получении датаграммы, которую необходимо перенаправить. Когда датаграмма принята с сетевого интерфейса, IP, во-первых, проверяет, не принадлежит ли ему указанный IP адрес назначения или не является ли этот IP адрес широковещательным. Если это так, то датаграмма доставляется в модуль протокола, указанный в поле протокола в IP заголовке. Если датаграмма не предназначается для этого IP уровня (1), если IP уровень был сконфигурирован для того чтобы работать как маршрутизатор, пакет перенаправляется (в этом случае датаграмма обрабатывается как исходящая, что будет описано ниже), иначе (2) датаграмма молча уничтожается.
Каждый пункт таблицы маршрутизации содержит следующую информацию: IP адрес назначения. Это может быть как полный адрес хоста (host address) или адрес сети (network address), что указывается в поле флагов (описывается ниже). Адрес хоста имеет ненулевое значение идентификатора хоста (рисунок 1.5) и указывает на один конкретный хост, тогда как адрес сети имеет идентификатор хоста, установленный в 0, и указывает на все хосты, включенные в определенную сеть (Ethernet, Token ring). IP адрес маршрутизатора следующей пересылки (next-hop router), или, иначе говоря, IP адрес непосредственно подключенной сети. Маршрутизатор следующей пересылки принадлежит одной из непосредственно подключенных сетей, в которую мы можем отправить датаграммы для их доставки. Маршрутизатор следующей пересылки это не конечный пункт назначения, однако он принимает датаграммы, которые мы посылаем, и перенаправляет их в направлении конечного пункта. Флаги. Один флаг указывает, является ли IP адрес пункта назначения, адресом сети или адресом хоста. Другой флаг указывает на то, является ли маршрутизатор следующей пересылки действительно маршрутизатором или это непосредственно подключенный интерфейс (мы опишем эти флаги в разделе "Принципы маршрутизации" главы 9). Указание на то, на какой сетевой интерфейс должны быть переданы датаграммы для передачи.
IP маршрутизация осуществляется по принципу пересылка-за-пересылкой. Как мы можем увидеть из таблицы маршрутизации, IP не знает полный маршрут к пункту назначения (за исключением тех пунктов назначения, которые непосредственно подключены к посылающему хосту). Все что может предоставить IP маршрутизация - это IP адрес маршрутизатора следующей пересылки, на который посылается датаграмма. При этом делается предположение, что маршрутизатор следующей пересылки ближе к пункту назначения, чем посылающий хост. Также делается предположение, что маршрутизатор следующей пересылки напрямую подключен к посылающему хосту.
IP маршрутизация осуществляет следующие действия: Осуществляется поиск в таблице маршрутизации, при этом ищется пункт, который совпадет с полным адресом пункта назначения (должен совпасть идентификатор сети и идентификатор хоста). Если пункт найден в таблице маршрутизации, пакет посылается на указанный маршрутизатор следующей пересылки или на непосредственно подключенный интерфейс (в зависимости от поля флагов). Как правило, так определяются каналы точка-точка, при этом другой конец такого канала, как правило, является полным IP адресом удаленного хоста. Осуществляется поиск в таблице маршрутизации пункта, который совпадет, как минимум, с идентификатором сети назначения. Если пункт найден, пакет посылается на указанный маршрутизатор следующей пересылки или на непосредственно подключенный интерфейс (в зависимости от поля флагов). Маршрутизация ко всем хостам, находящимся в сети назначения, осуществляется с использованием этого единственного пункта таблицы маршрутизации. Например, все хосты локальной сети Ethernet представляются в таблицах маршрутизации именно таким образом. Эта проверка совпадения идентификатора сети осуществляется с использованием возможной маски подсети, которую мы опишем в следующем разделе. В таблице маршрутизации ищется пункт, помеченный "по умолчанию" (default). Если пункт найден, пакет отсылается на указанный маршрутизатор по умолчанию.
Если ни один из шагов не дал положительного результата, датаграмма считается недоставленной. Если недоставленная датаграмма была сгенерирована данным хостом, то обычно возвращается ошибка "хост недоступен" (host unreachable) или "сеть недоступна" (network unreachable). Этот код ошибки возвращается приложению, которое сгенерировало датаграмму.
В начале всегда осуществляется сравнение на совпадение полного адреса хоста, после чего осуществляется сравнение идентификатора сети. Только в том случае, если результат обеих сравнений отрицательный, используется маршрут по умолчанию. Маршруты по умолчанию и сообщения ICMP о перенаправлении, отправляемые на маршрутизатор следующей пересылки (если для датаграммы выбрано неверное направление по умолчанию), являются довольно мощными характеристиками IP маршрутизации, к которым мы еще вернемся в главе 9.
Еще одна фундаментальная характеристика IP маршрутизации заключается в возможности указать маршрут к сети, вместо того, чтобы указывать маршрут к каждому отдельно взятому хосту. Именно поэтому хосты включенные в Internet, например, имеют в своих таблицах маршрутизации тысячи пунктов, вместо того чтобы содержать в них не более чем миллион пунктов.
IP заголовок
IP заголовок
На рисунке 3.1 показан формат IP датаграммы. Стандартный размер IP заголовка составляет 20 байт, если не присутствуют опции.
Использование подсетей переменной длины.
Рисунок 3.11 Использование подсетей переменной длины.

Маска подсети с переменной длиной не создаст проблем для других хостов и маршрутизаторов в сети 140.252, так как все датаграммы, направляемые в подсеть 140.252.13, приходят на маршрутизатор sun (IP адрес 140.252.1.29. Рисунок 3.10) и если sun знает об 11-битном идентификаторе подсети для хостов в подсети 13, все будет нормально.
Маска подсети для всех интерфейсов в подсети 140.252.13 установлена в 255.255.255.224 или 0xffffffe0. Это означает, что крайние правые 5 битов отводятся на идентификатор хоста, а 27 бит слева оставлены на идентификатор сети и идентификатор подсети.
На рисунке 3.12 показано распределение IP адресов и масок подсетей для интерфейсов, приведенных на рисунке 3.10.
| Хост | IP адрес | Маска подсети | ID сети/ ID подсети | ID хоста | Комментарии |
| sun | 140.252.1.29 | 255.255.255.0 | 140.252.1. | 29 | в подсети 1 |
| 140.252.13.33 | 255.255.255.244 | 140.252.13.32 | 1 | Ethernet, который рассматривается в качестве примера | |
| svr4 | 140.252.13.34 | 255.255.255.244 | 140.252.13.32 | 2 | |
| bsdi | 140.252.13.35 | 255.255.255.244 | 140.252.13.32 | 3 | Ethernet |
| 140.252.13.66 | 255.255.255.244 | 140.252.13.64 | 2 | точка-точка | |
| slip | 140.252.13.65 | 255.255.255.244 | 140.252.13.64 | 1 | точка-точка |
| 140.252.13.63 | 255.255.255.224 | 140.252.13.32 | 31 | широковещательный адрес в Ethernet |
Команда ifconfig
Команда ifconfig
Сейчас, когда мы описали канальный уровень и IP уровень, мы можем показать команду, которая используется для конфигурирования сетевого интерфейса который используется TCP/IP. Команда ifconfig(8) обычно запускается в момент загрузки хоста при конфигурации каждого интерфейса.
Для интерфейсов с дозвоном (dialup), которые могут включаться и выключаться (такие как SLIP каналы), ifconfig должна быть запущена каждый раз когда канал включается или выключается.
В следующем примере показаны значения для подсети, описываемой в книге. Сравните эти значения с теми, что приведены на рисунке 3.12.
sun % /usr/etc/ifconfig -a опция -a в SunOS означает "все интерфейсы" le0: flags=63<UP,BROADCAST, NOTRAILERS, RUNNING> inet 140.252.13.33 netmask ffffffe0 broadcast 140.252.13.63 sl0: flags=1051<UP, POINTOPOINT, RUNNING, LINK0> inet 140.252.1.29 --> 140.252.1.183 netmask ffffff00 lo0: flags=49<UP, LOOPBACK, RUNNING> inet 127.0.0.1 netmask ff000000
Интерфейс loopback (глава 2, раздел "Интерфейс Loopback") воспринимается как сетевой интерфейс. Он использует адрес класса A и не позволяет разбивать себя на подсети.
Обратите внимание на то, что в Ethernet не используется инкапсуляция завершителей (глава 2, раздел "Инкапсуляция завершителей") и что Ethernet поддерживает широковещательные запросы, тогда как SLIP канал это канал точка-точка.
Флаг LINK0 для SLIP интерфейса это опция конфигурирования, которая позволяет осуществлять сжатие slip (CSLIP, глава 2, раздел "SLIP с компрессией (CSLIP)"). Еще одна возможная опция это LINK1, которая включает CSLIP, если принят сжатый пакет с удаленного конца, и LINK2, которая позволяет отбрасывать все исходящие пакеты ICMP. Мы рассмотрим адрес назначения этого SLIP канала в разделе "Уполномоченный агент ARP" главы 4.
Комментарии, приведенные в инструкции по инсталляции, объясняют причину, по которой была введена последняя опция: "Она не должна быть установлена, однако некоторые кретины, посылающие pingи на Вас, могут свести производительность канала к нулю".
Еще один маршрутизатор - bsdi. Так как опция -a это характеристика SunOS, (BSD релизы не имеют подобной опции) мы должны исполнить ifconfig несколько раз, указывая имя интерфейса в качестве аргумента:
bsdi % /sbin/ifconfig we0 we0: flags=863<UP, BROADCAST, NOTRAILERS, RUNNING, SIMPLEX> inet 140.252.13.35 netmask ffffff00 broadcast 140.252.13.63 bsdi % /sbin/ifconfig sl0 sl0: flags=1011<UP, POINTOPOINT, LINK0> inet 140.252.13.66 --> 140.252.13.65 netmask ffffff00
Здесь у интерфейса Ethernet мы видим новую опцию (we0): SIMPLEX. Эта опция из 4.4BSD, которая указывает на то, что интерфейс не может слушать свою собственную передачу. Она устанавливается в BSD/386 для всех интерфейсов Ethernet. Если опция установлена, интерфейс, посылающий фрейм с широковещательным адресом, посылает копию на локальный хост и посылает копию на loopback. (Мы покажем пример данной характеристики в разделе "ICMP запрос и отклик маски адреса" главы 6.)
На хосте slip конфигурация интерфейса SLIP примерно такая же, как показано выше для bsdi, за исключением того, что IP адреса на двух концах переставлены местами:
slip % /sbin/ifconfig sl0 sl0: flags=1011<UP, POINTOPOINT, LINK0> inet 140.252.13.65 --> 140.252.13.66 netmask ffffffe0
Последний интерфейс - это Ethernet на хосте svr4. Он аналогичен интерфейсу Ethernet, показанному ранее, за исключением того, что версия команды ifconfig в SVR4 не печатает флаг RUNNING:
svr4 % /usr/sbin/ifconfig emd0 emd0: flags=23<UP, BROADCAST, NOTRAILERS> inet 140.252.13.34 netmask ffffffe0 broadcast 140.252.13.63
Команда ifconfig обычно поддерживает и другие семейства протоколов (не TCP/IP), а также имеет несколько дополнительных опций. Обратитесь к руководству по вашей системе, для того чтобы изучить эту команду более подробно.
Команда netstat
Команда netstat
Команда netstat(1) также предоставляет информацию об интерфейсах системы. Флаг -i выдает информацию об интерфейсах, а флаг -n выдает IP адреса вместо имен хостов.
sun % netstat -in Name Mtu Net/Dest Address Ipkts Ierrs Opkts Oerrs Collis Queue le0 1500 140.252.13.32 140.252.13.33 67719 0 92133 0 1 0 sl0 552 140.252.1.183 140.252.1.29 48035 0 54963 0 0 0 lo0 1536 127.0.0.1 127.0.0.1 15548 0 15548 0 0 0
Эта команда печатает MTU для каждого интерфейса, количество входящих пакетов, ошибки ввода, количество исходящих пакетов, ошибки вывода, коллизии (столкновения) и текущий размер исходящей очереди.
Мы вернемся к команде netstat в главе 9, где будем использовать ее для рассмотрения таблиц маршрутизации, и в главе 13, когда будем использовать модифицированную версию команды, чтобы рассмотреть активные группы при групповой адресации.
Краткие выводы
Краткие выводы
Мы начали эту главу с описания IP заголовка, кратко описав все поля. Также было сделано введение в маршрутизацию IP, был рассмотрен простой роутинг: мы рассмотрели, как выбирается непосредственно подключенная сеть или маршрутизатор по умолчанию.
Хосты и маршрутизаторы имеют таблицы маршрутизации, которые используются для принятия решений о маршрутизации. В этой таблице присутствует три типа маршрутов: указанный хост, указанная сеть и необязательный маршрут по умолчанию. Для этих маршрутов существует система приоритетов. Наивысший приоритет имеет маршрут к хосту, затем маршрут к сети, и, наконец, маршрут по умолчанию используется только тогда, когда не существует других маршрутов.
IP маршрутизация осуществляется по принципу пересылка-за-пересылкой (hop-by-hop). IP адрес назначения никогда не меняется в процессе передачи датаграммы по пересылкам, однако инкапсуляция и адреса назначения канального уровня могут изменяться при каждой пересылке. Большинство хостов и многие маршрутизаторы используют маршрутизатор следующей пересылки по умолчанию для всего внешнего траффика.
Адреса сетей класса А и класса В обычно разбиваются на подсети. Количество бит, используемых для идентификатора подсети, указывается с помощью маски подсети. Мы привели подробные примеры того как это делается с использованием подсети, которая описывается в этой книге, и немного рассказали о подсетях с переменной длиной. Мы использовали разбиение на подсети, для того чтобы уменьшить размер таблиц маршрутизации, так как ко множеству сетей можно получить доступ через одну точку. Информация об интерфейсах и сетях может быть получена с использованием команд ifconfig и netstat. Они включают в себя IP адреса интерфейсов, их маски подсетей, широковещательные адреса и MTU.
Мы закончили главу, описав возможные изменения, которые могут произойти в протоколах Internet при появлении следующего поколения IP.
Маска подсети
Маска подсети
В процессе конфигурации, которая происходит в момент загрузки хоста, осуществляется установка IP адреса хоста. Большинство систем хранят его в дисковом файле, который читается во время загрузки. В главе 5 мы рассмотрим, как бездисковые системы определяют свой IP адрес при загрузке.
В дополнение к IP адресу, хосту также необходимо знать, сколько бит будет использовано в качестве идентификатора подсети и сколько бит будет использовано в качестве идентификатора хоста. Это также определяется во время загрузки с использованием маски подсети. Маска это 32-битное значение, которое содержит биты, установленные в единицу для идентификатора сети и идентификатора подсети, и биты, установленные в 0 для идентификатора хоста. На рисунке 3.7 показано формирование маски подсети для двух различных разделений адреса класса В. В верхнем примере происходит разделение на хосте noao.edu, как показано на рисунке 3.5, где идентификатор подсети и идентификатор хоста занимают 8 бит. В нижнем примере показано разделение адреса класса В, при этом идентификатор подсети занимает 10 бит, а идентификатор хоста - 6 бит.
Настройки большинства подсетей noao.edu 140.252.
Рисунок 3.6 Настройки большинства подсетей noao.edu 140.252.
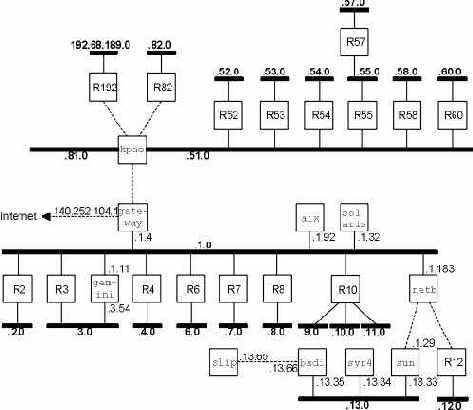
Для того чтобы получить доступ к хосту, IP адрес которого начинается с 140.252, внешний маршрутизатор должен всего лишь знать путь к IP адресу 140.252.104.1. Это означает, что для доступа ко всем сетям 140.252 необходим только один пункт в таблице маршрутизации, вместо 30-ти пунктов в случае использования 30 адресов класса С. Таким образом, деление на подсети уменьшает размер таблиц маршрутизации (в разделе "CIDR: бесклассовая маршрутизация между доменами" главы 10 мы рассмотрим новую технологию, которая помогает уменьшить размер таблиц маршрутизации даже если используются адреса класса С).
Для того чтобы показать что подсети непрозрачны для маршрутизаторов внутри подсети, обратимся к рисунку 3.6 и представим, что датаграмма прибывает в gateway из Internet с адресом назначения 140.252.57.1. Маршрутизатор gateway должен знать где находится подсеть 57 и что датаграммы для этой подсети надо посылать в kpno. В свою очередь, kpno должен посылать датаграммы в R55, который пошлет их в R57.
Настройки хостов и сетей в описываемой подсети.
Рисунок 3.10 Настройки хостов и сетей в описываемой подсети.
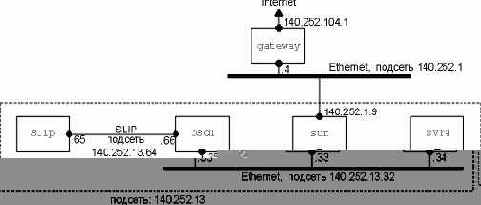
Если Вы сравните этот рисунок с одним из тех, что показаны на внутренней стороне обложки, то заметите, что мы опустили некоторые детали, которые описывают подсоединение маршрутизатора sun к верхнему Ethernet. (посредством SLIP соединения). Это не влияют на наше описание деления на подсети в данном разделе. Мы вернемся к подобному SLIP соединению в разделе "Уполномоченный агент ARP" главы 4, когда будем описывать уполномоченного агента ARP.
Проблема заключается в том, что мы имеем две раздельные сети внутри подсети 13: Ethernet и канал точка-точка (выделенный канал SLIP). (Каналы точка-точка всегда привносят некоторые проблемы, так как каждый конец требует собственный IP адрес.) В будущем здесь может появиться больше хостов и сетей, однако недостаточно для того, чтобы выделять другой номер подсети. Мы принимаем решение расширить идентификатор подсети с 8 до 11 бит, и уменьшить идентификатор хоста с 8 до 5 бит. Это называется подсетями с переменной длиной, так как большинство сетей внутри сети 140.252 используют маску подсети длиной 8 бит, тогда как наша сеть использует маску подсети длиной 11 бит.
RFC 1009 [Braden and Postel 1987] позволяет использовать в сетях с подсетями несколько масок подсетей. Новые требования к маршрутизаторам Router Requirements RFC [Almquist 1993] определяют все требования. Проблема, однако, заключается в том, что не все протоколы маршрутизации обмениваются масками подсети вместе с идентификатором сети назначения. Мы увидим в главе 10, что RIP не поддерживает подсети переменной длины, однако RIP версии 2 и OSPF поддерживают. У нас не было подобных проблем, так как RIP не используется в подсетях, описываемых в тексте.
На рисунке 3.11 показана структура IP адреса, используемая в подсети, описываемой в книге. Первые 8 бит в 11-битном идентификаторе подсети всегда равны 13 в данной подсети. Для оставшихся трех бит идентификатора подсети мы используем двоичное 001 для Ethernet и 010 для SLIP канала точка-точка.
Пример
Пример
Представьте себе адрес хоста 140.252.1.1 (адрес класса В), и маску подсети - 255.255.255.0 (8 бит на идентификатор подсети и 8 бит на идентификатор хоста). Если IP адрес назначения 140.252.4.5, мы знаем, что идентификатор сети класса В тот же самый (140.252), однако идентификатор подсети другой (1 и 4). На рисунке 3.8 показано, как происходит сравнение двух IP адресов с использованием маски подсети. Если IP адрес назначения 140.252.1.22, то идентификатор сети класса В тот же самый (140.252), и идентификатор подсети также тот же самый (1). Однако идентификатор хоста другой. Если IP адрес назначения 192.43.235.6 (адрес класса С), идентификатор сети другой. С этим адресом не может быть произведено дальнейшее сравнение.
Пример масок подсетей для двух различных подсетей класса B.
Рисунок 3.7 Пример масок подсетей для двух различных подсетей класса B.
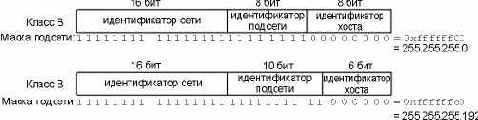
Несмотря на то, что IP адреса обычно пишутся в десятичном виде с точками, маски подсети, как правило, пишутся в шестнадцатиричном виде, особенно если разделение происходит не побайтно, а побитно.
После того как хост получил свой IP адрес и маску подсети, он может определить, предназначена ли IP датаграмма для (1) хоста в его собственной подсети, (2) хосту в другой подсети его собственной сети, или (3) хосту в другой сети. Зная собственный IP адрес, можно определить, к какому классу он относится: А, В или С (по старшим битам), также можно определить, где проведена граница между идентификатором сети и идентификатором подсети. По маске подсети можно определить где проведена граница между идентификатором подсети и идентификатором хоста.
Пример подсети
Пример подсети
В примере показаны подсети, использованные в тексте, а также, как используются две различные маски подсети.
Примеры
Примеры
Для начала представим себе простой пример: хост bsdi имеет IP датаграмму, которую необходимо послать на хост sun. Оба хоста находятся в одной и той же сети Ethernet (рисунок находится на внутренней стороне обложки). На рисунке 3.3 показан процесс доставки датаграммы.
Когда IP принимает датаграмму от одного из верхних уровней, он просматривает свою таблицу маршрутизации и определяет, что IP адрес назначения (140.252.13.33) непосредственно подключен к сети (Ethernet 140.252.13.0). В таблице маршрутизации найден совпадающий адрес сети (в следующем разделе мы увидим, что благодаря разбиению на подсети сетевой адрес этого Ethernet в действительности 140.252.13.32, однако это не влияет на маршрутизацию).
Датаграмма передается в драйвер устройства Ethernet и посылается на sun в виде Ethernet фрейма (рисунок 2.1). Адрес назначения в IP датаграмме это IP адрес Sun (140.252.13.33), а адрес назначения в заголовке канального уровня это 48-битовый Ethernet адрес интерфейса Ethernet машины sun. 48-битный Ethernet адрес получается с использованием ARP, как это делается - мы увидим в следующей главе.
Путь датаграммы от bsdi к ftp.uu.net (192.48.96.9).
Рисунок 3.4 Путь датаграммы от bsdi к ftp.uu.net (192.48.96.9).
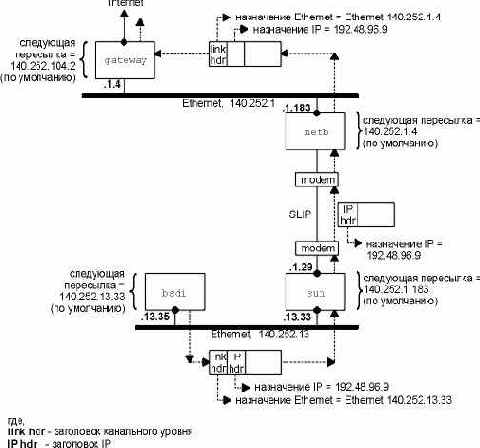
В главе 9 мы снова вернемся к IP маршрутизации, после того как расскажем об ICMP. Также мы рассмотрим некоторые примеры таблиц маршрутизации и примеры того, как они используются при принятии решений о маршрутизации.
Разделение на подсети адреса класса B.
Рисунок 3.5 Разделение на подсети адреса класса B.

Подобное разделение позволяет создать 254 подсети по 254 хоста в каждой.
Большинство администраторов использует 8 из 16-ти бит идентификатора хоста в сети класса В, для выделения подсетей. Это позволяет легко выделить идентификатор подсети из десятичного сетевого адреса, при этом для сетей класса А или класса В можно выделить различное количество битов для организации подсетей.
В большинстве примеров разделение на подсети осуществляется с адресами класса В. Поделить на подсети можно и адреса класса С, однако в этом случае на идентификатор подсети выделяется очень мало битов. Разделение на подсети очень редко применяется по отношению адресов класса А, потому что адресов класса А очень мало (однако, большинство адресов класса А поделено на подсети).
Разделение на подсети скрывает детали внутренней организации сети от внешних маршрутизаторов. В нашем примере, все IP адреса имеют идентификатор сети класса В - 140.252, однако в ней существует более чем 30 подсетей и более чем 400 хостов, распределенных по этим подсетям. Один маршрутизатор обеспечивает подключение к Internet, как показано на рисунке 3.6.
На этом рисунке мы пометили большинство маршрутизаторов как Rn, где n это номер подсети. Мы показали маршрутизаторы, которые соединяют эти подсети вместе с девятью системами, которые показаны на рисунке, находящимся на внутренней стороне обложки. Сети Ethernet показаны жирными линиями, а каналы точка-точка показаны пунктиром. Мы показали не все хосты, находящиеся в различных подсетях. Например, более 50 хостов находятся в подсети 140.252.3 и более 100 в подсети 140.252.1.
Преимущество использования подсети заключается в том, что используется один адрес класса В с 30 подсетями, а не 30 адресов класса С. При этом разделение на подсети уменьшает размер таблиц маршрутизации Internet. Факт того что адрес сети класса В 140.252 поделен на подсети говорит о том, что они прозрачны для всех маршрутизаторов Internet, кроме тех, которые находятся в подсети 140.252.
Рекомендованные значения поля типа сервиса (TOS).
Рисунок 3.2 Рекомендованные значения поля типа сервиса (TOS).
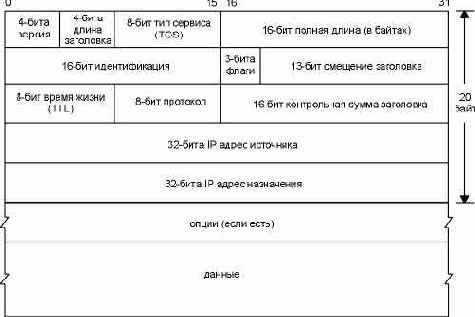
Диалоговые приложения, Telnet и Rlogin, требуют свести к минимуму задержку, так как они используются человеком интерактивно и осуществляют небольшую передачу данных. Передача файлов с использованием FTP, с другой стороны, требует максимальной пропускной способности. Максимальная надежность необходима для сетевого управления (SNMP) и для протоколов маршрутизации. Новости Usenet (NNTP) это единственное приложение, которое требует минимизации стоимости.
Характеристика TOS, в настоящее время, большинством реализаций TCP/IP не поддерживается, однако она включена в новые системы, начиная с 4.3BSD Reno. Некоторые протоколы маршрутизации, такие как OSPF и IS-IS, имеют возможность принимать решение о маршрутизации на основе этого поля.
В разделе "Вычисление загруженности последовательной линии" главы 2 мы упомянули, что драйверы SLIP обычно осуществляют построение очереди на основе типа сервиса, что позволяет диалоговому траффику обрабатываться перед передачей данных. Так как большинство реализаций не используют поле TOS, это построение очереди делается с помощью драйвера SLIP, который смотрит в поле протокола (для того чтобы определить, является ли данный сегмент TCP сегментом или нет) и затем проверяет номера портов TCP источника и назначения, чтобы определить, принадлежит ли этот номер диалоговому сервису.
Поле полной длины (total length) содержит полную длину IP датаграммы в байтах. Благодаря этому полю и полю длины заголовка, мы знаем, с какого места начинаются данные в IP датаграмме и их длину. Так как это поле состоит из 16 бит, максимальный размер IP датаграммы составляет 65535 байт. (Обратитесь к рисунку 2.5 и обратите внимание, что Hyperchannel имеет MTU, равный 65535. В действительности это не MTU - здесь используется максимально возможный размер IP датаграммы). Это поле изменяется в момент фрагментации и повторной сборки датаграммы, что будет описано в разделе "Фрагментация IP" главы 11.
Несмотря на то что существует возможность отправить датаграмму размером 65535 байт, большинство канальных уровней поделят подобную датаграмму на фрагменты. Более того, от хоста не требуется принимать датаграмму размером больше чем 576 байт. TCP делит пользовательские данные на части, поэтому это ограничение обычно не оказывает влияния на TCP. Что касается UDP, услугами которого пользуются многие приложения (RIP, TFTP, BOOTP, DNS, SNMP), то он ограничивает себя 512 байтами пользовательских данных, что даже меньше ограничения в 576 байт. Большинство приложений в настоящее время (особенно те, которые поддерживают NFS - Network File System) позволяют использовать IP датаграмму размером 8192 байта.
Однако, поле полной длины требуется в IP заголовке для некоторых каналов (как например, Ethernet), который дополняет маленькие фреймы до минимальной длины. Несмотря на то что минимальный размер фрейма Ethernet составляет 46 байт (рисунок 2.1), IP датаграмма может быть еще меньше. Если поле полной длины не было представлено, IP уровень не будет знать, сколько 46-байтных фреймов Ethernet получится из IP датаграммы.
Поле идентификации (identification) уникально идентифицирует каждую датаграмму, отправленную хостом. Значение, хранящееся в поле, обычно увеличивается на единицу с посылкой каждой датаграммы. Мы обратимся к этому полю, когда будем рассматривать фрагментацию и обратную сборку в разделе "Фрагментация IP" главы 11. Там же мы рассмотрим поле флагов (flags) и поле смещения фрагментации (fragmentation offset).
RFC 791 [Postel 1981a] сообщает, что поле идентификации должно быть выбрано верхним уровнем, который отправляет IP датаграммы, а это означает, что две последовательно отправленные IP датаграммы, одна из которых сгенерирована TCP, а другая - UDP, должны иметь одно и то же поле идентификации. Подобный подход работает (алгоритм сборки может обработать такую ситуацию). Однако, большинство реализаций, произошедших от Berkeley, увеличивают соответствующую переменную в ядре IP уровня каждый раз, когда отправляется IP датаграмма, вне зависимости от того какой уровень отправляет данные через IP. Переменная ядра инициируется каждый раз в момент загрузки системы.
Поле времени жизни (TTL - time-to-live) содержит максимальное количество пересылок (маршутизаторов), через которые может пройти датаграмма. Это поле ограничивает время жизни датаграммы. Значение устанавливается отправителем (как правило 32 или 64) и уменьшается на единицу каждым маршрутизатором, который обрабатывает датаграмму. Когда значение в поле достигает 0, датаграмма удаляется, а отправитель уведомляется об этом с помощью ICMP сообщения. Подобный алгоритм предотвращает зацикливание пакетов в петлях маршрутизации. Мы вернемся к этому полю в главе 8, когда будем рассматривать программу Traceroute.
Мы говорили о поле протокола (protocol) в главе 1 и показали на рисунке 1.8 как оно используется в IP для демультиплексирования входящих датаграмм. Это поле указывает, какой протокол отправил данные через IP.
Контрольная сумма заголовка (header checksum) рассчитывается только для IP заголовка. Она не включает в себя данные, которые следуют за заголовком. ICMP, IGMP, UDP и TCP имеют контрольные суммы в своих собственных заголовках, которые охватывают их заголовки и данные.
Чтобы рассчитать контрольную сумму IP для исходящей датаграммы, поле контрольной суммы сначала устанавливается в 0. Затем рассчитывается 16-битная сумма с поразрядным дополнением (One's complement - поразрядное дополнение к двоичной системе.) (заголовок целиком воспринимается как последовательность 16-битных слов). 16-битное поразрядное дополнение этой суммы сохраняется в поле контрольной суммы. Когда IP датаграмма принимается, вычисляется 16-битная сумма с поразрядным дополнением. Так как контрольная сумма, рассчитанная приемником, содержит в себе контрольную сумму, сохраненную отправителем, контрольная сумма приемника состоит из битов равных 1, если в заголовке ничего не было изменено при передаче. Если в результате не получились все единичные биты (ошибка контрольной суммы), IP отбрасывает принятую датаграмму. Сообщение об ошибке не генерируется. Теперь задача верхних уровней каким-либо образом определить, что датаграмма отсутствует, и обеспечить повторную передачу.
ICMP, IGMP, UDP и TCP используют такой же алгоритм расчета контрольной суммы. Также TCP и UDP включают в себя различные поля из IP заголовка, в дополнение к своим собственным заголовкам и данным. RFC 1071 [Braden, Borman, and Partridge 1988] описывает технику и реализацию расчета контрольной суммы Internet. Так как маршрутизаторы обычно изменяют только поле TTL (уменьшают его значение на единицу), маршрутизатор может просто увеличить на единицу контрольную сумму, когда он перенаправляет полученную датаграмму, вместо того чтобы рассчитывать контрольную сумму заново для IP заголовка в целом. RFC 1141 [Mallory and Kullberg 1990] описывает как этого можно добиться.
Стандартные реализации BSD, однако, не используют метод обновления контрольной суммы на единицу при перенаправлении датаграммы.
Каждая IP датаграмма содержит IP адрес источника (source IP address) и IP адрес назначения (destination IP address). Это 32-битные значения, которые мы описали в разделе "Адресация Internet" главы 1.
И последнее поле - поле опций (options), это список дополнительной информации переменной длины. В настоящее время опции определены следующим образом: безопасность и обработка ограничений (для военных приложений, описано в RFC 1108 [Kent 1991]), запись маршрута (запись каждого маршрута и его IP адрес, глава 7, раздел "Опция записи IP маршрута"), временная марка (запись каждого маршрута, его IP адрес и время, глава 7, раздел "IP опция временной марки"), свободная маршрутизация от источника (указывает список IP адресов, через которые должна пройти датаграмма, глава 8, раздел "Опция IP маршрутизации от источника"), и жесткая маршрутизация от источника (то же самое, что и в предыдущем пункте, однако IP датаграмма должна пройти только через указанные в списке адреса, глава 8, раздел "Опция IP маршрутизации от источника").
Эти опции редко используются и не все хосты или маршрутизаторы поддерживают все опции.
Поле опций всегда ограничено 32 битами. Байты заполнения, значение которых равно 0, добавляются по необходимости. Благодаря этому IP заголовок всегда кратен 32 битам (как это требуется для поля длины заголовка).
Специальные IP адреса
Специальные IP адреса
В процессе описания подсетей может встретится семь специальных IP адресов (см. рисунок 3.9). На этом рисунке 0 означает поле, состоящее из всех бит, установленных в ноль, -1 означает поле из бит, установленных в единицы, а netid (идентификатор сети), subnetid (идентификатор подсети) и hostid (идентификатор хоста) обозначает соответствующие поля, которые установлены не в единицы и не в нули. Пустая колонка идентификатора подсети означает, что адреса не могут быть разбиты на подсети.
| IP адрес | Может появляться как | Описание | |||
| ID сети | ID подсети | ID хоста | источник? | назначение? | |
| 0 | 0 | OK | никогда | этот хост в этой сети (см. ограничения ниже) | |
| 0 | hostid | OK | никогда | указывает хост в этой сети (см. ограничения ниже) | |
| 127 | любой | OK | OK | адрес loopback (см. раздел "Интерфейс Loopback" главы 2) | |
| -1 | -1 | никогда | OK | ограниченный широковещательный запрос (никогда не перенаправляется) | |
| netid | -1 | никогда | OK | широковещательный запрос, направляемый в сеть на netid | |
| netid | subnetid | -1 | никогда | OK | широковещательный запрос, направляемый в подсеть на netid, subnetid |
| netid | -1 | -1 | никогда | OK | широковещательный запрос, направляемый во все подсети на netid |
Специальные IP адреса.
Рисунок 3.9 Специальные IP адреса.
Мы разделили эту таблицу на три секции. Первые две записи содержат специальные адреса источников, затем адрес интерфейса loopback, и последние четыре записи - это широковещательные адреса.
Первые два пункта в таблице с идентификатором сети, равным 0, могут существовать только как адрес источника во время процедуры инициализации, когда хост определяет свой собственный IP адрес, например, с использованием протокола BOOTP (глава 16).
В разделе "Широковещательные запросы" главы 12 мы рассмотрим четыре типа широковещательных адресов более подробно.
Сравнение двух подсетей класса
Рисунок 3.8 Сравнение двух подсетей класса В, использующих маски подсети.

В процессе IP маршрутизации, сравнения, подобные этому, делаются все время с использованием двух IP адресов и маски подсети.
Упражнения
Упражнения
Должен ли быть адрес интерфейса loopback всегда 127.0.0.1? На рисунке 3.6 определите маршрутизаторы, которые имеют больше двух интерфейсов. В чем отличие маски подсети для адреса класса А с 16 битами для идентификатора подсети и адреса класса В с 8 битами для адреса подсети? Прочитайте RFC 1219 [Tsuchiya 1991], для того чтобы познакомиться с рекомендуемой технологией назначения идентификаторов подсетей и идентификаторов хостов. Можно ли использовать маску подсети 255.255.0.255 для адресов класса А? Почему MTU для интерфейса loopback, показанного в разделе "Команда netstat", установлен в 1536? Семейство протоколов TCP/IP построено на основе уровня IP, который определяет технологию передачи датаграмм по сети. Существуют семейства протоколов, которые основаны на применении сетевых технологий, ориентированных на соединения. Прочитайте [Clark 1988], чтобы найти три преимущества сетей с передачей датаграмм. Назад
Компания | Услуги | Для клиентов | Библиотека | Галерея | Cофт | Линки
На главную
Введение
Введение
IP это рабочая лошадь семейства протоколов TCP/IP. TCP, UDP, ICMP и IGMP передают свои данные как IP датаграммы (рисунок 1.4). Один факт часто удивляет новичков TCP/IP, особенно тех кто работал с X.25 или SNA, этот факт заключается в том, что IP ненадежный протокол, предоставляющий сервис доставки датаграмм без соединения.
Под словом ненадежный мы подразумеваем то, что не существует гарантии того, что IP датаграмма успешно достигнет пункта назначения. Однако IP предоставляет определенный сервис обработки некоторых событий. Когда что-нибудь идет не так как хотелось бы, как например, временное переполнение буфера у маршрутизатора, IP применяет простой алгоритм обработки ошибок: он отбрасывает датаграмму и старается послать ICMP сообщение отправителю. Любая требуемая надежность должна быть обеспечена верхними уровнями (например TCP).
Термин без соединения (connectionless) означает, что IP не содержит никакой информации о продвижении датаграмм. Каждая датаграмма обрабатывается независимо от других. Это также означает, что может быть доставлена испорченная датаграмма. Если источник отправляет две последовательные датаграммы (первая A, затем B) в один и то же пункт назначения, каждая из них маршрутизируется независимо и может пройти по разным маршрутам, датаграмма B может прибыть раньше чем A.
В этой главе мы кратко рассмотрим поля IP заголовка, опишем IP маршрутизацию и коротко опишем разделение на подсети. Также мы рассмотрим две очень полезные команды: ifconfig и netstat. Более подробно некоторые поля IP заголовка будут описаны в следующих главах. Именно тогда мы точно расскажем, как используются те или иные поля. RFC 791 [Postel 1981a] является официальной спецификацией для IP.